Geometry-aware Reconstruction and Fusion-refined Rendering for Generalizable Neural Radiance Fields
2404.17528
0
0
🧠
Abstract
Generalizable NeRF aims to synthesize novel views for unseen scenes. Common practices involve constructing variance-based cost volumes for geometry reconstruction and encoding 3D descriptors for decoding novel views. However, existing methods show limited generalization ability in challenging conditions due to inaccurate geometry, sub-optimal descriptors, and decoding strategies. We address these issues point by point. First, we find the variance-based cost volume exhibits failure patterns as the features of pixels corresponding to the same point can be inconsistent across different views due to occlusions or reflections. We introduce an Adaptive Cost Aggregation (ACA) approach to amplify the contribution of consistent pixel pairs and suppress inconsistent ones. Unlike previous methods that solely fuse 2D features into descriptors, our approach introduces a Spatial-View Aggregator (SVA) to incorporate 3D context into descriptors through spatial and inter-view interaction. When decoding the descriptors, we observe the two existing decoding strategies excel in different areas, which are complementary. A Consistency-Aware Fusion (CAF) strategy is proposed to leverage the advantages of both. We incorporate the above ACA, SVA, and CAF into a coarse-to-fine framework, termed Geometry-aware Reconstruction and Fusion-refined Rendering (GeFu). GeFu attains state-of-the-art performance across multiple datasets. Code is available at https://github.com/TQTQliu/GeFu .
Get summaries of the top AI research delivered straight to your inbox:
Overview
- The paper introduces a new method called GeFu that aims to improve the generalization ability of Neural Radiance Field (NeRF) models for novel view synthesis.
- GeFu addresses key limitations of existing approaches, such as inaccurate geometry, sub-optimal descriptors, and inefficient decoding strategies.
- The method incorporates three key components: Adaptive Cost Aggregation (ACA), Spatial-View Aggregator (SVA), and Consistency-Aware Fusion (CAF).
Plain English Explanation
NeRF models are used to generate novel views of a scene by learning a 3D representation from a set of input images. GeFu aims to make these models more generalizable, meaning they can better handle challenging conditions like occlusions and reflections.
The key issues GeFu addresses are:
- Inaccurate geometry: Existing methods use a variance-based cost volume to reconstruct the scene geometry, but this can fail when features of the same point are inconsistent across different views.
- Sub-optimal descriptors: Previous approaches only fuse 2D features into descriptors, missing important 3D context.
- Inefficient decoding: Existing decoding strategies excel in different areas, and GeFu proposes a way to leverage the advantages of both.
To address these problems, GeFu incorporates three main components:
- Adaptive Cost Aggregation (ACA): This amplifies the contribution of consistent pixel pairs and suppresses inconsistent ones, improving the geometry reconstruction.
- Spatial-View Aggregator (SVA): This incorporates 3D context into the descriptors by considering spatial and inter-view interactions.
- Consistency-Aware Fusion (CAF): This leverages the complementary strengths of the two existing decoding strategies.
By combining these components, GeFu is able to achieve state-of-the-art performance on multiple datasets for novel view synthesis.
Technical Explanation
The key technical innovations in GeFu are:
-
Adaptive Cost Aggregation (ACA): The paper notes that the variance-based cost volume used in previous methods can fail when the features of pixels corresponding to the same 3D point are inconsistent across different views, such as due to occlusions or reflections. GeFu's ACA approach amplifies the contribution of consistent pixel pairs and suppresses inconsistent ones, improving the geometry reconstruction.
-
Spatial-View Aggregator (SVA): Unlike previous methods that only fuse 2D features into descriptors, GeFu's SVA incorporates 3D context by considering spatial and inter-view interactions. This helps create more robust and informative descriptors for decoding novel views.
-
Consistency-Aware Fusion (CAF): The paper observes that the two existing decoding strategies (depth-based and feature-based) excel in different areas and are complementary. GeFu's CAF leverages the advantages of both by fusing their outputs in a consistency-aware manner.
GeFu integrates these three components into a coarse-to-fine framework for geometry-aware reconstruction and fusion-refined rendering. This combined approach enables state-of-the-art performance on multiple benchmarks for novel view synthesis tasks.
Critical Analysis
The paper presents a well-designed and comprehensive solution to address the limitations of existing NeRF approaches for novel view synthesis. The key innovations, such as ACA, SVA, and CAF, are well-motivated and appear to be effective based on the reported results.
One potential concern is the computational complexity of the proposed method, as the additional components may increase the overall runtime compared to simpler NeRF models. The authors do not provide detailed information about the runtime or memory footprint of GeFu, which could be an important consideration for practical applications.
Additionally, the paper focuses on improving the generalization ability of NeRF models, but it would be interesting to see how GeFu performs in other challenging scenarios, such as scenes with significant occlusions, reflections, or dynamic elements. Evaluating the method's robustness to these types of conditions could further demonstrate its advantages over existing approaches.
Overall, the GeFu method represents a promising step forward in enhancing the capabilities of NeRF models for novel view synthesis. The technical innovations and strong empirical results suggest that the proposed approach could be a valuable contribution to the field of 3D scene reconstruction and rendering.
Conclusion
The GeFu method addresses key limitations of existing NeRF approaches for novel view synthesis, including inaccurate geometry reconstruction, sub-optimal descriptors, and inefficient decoding strategies. By incorporating Adaptive Cost Aggregation, Spatial-View Aggregator, and Consistency-Aware Fusion, GeFu is able to achieve state-of-the-art performance on multiple datasets.
This work represents an important advancement in improving the generalization ability of NeRF models, which could have significant implications for a wide range of applications, such as virtual reality, augmented reality, and 3D content creation. Further research to explore the method's robustness in challenging scenarios and optimize its computational efficiency could help unlock even greater potential for this technology.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
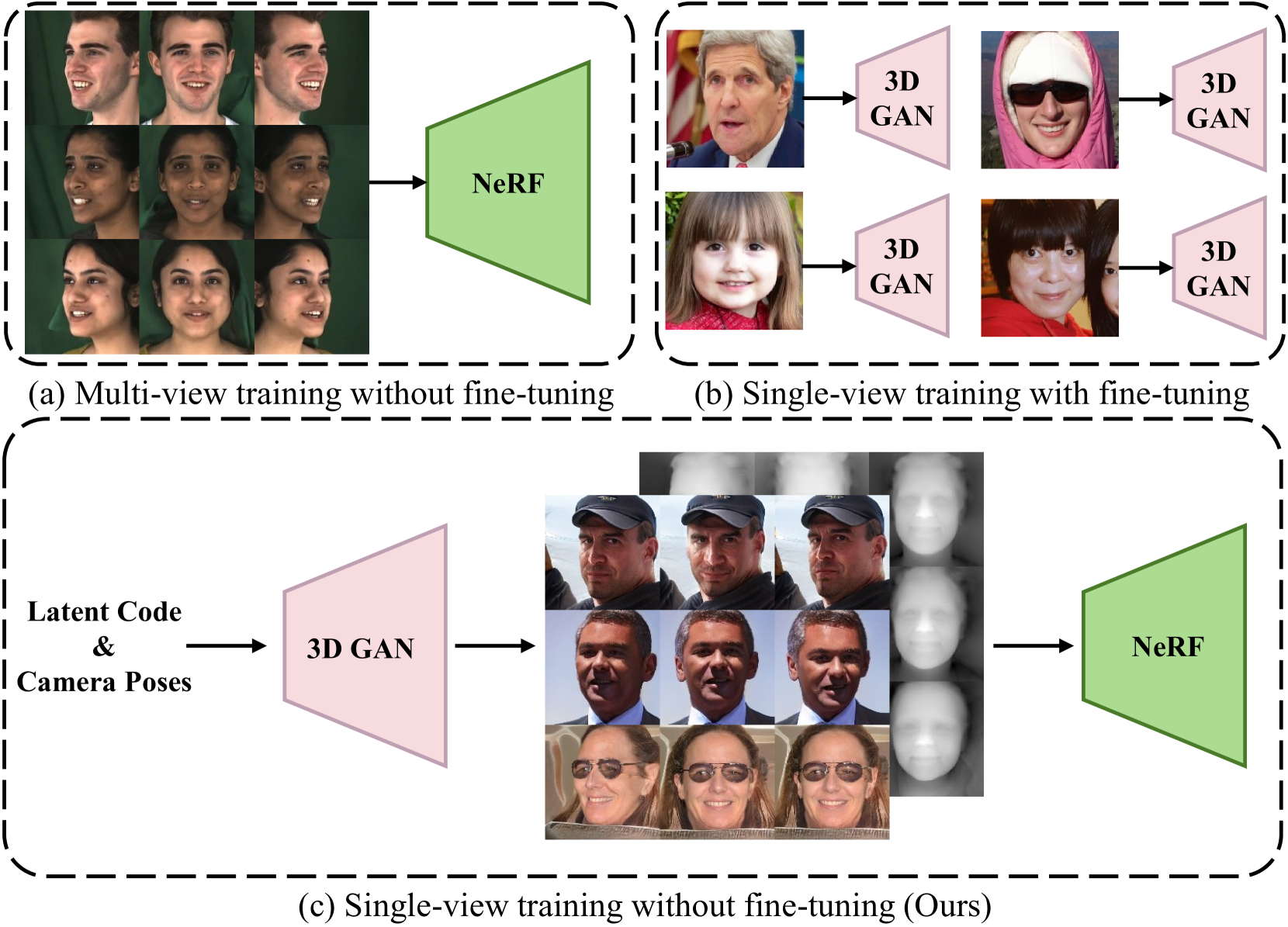
G-NeRF: Geometry-enhanced Novel View Synthesis from Single-View Images
Zixiong Huang, Qi Chen, Libo Sun, Yifan Yang, Naizhou Wang, Mingkui Tan, Qi Wu
0
0
Novel view synthesis aims to generate new view images of a given view image collection. Recent attempts address this problem relying on 3D geometry priors (e.g., shapes, sizes, and positions) learned from multi-view images. However, such methods encounter the following limitations: 1) they require a set of multi-view images as training data for a specific scene (e.g., face, car or chair), which is often unavailable in many real-world scenarios; 2) they fail to extract the geometry priors from single-view images due to the lack of multi-view supervision. In this paper, we propose a Geometry-enhanced NeRF (G-NeRF), which seeks to enhance the geometry priors by a geometry-guided multi-view synthesis approach, followed by a depth-aware training. In the synthesis process, inspired that existing 3D GAN models can unconditionally synthesize high-fidelity multi-view images, we seek to adopt off-the-shelf 3D GAN models, such as EG3D, as a free source to provide geometry priors through synthesizing multi-view data. Simultaneously, to further improve the geometry quality of the synthetic data, we introduce a truncation method to effectively sample latent codes within 3D GAN models. To tackle the absence of multi-view supervision for single-view images, we design the depth-aware training approach, incorporating a depth-aware discriminator to guide geometry priors through depth maps. Experiments demonstrate the effectiveness of our method in terms of both qualitative and quantitative results.
4/12/2024
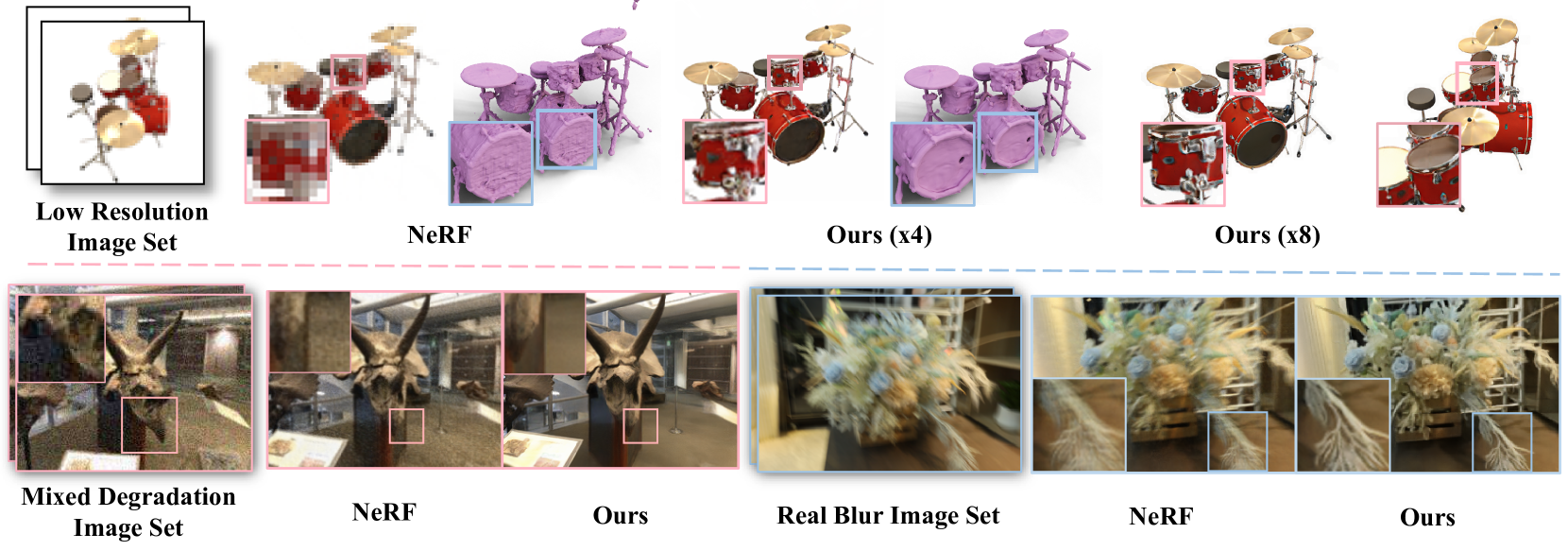
RaFE: Generative Radiance Fields Restoration
Zhongkai Wu, Ziyu Wan, Jing Zhang, Jing Liao, Dong Xu
0
0
NeRF (Neural Radiance Fields) has demonstrated tremendous potential in novel view synthesis and 3D reconstruction, but its performance is sensitive to input image quality, which struggles to achieve high-fidelity rendering when provided with low-quality sparse input viewpoints. Previous methods for NeRF restoration are tailored for specific degradation type, ignoring the generality of restoration. To overcome this limitation, we propose a generic radiance fields restoration pipeline, named RaFE, which applies to various types of degradations, such as low resolution, blurriness, noise, compression artifacts, or their combinations. Our approach leverages the success of off-the-shelf 2D restoration methods to recover the multi-view images individually. Instead of reconstructing a blurred NeRF by averaging inconsistencies, we introduce a novel approach using Generative Adversarial Networks (GANs) for NeRF generation to better accommodate the geometric and appearance inconsistencies present in the multi-view images. Specifically, we adopt a two-level tri-plane architecture, where the coarse level remains fixed to represent the low-quality NeRF, and a fine-level residual tri-plane to be added to the coarse level is modeled as a distribution with GAN to capture potential variations in restoration. We validate RaFE on both synthetic and real cases for various restoration tasks, demonstrating superior performance in both quantitative and qualitative evaluations, surpassing other 3D restoration methods specific to single task. Please see our project website https://zkaiwu.github.io/RaFE-Project/.
4/9/2024
👨🏫
Depth Supervised Neural Surface Reconstruction from Airborne Imagery
Vincent Hackstein, Paul Fauth-Mayer, Matthias Rothermel, Norbert Haala
0
0
While originally developed for novel view synthesis, Neural Radiance Fields (NeRFs) have recently emerged as an alternative to multi-view stereo (MVS). Triggered by a manifold of research activities, promising results have been gained especially for texture-less, transparent, and reflecting surfaces, while such scenarios remain challenging for traditional MVS-based approaches. However, most of these investigations focus on close-range scenarios, with studies for airborne scenarios still missing. For this task, NeRFs face potential difficulties at areas of low image redundancy and weak data evidence, as often found in street canyons, facades or building shadows. Furthermore, training such networks is computationally expensive. Thus, the aim of our work is twofold: First, we investigate the applicability of NeRFs for aerial image blocks representing different characteristics like nadir-only, oblique and high-resolution imagery. Second, during these investigations we demonstrate the benefit of integrating depth priors from tie-point measures, which are provided during presupposed Bundle Block Adjustment. Our work is based on the state-of-the-art framework VolSDF, which models 3D scenes by signed distance functions (SDFs), since this is more applicable for surface reconstruction compared to the standard volumetric representation in vanilla NeRFs. For evaluation, the NeRF-based reconstructions are compared to results of a publicly available benchmark dataset for airborne images.
4/26/2024
🤔
GP-NeRF: Generalized Perception NeRF for Context-Aware 3D Scene Understanding
Hao Li, Dingwen Zhang, Yalun Dai, Nian Liu, Lechao Cheng, Jingfeng Li, Jingdong Wang, Junwei Han
0
0
Applying NeRF to downstream perception tasks for scene understanding and representation is becoming increasingly popular. Most existing methods treat semantic prediction as an additional rendering task, textit{i.e.}, the label rendering task, to build semantic NeRFs. However, by rendering semantic/instance labels per pixel without considering the contextual information of the rendered image, these methods usually suffer from unclear boundary segmentation and abnormal segmentation of pixels within an object. To solve this problem, we propose Generalized Perception NeRF (GP-NeRF), a novel pipeline that makes the widely used segmentation model and NeRF work compatibly under a unified framework, for facilitating context-aware 3D scene perception. To accomplish this goal, we introduce transformers to aggregate radiance as well as semantic embedding fields jointly for novel views and facilitate the joint volumetric rendering of both fields. In addition, we propose two self-distillation mechanisms, i.e., the Semantic Distill Loss and the Depth-Guided Semantic Distill Loss, to enhance the discrimination and quality of the semantic field and the maintenance of geometric consistency. In evaluation, we conduct experimental comparisons under two perception tasks (textit{i.e.} semantic and instance segmentation) using both synthetic and real-world datasets. Notably, our method outperforms SOTA approaches by 6.94%, 11.76%, and 8.47% on generalized semantic segmentation, finetuning semantic segmentation, and instance segmentation, respectively.
4/9/2024