G-NeRF: Geometry-enhanced Novel View Synthesis from Single-View Images
2404.07474
0
0
Abstract
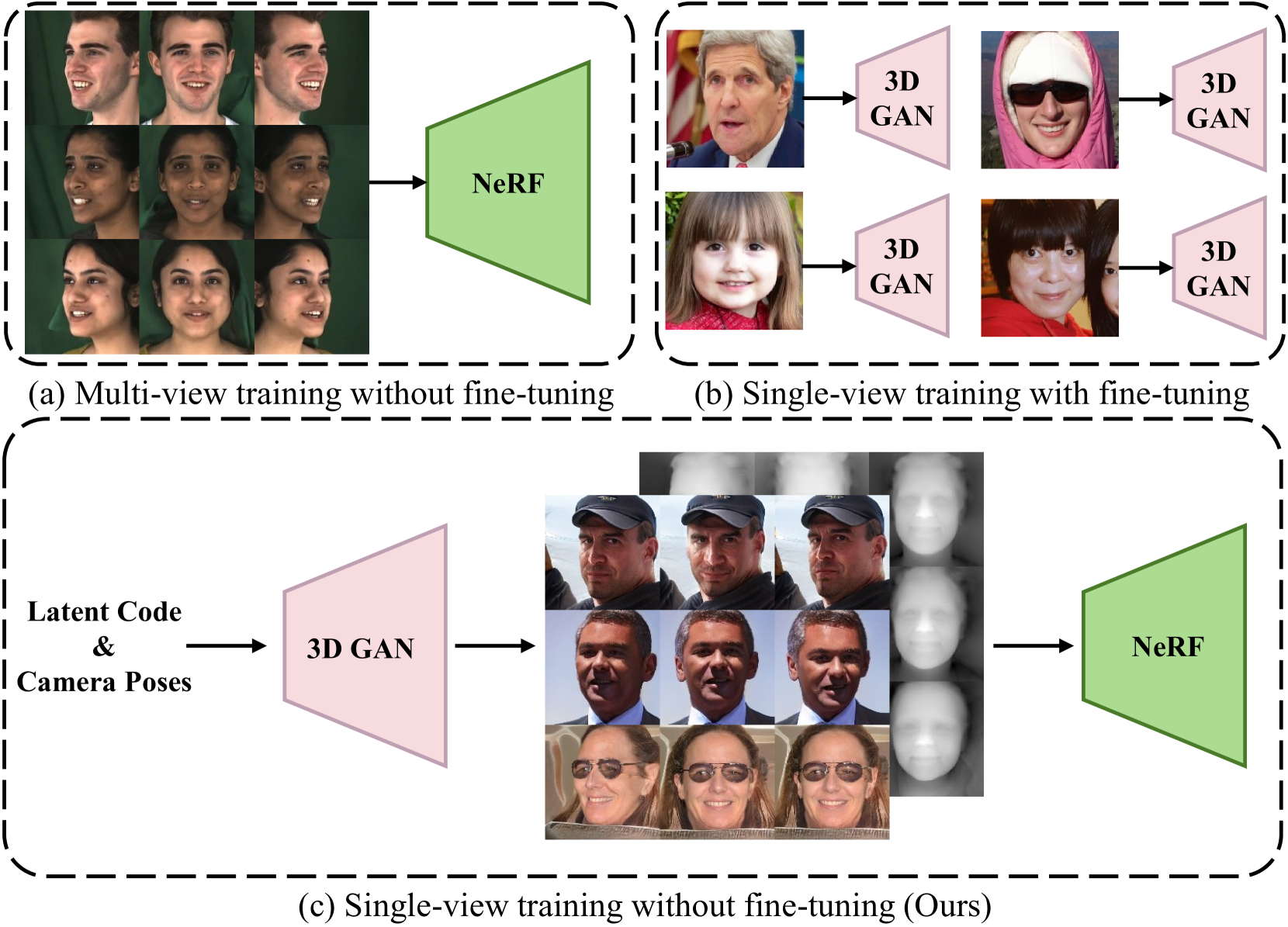
Novel view synthesis aims to generate new view images of a given view image collection. Recent attempts address this problem relying on 3D geometry priors (e.g., shapes, sizes, and positions) learned from multi-view images. However, such methods encounter the following limitations: 1) they require a set of multi-view images as training data for a specific scene (e.g., face, car or chair), which is often unavailable in many real-world scenarios; 2) they fail to extract the geometry priors from single-view images due to the lack of multi-view supervision. In this paper, we propose a Geometry-enhanced NeRF (G-NeRF), which seeks to enhance the geometry priors by a geometry-guided multi-view synthesis approach, followed by a depth-aware training. In the synthesis process, inspired that existing 3D GAN models can unconditionally synthesize high-fidelity multi-view images, we seek to adopt off-the-shelf 3D GAN models, such as EG3D, as a free source to provide geometry priors through synthesizing multi-view data. Simultaneously, to further improve the geometry quality of the synthetic data, we introduce a truncation method to effectively sample latent codes within 3D GAN models. To tackle the absence of multi-view supervision for single-view images, we design the depth-aware training approach, incorporating a depth-aware discriminator to guide geometry priors through depth maps. Experiments demonstrate the effectiveness of our method in terms of both qualitative and quantitative results.
Create account to get full access
Overview
• This paper introduces G-NeRF, a novel approach for geometry-enhanced novel view synthesis from single-view images. • G-NeRF combines the strengths of neural radiance fields (NeRF) and geometry estimation to enable high-quality novel view synthesis from a single input image. • The key idea is to leverage geometric cues extracted from the input image to guide the NeRF optimization, leading to more accurate and efficient reconstruction.
Plain English Explanation
• G-NeRF: Geometry-enhanced Novel View Synthesis from Single-View Images is a new technique for creating 3D models and animations from a single photograph. • Traditional methods for this task, like NeRF, can produce high-quality results but require many input images. G-NeRF uses a clever trick to get good results from just one image. • The key idea is to first estimate the 3D geometry of the scene from the single input image. This 3D information is then used to guide and constrain the NeRF optimization process, leading to more accurate and efficient 3D reconstruction. • By combining geometry estimation and NeRF, G-NeRF can create detailed 3D models and animations from a single photograph, without needing a large dataset of input images like other methods (Unifying Correspondence and Pose with NeRF for Pose-Free Novel View Synthesis, SGD: Street-View Synthesis via Gaussian Splatting and Diffusion).
Technical Explanation
• G-NeRF builds on the neural radiance field (NeRF) framework, which represents a 3D scene as a continuous function mapping 3D coordinates to color and volume density. • The key innovation in G-NeRF is the incorporation of geometric cues extracted from the input image to guide the NeRF optimization. • Specifically, G-NeRF first estimates the 3D geometry of the scene using a depth estimation network. This estimated depth map is then used to constrain the NeRF optimization, ensuring the reconstructed 3D geometry aligns with the observed image. • The authors show that this geometry-aware NeRF optimization leads to more accurate and efficient reconstruction compared to standard NeRF, especially when only a single input image is available.
Critical Analysis
• The main limitation of G-NeRF is that it still relies on depth estimation from a single image, which can be challenging and error-prone, especially for complex or occluded scenes. • The authors acknowledge this limitation and suggest that incorporating additional geometric cues, such as surface normals or segmentation, could further improve the performance of G-NeRF. • Another potential issue is the computational complexity of the G-NeRF pipeline, which includes both depth estimation and NeRF optimization. This may limit the real-world applicability of the method, especially for time-sensitive applications. • Despite these limitations, G-NeRF represents a promising step towards more efficient and accurate single-view 3D reconstruction, with potential applications in areas like Plato's Cave via Single-View 3D Reconstruction.
Conclusion
• G-NeRF introduces a novel approach for geometry-enhanced novel view synthesis from single-view images, leveraging the strengths of both depth estimation and neural radiance fields. • By incorporating geometric cues extracted from the input image, G-NeRF can produce high-quality 3D reconstructions and novel views from a single photograph, outperforming standard NeRF. • While the method has some limitations, G-NeRF demonstrates the potential of combining geometry and neural rendering techniques for efficient and accurate 3D reconstruction from limited data, with promising applications in areas like virtual and augmented reality.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Generalizable Novel-View Synthesis using a Stereo Camera
Haechan Lee, Wonjoon Jin, Seung-Hwan Baek, Sunghyun Cho
0
0
In this paper, we propose the first generalizable view synthesis approach that specifically targets multi-view stereo-camera images. Since recent stereo matching has demonstrated accurate geometry prediction, we introduce stereo matching into novel-view synthesis for high-quality geometry reconstruction. To this end, this paper proposes a novel framework, dubbed StereoNeRF, which integrates stereo matching into a NeRF-based generalizable view synthesis approach. StereoNeRF is equipped with three key components to effectively exploit stereo matching in novel-view synthesis: a stereo feature extractor, a depth-guided plane-sweeping, and a stereo depth loss. Moreover, we propose the StereoNVS dataset, the first multi-view dataset of stereo-camera images, encompassing a wide variety of both real and synthetic scenes. Our experimental results demonstrate that StereoNeRF surpasses previous approaches in generalizable view synthesis.
4/23/2024
🧠
ID-NeRF: Indirect Diffusion-guided Neural Radiance Fields for Generalizable View Synthesis
Yaokun Li, Chao Gou, Guang Tan
0
0
Implicit neural representations, represented by Neural Radiance Fields (NeRF), have dominated research in 3D computer vision by virtue of high-quality visual results and data-driven benefits. However, their realistic applications are hindered by the need for dense inputs and per-scene optimization. To solve this problem, previous methods implement generalizable NeRFs by extracting local features from sparse inputs as conditions for the NeRF decoder. However, although this way can allow feed-forward reconstruction, they suffer from the inherent drawback of yielding sub-optimal results caused by erroneous reprojected features. In this paper, we focus on this problem and aim to address it by introducing pre-trained generative priors to enable high-quality generalizable novel view synthesis. Specifically, we propose a novel Indirect Diffusion-guided NeRF framework, termed ID-NeRF, which leverages pre-trained diffusion priors as a guide for the reprojected features created by the previous paradigm. Notably, to enable 3D-consistent predictions, the proposed ID-NeRF discards the way of direct supervision commonly used in prior 3D generative models and instead adopts a novel indirect prior injection strategy. This strategy is implemented by distilling pre-trained knowledge into an imaginative latent space via score-based distillation, and an attention-based refinement module is then proposed to leverage the embedded priors to improve reprojected features extracted from sparse inputs. We conduct extensive experiments on multiple datasets to evaluate our method, and the results demonstrate the effectiveness of our method in synthesizing novel views in a generalizable manner, especially in sparse settings.
5/28/2024

Generative Lifting of Multiview to 3D from Unknown Pose: Wrapping NeRF inside Diffusion
Xin Yuan, Rana Hanocka, Michael Maire
0
0
We cast multiview reconstruction from unknown pose as a generative modeling problem. From a collection of unannotated 2D images of a scene, our approach simultaneously learns both a network to predict camera pose from 2D image input, as well as the parameters of a Neural Radiance Field (NeRF) for the 3D scene. To drive learning, we wrap both the pose prediction network and NeRF inside a Denoising Diffusion Probabilistic Model (DDPM) and train the system via the standard denoising objective. Our framework requires the system accomplish the task of denoising an input 2D image by predicting its pose and rendering the NeRF from that pose. Learning to denoise thus forces the system to concurrently learn the underlying 3D NeRF representation and a mapping from images to camera extrinsic parameters. To facilitate the latter, we design a custom network architecture to represent pose as a distribution, granting implicit capacity for discovering view correspondences when trained end-to-end for denoising alone. This technique allows our system to successfully build NeRFs, without pose knowledge, for challenging scenes where competing methods fail. At the conclusion of training, our learned NeRF can be extracted and used as a 3D scene model; our full system can be used to sample novel camera poses and generate novel-view images.
6/12/2024
🧠
Geometry-aware Reconstruction and Fusion-refined Rendering for Generalizable Neural Radiance Fields
Tianqi Liu, Xinyi Ye, Min Shi, Zihao Huang, Zhiyu Pan, Zhan Peng, Zhiguo Cao
0
0
Generalizable NeRF aims to synthesize novel views for unseen scenes. Common practices involve constructing variance-based cost volumes for geometry reconstruction and encoding 3D descriptors for decoding novel views. However, existing methods show limited generalization ability in challenging conditions due to inaccurate geometry, sub-optimal descriptors, and decoding strategies. We address these issues point by point. First, we find the variance-based cost volume exhibits failure patterns as the features of pixels corresponding to the same point can be inconsistent across different views due to occlusions or reflections. We introduce an Adaptive Cost Aggregation (ACA) approach to amplify the contribution of consistent pixel pairs and suppress inconsistent ones. Unlike previous methods that solely fuse 2D features into descriptors, our approach introduces a Spatial-View Aggregator (SVA) to incorporate 3D context into descriptors through spatial and inter-view interaction. When decoding the descriptors, we observe the two existing decoding strategies excel in different areas, which are complementary. A Consistency-Aware Fusion (CAF) strategy is proposed to leverage the advantages of both. We incorporate the above ACA, SVA, and CAF into a coarse-to-fine framework, termed Geometry-aware Reconstruction and Fusion-refined Rendering (GeFu). GeFu attains state-of-the-art performance across multiple datasets. Code is available at https://github.com/TQTQliu/GeFu .
4/29/2024