GFlow: Recovering 4D World from Monocular Video
2405.18426
0
0

Abstract
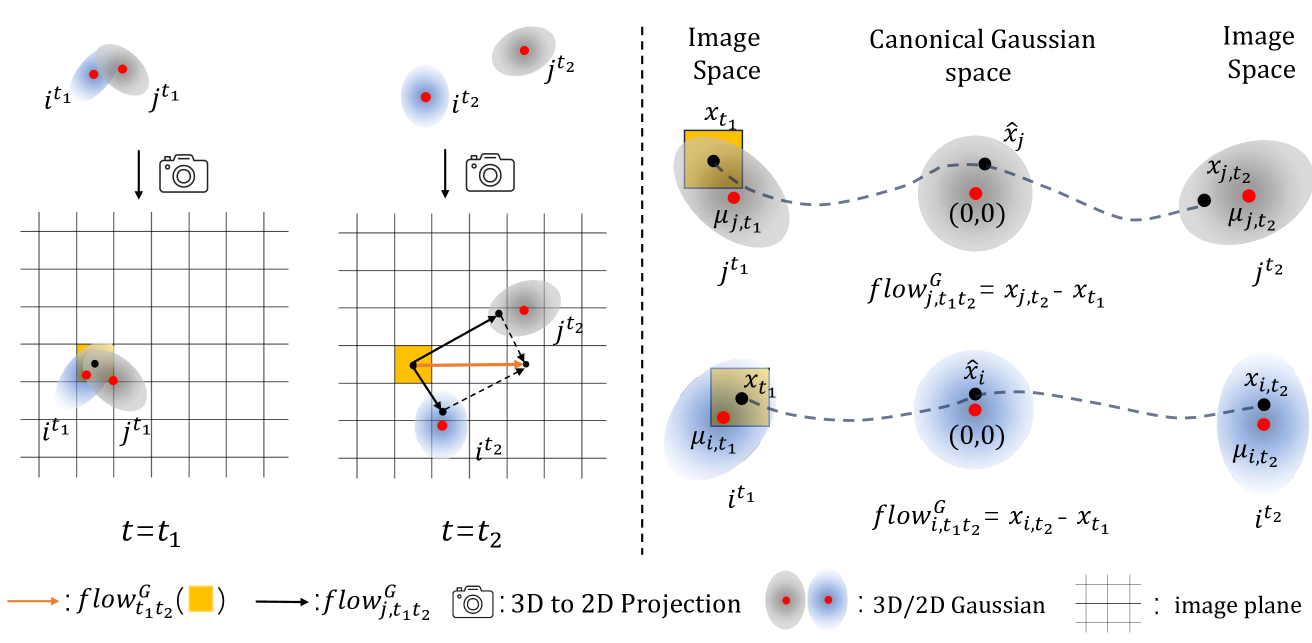
Reconstructing 4D scenes from video inputs is a crucial yet challenging task. Conventional methods usually rely on the assumptions of multi-view video inputs, known camera parameters, or static scenes, all of which are typically absent under in-the-wild scenarios. In this paper, we relax all these constraints and tackle a highly ambitious but practical task, which we termed as AnyV4D: we assume only one monocular video is available without any camera parameters as input, and we aim to recover the dynamic 4D world alongside the camera poses. To this end, we introduce GFlow, a new framework that utilizes only 2D priors (depth and optical flow) to lift a video (3D) to a 4D explicit representation, entailing a flow of Gaussian splatting through space and time. GFlow first clusters the scene into still and moving parts, then applies a sequential optimization process that optimizes camera poses and the dynamics of 3D Gaussian points based on 2D priors and scene clustering, ensuring fidelity among neighboring points and smooth movement across frames. Since dynamic scenes always introduce new content, we also propose a new pixel-wise densification strategy for Gaussian points to integrate new visual content. Moreover, GFlow transcends the boundaries of mere 4D reconstruction; it also enables tracking of any points across frames without the need for prior training and segments moving objects from the scene in an unsupervised way. Additionally, the camera poses of each frame can be derived from GFlow, allowing for rendering novel views of a video scene through changing camera pose. By employing the explicit representation, we may readily conduct scene-level or object-level editing as desired, underscoring its versatility and power. Visit our project website at: https://littlepure2333.github.io/GFlow
Create account to get full access
Overview
- This paper introduces GFlow, a method for recovering a 4D (3D + time) representation of the world from a monocular video input.
- GFlow uses a generative model to predict the future motion and dynamics of objects and scenes, enabling the creation of high-quality 4D content from a single camera.
- The paper builds upon prior work in Gaussian Flow, Generative Camera Dolly, Guess Unseen, and DreamScene4D.
Plain English Explanation
GFlow is a system that can take a video recorded with a single camera and use that information to create a detailed 3D model of the scene that also includes how the scene changes over time. This allows you to do things like view the scene from different angles or see how it evolves, even though you only had a single video recording to work with.
The key idea behind GFlow is to use a machine learning model that can "predict" how the scene will change and move in the future, based on the initial video. This allows GFlow to fill in the gaps and generate a full 4D (3D + time) representation of the scene, even though the original input was just a flat 2D video.
This technology could be really useful for a variety of applications, like creating visual effects for movies, generating 3D models for virtual reality experiences, or even just allowing you to explore a recorded scene in new ways. By starting with a simple video, GFlow can create much richer and more interactive 3D content.
Technical Explanation
The core of GFlow is a generative model that can predict the future motion and dynamics of objects and scenes from a monocular video input. Building on prior work like Gaussian Flow, Generative Camera Dolly, Guess Unseen, and DreamScene4D, the authors develop a neural network architecture that can take a single video frame as input and generate a probabilistic 4D representation of the scene.
This 4D representation includes both the 3D geometry of the scene and how that geometry changes over time. The key innovation is the use of a latent Gaussian flow model, which allows the system to efficiently capture the complex, high-dimensional dynamics of the scene.
The authors evaluate GFlow on a variety of benchmark datasets, demonstrating its ability to generate high-quality 4D content from monocular video inputs. They show that GFlow outperforms previous state-of-the-art methods in terms of both visual quality and downstream task performance, such as novel view synthesis and 3D object tracking.
Critical Analysis
One potential limitation of GFlow is that it relies on the availability of high-quality training data, which may not always be easy to obtain. The authors mention that their system works best on scenes with relatively simple dynamics, and it may struggle with more complex or cluttered environments.
Additionally, while GFlow can generate plausible 4D content, it does not necessarily guarantee that the generated content will be completely faithful to the original scene. There may be some artifacts or inconsistencies introduced by the generative model, which could limit its usefulness in certain applications that require high fidelity.
It would also be interesting to see how GFlow performs on real-world, unconstrained videos, as the paper focuses primarily on evaluating the system on synthetic or curated datasets. Extending the method to handle the noise, occlusions, and other challenges of real-world video data could be an important next step.
Conclusion
Overall, GFlow represents an exciting advancement in the field of 4D scene reconstruction from monocular video. By leveraging a powerful generative model, the system can create rich, dynamic 3D representations of the world from a single camera feed. This technology has the potential to enable a wide range of applications, from visual effects to virtual reality, and could significantly impact how we capture, interact with, and understand the 3D world around us.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
GaussianFlow: Splatting Gaussian Dynamics for 4D Content Creation
Quankai Gao, Qiangeng Xu, Zhe Cao, Ben Mildenhall, Wenchao Ma, Le Chen, Danhang Tang, Ulrich Neumann
0
0
Creating 4D fields of Gaussian Splatting from images or videos is a challenging task due to its under-constrained nature. While the optimization can draw photometric reference from the input videos or be regulated by generative models, directly supervising Gaussian motions remains underexplored. In this paper, we introduce a novel concept, Gaussian flow, which connects the dynamics of 3D Gaussians and pixel velocities between consecutive frames. The Gaussian flow can be efficiently obtained by splatting Gaussian dynamics into the image space. This differentiable process enables direct dynamic supervision from optical flow. Our method significantly benefits 4D dynamic content generation and 4D novel view synthesis with Gaussian Splatting, especially for contents with rich motions that are hard to be handled by existing methods. The common color drifting issue that happens in 4D generation is also resolved with improved Guassian dynamics. Superior visual quality on extensive experiments demonstrates our method's effectiveness. Quantitative and qualitative evaluations show that our method achieves state-of-the-art results on both tasks of 4D generation and 4D novel view synthesis. Project page: https://zerg-overmind.github.io/GaussianFlow.github.io/
5/15/2024
💬
Generative Camera Dolly: Extreme Monocular Dynamic Novel View Synthesis
Basile Van Hoorick, Rundi Wu, Ege Ozguroglu, Kyle Sargent, Ruoshi Liu, Pavel Tokmakov, Achal Dave, Changxi Zheng, Carl Vondrick
0
0
Accurate reconstruction of complex dynamic scenes from just a single viewpoint continues to be a challenging task in computer vision. Current dynamic novel view synthesis methods typically require videos from many different camera viewpoints, necessitating careful recording setups, and significantly restricting their utility in the wild as well as in terms of embodied AI applications. In this paper, we propose $textbf{GCD}$, a controllable monocular dynamic view synthesis pipeline that leverages large-scale diffusion priors to, given a video of any scene, generate a synchronous video from any other chosen perspective, conditioned on a set of relative camera pose parameters. Our model does not require depth as input, and does not explicitly model 3D scene geometry, instead performing end-to-end video-to-video translation in order to achieve its goal efficiently. Despite being trained on synthetic multi-view video data only, zero-shot real-world generalization experiments show promising results in multiple domains, including robotics, object permanence, and driving environments. We believe our framework can potentially unlock powerful applications in rich dynamic scene understanding, perception for robotics, and interactive 3D video viewing experiences for virtual reality.
5/24/2024

Guess The Unseen: Dynamic 3D Scene Reconstruction from Partial 2D Glimpses
Inhee Lee, Byungjun Kim, Hanbyul Joo
0
0
In this paper, we present a method to reconstruct the world and multiple dynamic humans in 3D from a monocular video input. As a key idea, we represent both the world and multiple humans via the recently emerging 3D Gaussian Splatting (3D-GS) representation, enabling to conveniently and efficiently compose and render them together. In particular, we address the scenarios with severely limited and sparse observations in 3D human reconstruction, a common challenge encountered in the real world. To tackle this challenge, we introduce a novel approach to optimize the 3D-GS representation in a canonical space by fusing the sparse cues in the common space, where we leverage a pre-trained 2D diffusion model to synthesize unseen views while keeping the consistency with the observed 2D appearances. We demonstrate our method can reconstruct high-quality animatable 3D humans in various challenging examples, in the presence of occlusion, image crops, few-shot, and extremely sparse observations. After reconstruction, our method is capable of not only rendering the scene in any novel views at arbitrary time instances, but also editing the 3D scene by removing individual humans or applying different motions for each human. Through various experiments, we demonstrate the quality and efficiency of our methods over alternative existing approaches.
4/23/2024

Self-Calibrating 4D Novel View Synthesis from Monocular Videos Using Gaussian Splatting
Fang Li, Hao Zhang, Narendra Ahuja
0
0
Gaussian Splatting (GS) has significantly elevated scene reconstruction efficiency and novel view synthesis (NVS) accuracy compared to Neural Radiance Fields (NeRF), particularly for dynamic scenes. However, current 4D NVS methods, whether based on GS or NeRF, primarily rely on camera parameters provided by COLMAP and even utilize sparse point clouds generated by COLMAP for initialization, which lack accuracy as well are time-consuming. This sometimes results in poor dynamic scene representation, especially in scenes with large object movements, or extreme camera conditions e.g. small translations combined with large rotations. Some studies simultaneously optimize the estimation of camera parameters and scenes, supervised by additional information like depth, optical flow, etc. obtained from off-the-shelf models. Using this unverified information as ground truth can reduce robustness and accuracy, which does frequently occur for long monocular videos (with e.g. > hundreds of frames). We propose a novel approach that learns a high-fidelity 4D GS scene representation with self-calibration of camera parameters. It includes the extraction of 2D point features that robustly represent 3D structure, and their use for subsequent joint optimization of camera parameters and 3D structure towards overall 4D scene optimization. We demonstrate the accuracy and time efficiency of our method through extensive quantitative and qualitative experimental results on several standard benchmarks. The results show significant improvements over state-of-the-art methods for 4D novel view synthesis. The source code will be released soon at https://github.com/fangli333/SC-4DGS.
6/4/2024