Guess The Unseen: Dynamic 3D Scene Reconstruction from Partial 2D Glimpses
2404.14410
0
1

Abstract
In this paper, we present a method to reconstruct the world and multiple dynamic humans in 3D from a monocular video input. As a key idea, we represent both the world and multiple humans via the recently emerging 3D Gaussian Splatting (3D-GS) representation, enabling to conveniently and efficiently compose and render them together. In particular, we address the scenarios with severely limited and sparse observations in 3D human reconstruction, a common challenge encountered in the real world. To tackle this challenge, we introduce a novel approach to optimize the 3D-GS representation in a canonical space by fusing the sparse cues in the common space, where we leverage a pre-trained 2D diffusion model to synthesize unseen views while keeping the consistency with the observed 2D appearances. We demonstrate our method can reconstruct high-quality animatable 3D humans in various challenging examples, in the presence of occlusion, image crops, few-shot, and extremely sparse observations. After reconstruction, our method is capable of not only rendering the scene in any novel views at arbitrary time instances, but also editing the 3D scene by removing individual humans or applying different motions for each human. Through various experiments, we demonstrate the quality and efficiency of our methods over alternative existing approaches.
Create account to get full access
Overview
- This paper presents a novel approach to dynamic 3D scene reconstruction from partial 2D glimpses, called "Guess The Unseen".
- The method aims to reconstruct a full 3D scene from limited 2D observations, by leveraging learned priors about the scene structure and dynamics.
- The paper introduces techniques like sparse controlled Gaussian splatting, Gaussian 3D splatting, and dynamic Gaussian mesh reconstruction to enable efficient and effective reconstruction.
Plain English Explanation
The paper tackles the challenge of reconstructing a full 3D scene from limited 2D observations, like looking at a scene through a small window. Rather than just showing what's visible, the system tries to "guess" the unseen parts of the scene based on learned patterns.
Imagine you're looking through a door into a room. You can only see a small portion of the room, but you might be able to infer the rest of the space based on what you know about typical room layouts. The "Guess The Unseen" method works in a similar way, using machine learning to build an understanding of 3D scenes and how they tend to look and behave.
By combining this learned knowledge with the partial 2D glimpses, the system can efficiently reconstruct a complete 3D model of the scene. This could be useful for applications like virtual reality, where you'd want to create an immersive 3D environment from limited sensor data.
Technical Explanation
The core of the "Guess The Unseen" approach is the use of techniques like sparse controlled Gaussian splatting, Gaussian 3D splatting, and dynamic Gaussian mesh reconstruction to enable efficient and effective 3D scene reconstruction.
The system takes in a sequence of partial 2D observations, such as camera images or depth maps, and uses these to build a dynamic 3D model of the scene. The Gaussian splatting techniques allow the system to represent the 3D structure in a compact and flexible way, while the dynamic reconstruction method ensures that the model can adapt to changes in the scene over time.
By leveraging learned priors about scene structure and dynamics, the system is able to "guess" the unseen parts of the 3D scene and reconstruct a coherent and plausible model, even from limited 2D inputs. This is a significant advance over previous methods that could only handle static scenes or required dense 3D data.
Critical Analysis
The paper presents a compelling approach to dynamic 3D scene reconstruction, but there are a few potential limitations and areas for further research that could be explored:
- The system relies on learned priors about scene structure and dynamics, which may not generalize well to highly unusual or novel environments. Expanding the training data and improving the generalization capabilities could be an area of focus.
- The reconstruction quality and accuracy are not evaluated in depth, and it's unclear how the method would perform in real-world applications with noisy or incomplete sensor data.
- The computational efficiency and runtime of the system are also not thoroughly discussed, which could be an important consideration for real-time applications like text-to-3D scene generation or deformable 3D rendering.
Overall, the "Guess The Unseen" approach represents an interesting and promising direction in the field of dynamic 3D scene reconstruction, but further research and evaluation would be needed to fully assess its capabilities and limitations.
Conclusion
The "Guess The Unseen" paper presents a novel method for reconstructing dynamic 3D scenes from partial 2D observations, leveraging learned priors about scene structure and dynamics. By combining techniques like Gaussian splatting and dynamic mesh reconstruction, the system is able to efficiently infer the unseen parts of a 3D environment and build a coherent model.
This work has the potential to enable more immersive virtual reality experiences, as well as applications in areas like autonomous navigation and robotics, where understanding the full 3D context of a scene is crucial. As the field of 3D scene understanding continues to evolve, approaches like "Guess The Unseen" that can handle partial and dynamic data will become increasingly important.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Object-centric Reconstruction and Tracking of Dynamic Unknown Objects using 3D Gaussian Splatting
Kuldeep R Barad, Antoine Richard, Jan Dentler, Miguel Olivares-Mendez, Carol Martinez
0
0
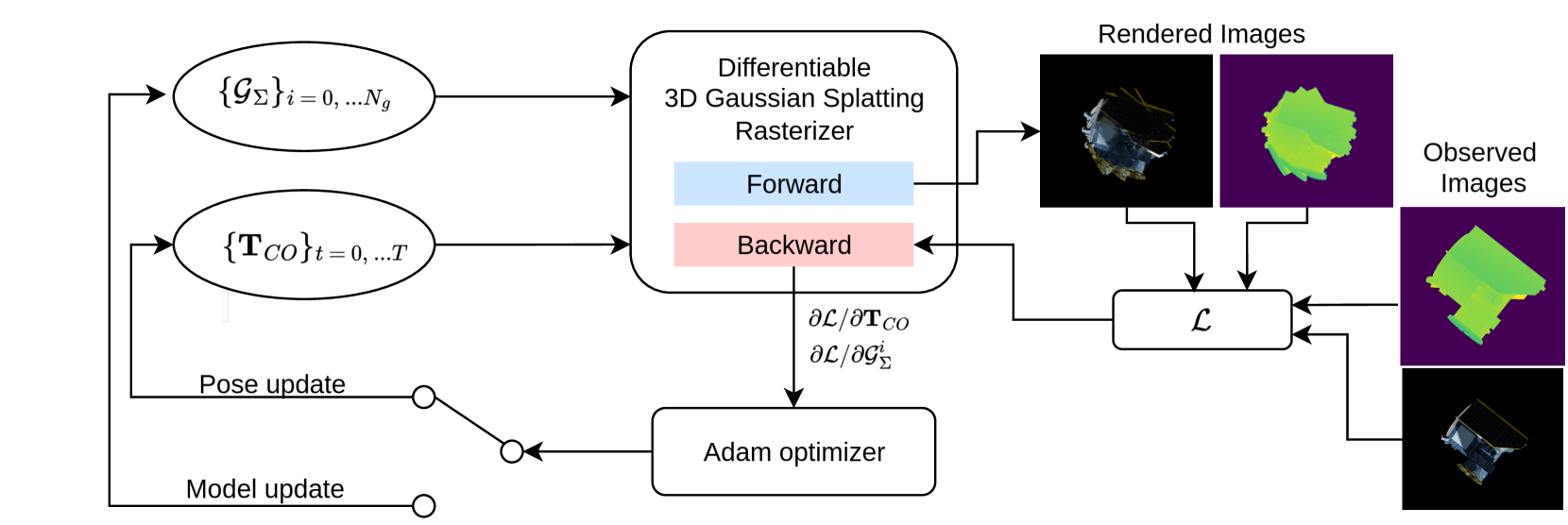
Generalizable perception is one of the pillars of high-level autonomy in space robotics. Estimating the structure and motion of unknown objects in dynamic environments is fundamental for such autonomous systems. Traditionally, the solutions have relied on prior knowledge of target objects, multiple disparate representations, or low-fidelity outputs unsuitable for robotic operations. This work proposes a novel approach to incrementally reconstruct and track a dynamic unknown object using a unified representation -- a set of 3D Gaussian blobs that describe its geometry and appearance. The differentiable 3D Gaussian Splatting framework is adapted to a dynamic object-centric setting. The input to the pipeline is a sequential set of RGB-D images. 3D reconstruction and 6-DoF pose tracking tasks are tackled using first-order gradient-based optimization. The formulation is simple, requires no pre-training, assumes no prior knowledge of the object or its motion, and is suitable for online applications. The proposed approach is validated on a dataset of 10 unknown spacecraft of diverse geometry and texture under arbitrary relative motion. The experiments demonstrate successful 3D reconstruction and accurate 6-DoF tracking of the target object in proximity operations over a short to medium duration. The causes of tracking drift are discussed and potential solutions are outlined.
5/31/2024

Modeling Ambient Scene Dynamics for Free-view Synthesis
Meng-Li Shih, Jia-Bin Huang, Changil Kim, Rajvi Shah, Johannes Kopf, Chen Gao
0
0
We introduce a novel method for dynamic free-view synthesis of an ambient scenes from a monocular capture bringing a immersive quality to the viewing experience. Our method builds upon the recent advancements in 3D Gaussian Splatting (3DGS) that can faithfully reconstruct complex static scenes. Previous attempts to extend 3DGS to represent dynamics have been confined to bounded scenes or require multi-camera captures, and often fail to generalize to unseen motions, limiting their practical application. Our approach overcomes these constraints by leveraging the periodicity of ambient motions to learn the motion trajectory model, coupled with careful regularization. We also propose important practical strategies to improve the visual quality of the baseline 3DGS static reconstructions and to improve memory efficiency critical for GPU-memory intensive learning. We demonstrate high-quality photorealistic novel view synthesis of several ambient natural scenes with intricate textures and fine structural elements.
6/14/2024
Enhancing Temporal Consistency in Video Editing by Reconstructing Videos with 3D Gaussian Splatting
Inkyu Shin, Qihang Yu, Xiaohui Shen, In So Kweon, Kuk-Jin Yoon, Liang-Chieh Chen
0
0
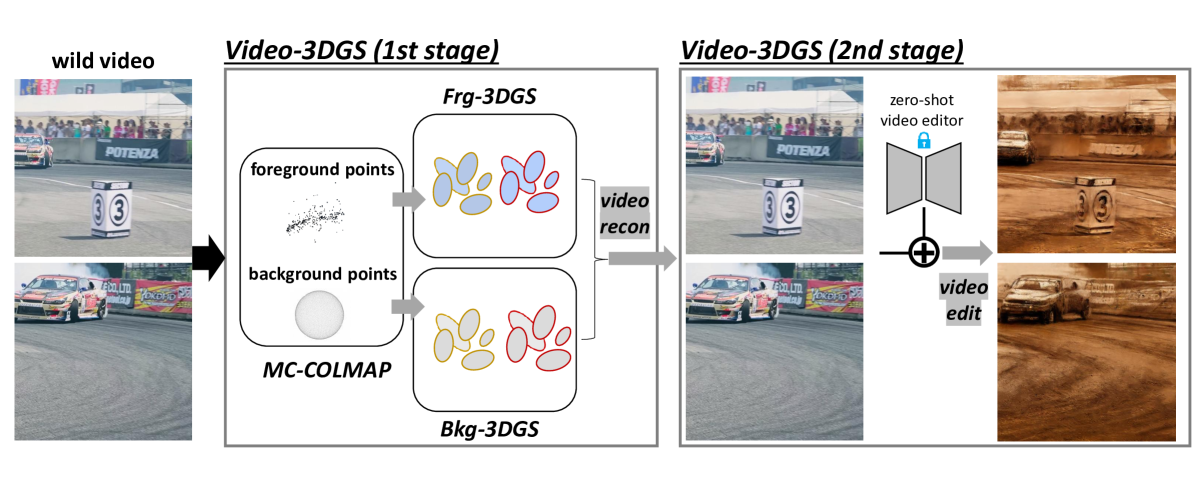
Recent advancements in zero-shot video diffusion models have shown promise for text-driven video editing, but challenges remain in achieving high temporal consistency. To address this, we introduce Video-3DGS, a 3D Gaussian Splatting (3DGS)-based video refiner designed to enhance temporal consistency in zero-shot video editors. Our approach utilizes a two-stage 3D Gaussian optimizing process tailored for editing dynamic monocular videos. In the first stage, Video-3DGS employs an improved version of COLMAP, referred to as MC-COLMAP, which processes original videos using a Masked and Clipped approach. For each video clip, MC-COLMAP generates the point clouds for dynamic foreground objects and complex backgrounds. These point clouds are utilized to initialize two sets of 3D Gaussians (Frg-3DGS and Bkg-3DGS) aiming to represent foreground and background views. Both foreground and background views are then merged with a 2D learnable parameter map to reconstruct full views. In the second stage, we leverage the reconstruction ability developed in the first stage to impose the temporal constraints on the video diffusion model. To demonstrate the efficacy of Video-3DGS on both stages, we conduct extensive experiments across two related tasks: Video Reconstruction and Video Editing. Video-3DGS trained with 3k iterations significantly improves video reconstruction quality (+3 PSNR, +7 PSNR increase) and training efficiency (x1.9, x4.5 times faster) over NeRF-based and 3DGS-based state-of-art methods on DAVIS dataset, respectively. Moreover, it enhances video editing by ensuring temporal consistency across 58 dynamic monocular videos.
6/7/2024
📉
Gaussian Splatting: 3D Reconstruction and Novel View Synthesis, a Review
Anurag Dalal, Daniel Hagen, Kjell G. Robbersmyr, Kristian Muri Knausg{aa}rd
0
0
Image-based 3D reconstruction is a challenging task that involves inferring the 3D shape of an object or scene from a set of input images. Learning-based methods have gained attention for their ability to directly estimate 3D shapes. This review paper focuses on state-of-the-art techniques for 3D reconstruction, including the generation of novel, unseen views. An overview of recent developments in the Gaussian Splatting method is provided, covering input types, model structures, output representations, and training strategies. Unresolved challenges and future directions are also discussed. Given the rapid progress in this domain and the numerous opportunities for enhancing 3D reconstruction methods, a comprehensive examination of algorithms appears essential. Consequently, this study offers a thorough overview of the latest advancements in Gaussian Splatting.
5/7/2024