GLGait: A Global-Local Temporal Receptive Field Network for Gait Recognition in the Wild

0

Sign in to get full access
Overview
- The paper proposes a new deep learning model called GLGait for gait recognition in unconstrained, "in the wild" settings.
- GLGait leverages a global-local temporal receptive field network to effectively capture both global and local temporal patterns in gait sequences.
- The model is evaluated on several gait recognition benchmarks and achieves state-of-the-art performance.
Plain English Explanation
The research paper introduces a new deep learning model called GLGait that is designed for recognizing people based on how they walk, even in unconstrained, real-world conditions. Gait recognition is the process of identifying individuals by the way they move their body when walking.
Gait Recognition can be a useful biometric technique for applications like surveillance and authentication, but it can be challenging in uncontrolled environments with factors like different camera views, clothing, and walking surfaces.
To address this, the GLGait model uses a global-local temporal receptive field network that can effectively capture both the overall patterns and the finer details in a person's gait sequence. This allows the model to recognize individuals even when their walking is affected by real-world conditions.
The researchers evaluate GLGait on several standard benchmarks for gait recognition and show that it outperforms other state-of-the-art methods. This suggests the model could be a valuable tool for practical applications that require robust gait-based identification.
Technical Explanation
The key innovation in the GLGait model is its use of a global-local temporal receptive field network to process gait silhouette sequences. This network consists of two parallel branches:
- Global Temporal Receptive Field Branch: This branch captures the overall temporal patterns in the gait sequence by using 3D convolutions with large receptive fields.
- Local Temporal Receptive Field Branch: This branch focuses on learning the fine-grained, local temporal dynamics by using 3D convolutions with smaller receptive fields.
The outputs of these two branches are then fused to produce the final gait representation, which leverages both global and local temporal information.
The researchers also incorporate additional techniques to further improve the model's performance, such as temporal feature learning with granularity span and complementary learning through neural architecture search.
The GLGait model is evaluated on several widely used gait recognition benchmarks, including CASIA-B, OU-MVLP, and GREW, and it achieves state-of-the-art performance across these datasets.
Critical Analysis
The paper provides a thorough evaluation of the GLGait model and demonstrates its effectiveness for gait recognition in the wild. However, the authors do acknowledge some limitations:
- The model's performance may still be affected by extreme variations in factors like clothing and walking surfaces, which are not fully addressed in the current benchmarks.
- The computational complexity of the global-local temporal receptive field network could be a concern for real-time applications, and the authors suggest exploring more efficient architectures.
Additionally, the paper does not delve into potential ethical considerations or societal implications of gait recognition technology, which is an important area for further discussion and research.
Conclusion
The GLGait model proposed in this paper represents a significant advancement in gait recognition, particularly for unconstrained, real-world settings. By leveraging a global-local temporal receptive field network, the model is able to effectively capture both the overall patterns and fine-grained details in gait sequences, leading to state-of-the-art performance on several benchmark datasets.
This research highlights the potential of gait recognition as a biometric technique and could have important implications for applications like surveillance, authentication, and human behavior analysis. However, it also underscores the need to consider the ethical and societal impacts of such technologies as they continue to evolve.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
GLGait: A Global-Local Temporal Receptive Field Network for Gait Recognition in the Wild
Guozhen Peng, Yunhong Wang, Yuwei Zhao, Shaoxiong Zhang, Annan Li
Gait recognition has attracted increasing attention from academia and industry as a human recognition technology from a distance in non-intrusive ways without requiring cooperation. Although advanced methods have achieved impressive success in lab scenarios, most of them perform poorly in the wild. Recently, some Convolution Neural Networks (ConvNets) based methods have been proposed to address the issue of gait recognition in the wild. However, the temporal receptive field obtained by convolution operations is limited for long gait sequences. If directly replacing convolution blocks with visual transformer blocks, the model may not enhance a local temporal receptive field, which is important for covering a complete gait cycle. To address this issue, we design a Global-Local Temporal Receptive Field Network (GLGait). GLGait employs a Global-Local Temporal Module (GLTM) to establish a global-local temporal receptive field, which mainly consists of a Pseudo Global Temporal Self-Attention (PGTA) and a temporal convolution operation. Specifically, PGTA is used to obtain a pseudo global temporal receptive field with less memory and computation complexity compared with a multi-head self-attention (MHSA). The temporal convolution operation is used to enhance the local temporal receptive field. Besides, it can also aggregate pseudo global temporal receptive field to a true holistic temporal receptive field. Furthermore, we also propose a Center-Augmented Triplet Loss (CTL) in GLGait to reduce the intra-class distance and expand the positive samples in the training stage. Extensive experiments show that our method obtains state-of-the-art results on in-the-wild datasets, $i.e.$, Gait3D and GREW. The code is available at https://github.com/bgdpgz/GLGait.
Read more8/14/2024
👁️
0
ST-Gait++: Leveraging spatio-temporal convolutions for gait-based emotion recognition on videos
Maria Lu'isa Lima, Willams de Lima Costa, Estefania Talavera Martinez, Veronica Teichrieb
Emotion recognition is relevant for human behaviour understanding, where facial expression and speech recognition have been widely explored by the computer vision community. Literature in the field of behavioural psychology indicates that gait, described as the way a person walks, is an additional indicator of emotions. In this work, we propose a deep framework for emotion recognition through the analysis of gait. More specifically, our model is composed of a sequence of spatial-temporal Graph Convolutional Networks that produce a robust skeleton-based representation for the task of emotion classification. We evaluate our proposed framework on the E-Gait dataset, composed of a total of 2177 samples. The results obtained represent an improvement of approximately 5% in accuracy compared to the state of the art. In addition, during training we observed a faster convergence of our model compared to the state-of-the-art methodologies.
Read more5/24/2024

0
GaitMA: Pose-guided Multi-modal Feature Fusion for Gait Recognition
Fanxu Min, Shaoxiang Guo, Fan Hao, Junyu Dong
Gait recognition is a biometric technology that recognizes the identity of humans through their walking patterns. Existing appearance-based methods utilize CNN or Transformer to extract spatial and temporal features from silhouettes, while model-based methods employ GCN to focus on the special topological structure of skeleton points. However, the quality of silhouettes is limited by complex occlusions, and skeletons lack dense semantic features of the human body. To tackle these problems, we propose a novel gait recognition framework, dubbed Gait Multi-model Aggregation Network (GaitMA), which effectively combines two modalities to obtain a more robust and comprehensive gait representation for recognition. First, skeletons are represented by joint/limb-based heatmaps, and features from silhouettes and skeletons are respectively extracted using two CNN-based feature extractors. Second, a co-attention alignment module is proposed to align the features by element-wise attention. Finally, we propose a mutual learning module, which achieves feature fusion through cross-attention, Wasserstein loss is further introduced to ensure the effective fusion of two modalities. Extensive experimental results demonstrate the superiority of our model on Gait3D, OU-MVLP, and CASIA-B.
Read more7/23/2024
0
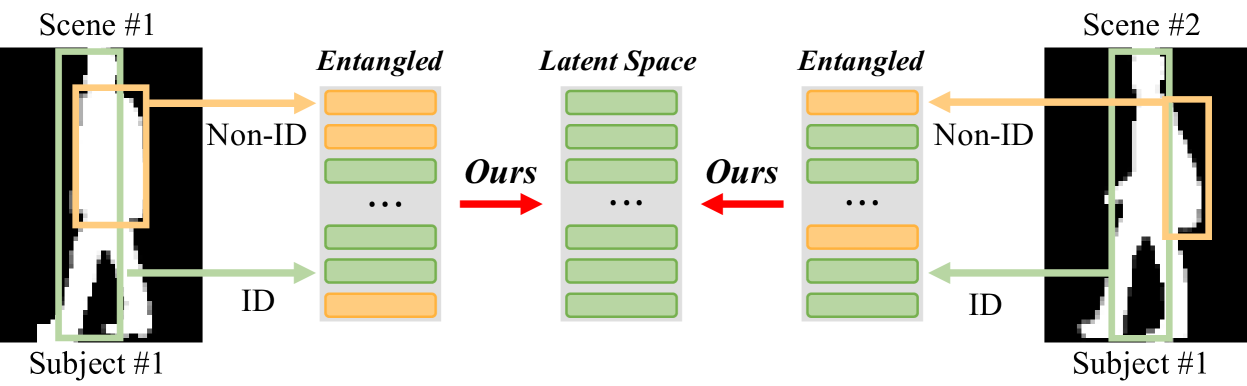
Causality-inspired Discriminative Feature Learning in Triple Domains for Gait Recognition
Haijun Xiong, Bin Feng, Xinggang Wang, Wenyu Liu
Gait recognition is a biometric technology that distinguishes individuals by their walking patterns. However, previous methods face challenges when accurately extracting identity features because they often become entangled with non-identity clues. To address this challenge, we propose CLTD, a causality-inspired discriminative feature learning module designed to effectively eliminate the influence of confounders in triple domains, ie, spatial, temporal, and spectral. Specifically, we utilize the Cross Pixel-wise Attention Generator (CPAG) to generate attention distributions for factual and counterfactual features in spatial and temporal domains. Then, we introduce the Fourier Projection Head (FPH) to project spatial features into the spectral space, which preserves essential information while reducing computational costs. Additionally, we employ an optimization method with contrastive learning to enforce semantic consistency constraints across sequences from the same subject. Our approach has demonstrated significant performance improvements on challenging datasets, proving its effectiveness. Moreover, it can be seamlessly integrated into existing gait recognition methods.
Read more7/18/2024