GMTalker: Gaussian Mixture-based Audio-Driven Emotional talking video Portraits
2312.07669
0
0

Abstract
Synthesizing high-fidelity and emotion-controllable talking video portraits, with audio-lip sync, vivid expressions, realistic head poses, and eye blinks, has been an important and challenging task in recent years. Most existing methods suffer in achieving personalized and precise emotion control, smooth transitions between different emotion states, and the generation of diverse motions. To tackle these challenges, we present GMTalker, a Gaussian mixture-based emotional talking portraits generation framework. Specifically, we propose a Gaussian mixture-based expression generator that can construct a continuous and disentangled latent space, achieving more flexible emotion manipulation. Furthermore, we introduce a normalizing flow-based motion generator pretrained on a large dataset with a wide-range motion to generate diverse head poses, blinks, and eyeball movements. Finally, we propose a personalized emotion-guided head generator with an emotion mapping network that can synthesize high-fidelity and faithful emotional video portraits. Both quantitative and qualitative experiments demonstrate our method outperforms previous methods in image quality, photo-realism, emotion accuracy, and motion diversity.
Create account to get full access
Overview
• This paper presents a novel Gaussian Mixture-based model called "GMTalker" for generating emotional talking video portraits driven by speech input.
• The key ideas are to use a Gaussian Mixture Model to capture the complex relationship between speech and facial movements, and to enable fine-grained control over the emotional expression of the generated talking head.
Plain English Explanation
The researchers have developed a new AI system called "GMTalker" that can create video animations of a talking person's head and face. The unique aspect of this system is its ability to generate emotional expressions that match the speech input.
Typically, creating realistic talking head animations is challenging because the movements of the face, lips, and other features don't always align perfectly with the audio. The GMTalker approach aims to capture this complex relationship between speech and facial movements using a statistical model called a Gaussian Mixture Model.
This allows the system to generate talking head videos where the facial expressions, like smiling or frowning, naturally correspond to the emotional tone and content of the speech. The researchers also designed the system to give users fine-grained control over the emotional expression of the generated talking head, enabling them to adjust things like the intensity of the emotions.
Technical Explanation
The key innovation in GMTalker is the use of a Gaussian Mixture Model (GMM) to jointly model the relationship between speech features and facial animation parameters. This builds on prior work like GSTalker and CSTalk, which also used statistical models to drive talking head animation from speech.
The GMM allows GMTalker to capture the complex, nonlinear mapping between speech and facial movements, which is important for generating natural-looking emotional expressions. The model is trained on a dataset of talking head videos with corresponding speech audio.
At runtime, the system takes a new speech audio input and uses the trained GMM to predict the facial animation parameters frame-by-frame. This generates a talking head video where the facial expressions match the speech. The researchers also incorporate additional control mechanisms to allow users to adjust the emotional intensity of the generated expressions.
Critical Analysis
The GMTalker approach represents an advance in speech-driven talking head synthesis, with its ability to generate emotional expressions that are well-aligned with the input speech. However, the paper does not extensively evaluate the model's performance compared to prior work or provide subjective user studies to assess the perceived realism and quality of the generated videos.
Additionally, the system is limited to producing 2D talking head animations, rather than 3D models. Extending the approach to generate more detailed 3D facial animations could further improve its realism and versatility. The researchers also note that the GMM-based modeling approach has some inherent limitations in capturing complex, high-dimensional relationships, which could motivate exploring alternative neural network-based architectures in future work.
Conclusion
Overall, the GMTalker system demonstrates the potential of statistical modeling techniques like Gaussian Mixture Models to enable speech-driven generation of emotional talking head animations. This could have applications in areas like virtual assistants, video conferencing, and entertainment, where realistic and expressive talking avatars are desired. While there is room for further research and development, this work represents an interesting step forward in this field.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Emotional Conversation: Empowering Talking Faces with Cohesive Expression, Gaze and Pose Generation
Jiadong Liang, Feng Lu
0
0
Vivid talking face generation holds immense potential applications across diverse multimedia domains, such as film and game production. While existing methods accurately synchronize lip movements with input audio, they typically ignore crucial alignments between emotion and facial cues, which include expression, gaze, and head pose. These alignments are indispensable for synthesizing realistic videos. To address these issues, we propose a two-stage audio-driven talking face generation framework that employs 3D facial landmarks as intermediate variables. This framework achieves collaborative alignment of expression, gaze, and pose with emotions through self-supervised learning. Specifically, we decompose this task into two key steps, namely speech-to-landmarks synthesis and landmarks-to-face generation. The first step focuses on simultaneously synthesizing emotionally aligned facial cues, including normalized landmarks that represent expressions, gaze, and head pose. These cues are subsequently reassembled into relocated facial landmarks. In the second step, these relocated landmarks are mapped to latent key points using self-supervised learning and then input into a pretrained model to create high-quality face images. Extensive experiments on the MEAD dataset demonstrate that our model significantly advances the state-of-the-art performance in both visual quality and emotional alignment.
6/13/2024
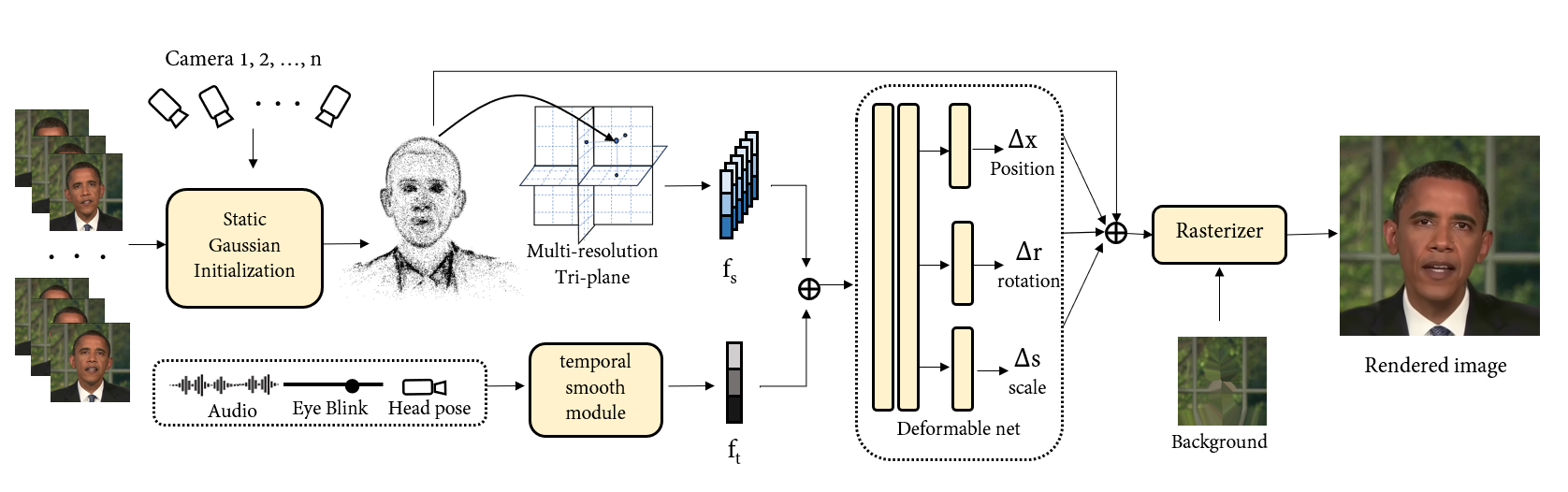
GSTalker: Real-time Audio-Driven Talking Face Generation via Deformable Gaussian Splatting
Bo Chen, Shoukang Hu, Qi Chen, Chenpeng Du, Ran Yi, Yanmin Qian, Xie Chen
0
0
We present GStalker, a 3D audio-driven talking face generation model with Gaussian Splatting for both fast training (40 minutes) and real-time rendering (125 FPS) with a 3$sim$5 minute video for training material, in comparison with previous 2D and 3D NeRF-based modeling frameworks which require hours of training and seconds of rendering per frame. Specifically, GSTalker learns an audio-driven Gaussian deformation field to translate and transform 3D Gaussians to synchronize with audio information, in which multi-resolution hashing grid-based tri-plane and temporal smooth module are incorporated to learn accurate deformation for fine-grained facial details. In addition, a pose-conditioned deformation field is designed to model the stabilized torso. To enable efficient optimization of the condition Gaussian deformation field, we initialize 3D Gaussians by learning a coarse static Gaussian representation. Extensive experiments in person-specific videos with audio tracks validate that GSTalker can generate high-fidelity and audio-lips synchronized results with fast training and real-time rendering speed.
5/1/2024
👨🏫
CSTalk: Correlation Supervised Speech-driven 3D Emotional Facial Animation Generation
Xiangyu Liang, Wenlin Zhuang, Tianyong Wang, Guangxing Geng, Guangyue Geng, Haifeng Xia, Siyu Xia
0
0
Speech-driven 3D facial animation technology has been developed for years, but its practical application still lacks expectations. The main challenges lie in data limitations, lip alignment, and the naturalness of facial expressions. Although lip alignment has seen many related studies, existing methods struggle to synthesize natural and realistic expressions, resulting in a mechanical and stiff appearance of facial animations. Even with some research extracting emotional features from speech, the randomness of facial movements limits the effective expression of emotions. To address this issue, this paper proposes a method called CSTalk (Correlation Supervised) that models the correlations among different regions of facial movements and supervises the training of the generative model to generate realistic expressions that conform to human facial motion patterns. To generate more intricate animations, we employ a rich set of control parameters based on the metahuman character model and capture a dataset for five different emotions. We train a generative network using an autoencoder structure and input an emotion embedding vector to achieve the generation of user-control expressions. Experimental results demonstrate that our method outperforms existing state-of-the-art methods.
4/30/2024

GaussianTalker: Speaker-specific Talking Head Synthesis via 3D Gaussian Splatting
Hongyun Yu, Zhan Qu, Qihang Yu, Jianchuan Chen, Zhonghua Jiang, Zhiwen Chen, Shengyu Zhang, Jimin Xu, Fei Wu, Chengfei Lv, Gang Yu
0
0
Recent works on audio-driven talking head synthesis using Neural Radiance Fields (NeRF) have achieved impressive results. However, due to inadequate pose and expression control caused by NeRF implicit representation, these methods still have some limitations, such as unsynchronized or unnatural lip movements, and visual jitter and artifacts. In this paper, we propose GaussianTalker, a novel method for audio-driven talking head synthesis based on 3D Gaussian Splatting. With the explicit representation property of 3D Gaussians, intuitive control of the facial motion is achieved by binding Gaussians to 3D facial models. GaussianTalker consists of two modules, Speaker-specific Motion Translator and Dynamic Gaussian Renderer. Speaker-specific Motion Translator achieves accurate lip movements specific to the target speaker through universalized audio feature extraction and customized lip motion generation. Dynamic Gaussian Renderer introduces Speaker-specific BlendShapes to enhance facial detail representation via a latent pose, delivering stable and realistic rendered videos. Extensive experimental results suggest that GaussianTalker outperforms existing state-of-the-art methods in talking head synthesis, delivering precise lip synchronization and exceptional visual quality. Our method achieves rendering speeds of 130 FPS on NVIDIA RTX4090 GPU, significantly exceeding the threshold for real-time rendering performance, and can potentially be deployed on other hardware platforms.
4/30/2024