GOVERN: Gradient Orientation Vote Ensemble for Multi-Teacher Reinforced Distillation
2405.03764
0
0

Abstract
Pre-trained language models have become an integral component of question-answering systems, achieving remarkable performance. For practical deployment, it is critical to carry out knowledge distillation to preserve high performance under computational constraints. In this paper, we address a key question: given the importance of unsupervised distillation for student performance, how does one effectively ensemble knowledge from multiple teachers at this stage without the guidance of ground-truth labels? We propose a novel algorithm, GOVERN, to tackle this issue. GOVERN has demonstrated significant improvements in both offline and online experiments. The proposed algorithm has been successfully deployed in a real-world commercial question-answering system.
Create account to get full access
Overview
- The paper proposes GOVERN, a novel ensemble distillation method that leverages multiple teacher models to train a more accurate student model.
- GOVERN uses a gradient orientation voting mechanism to effectively combine the knowledge from multiple teachers and guide the student model's training.
- The approach is evaluated on the answer selection task, where the student model needs to select the most relevant answer to a given question.
Plain English Explanation
The research paper introduces a new method called GOVERN (Gradient Orientation Vote Ensemble) for training a student model to perform well on a task by learning from multiple teacher models. The key idea is to have several different teacher models, each with their own expertise, and then combine their knowledge in a smart way to train the student model.
Typically, when distilling knowledge from multiple teachers, it can be challenging to effectively integrate the different perspectives and insights. GOVERN addresses this by using a voting mechanism based on the directions of the gradients (the rates of change) during the training process. This allows the student model to learn from the most relevant and consistent information provided by the teachers, resulting in a more accurate and robust student model.
The researchers evaluate GOVERN on the task of answer selection, where the student model needs to identify the most relevant answer to a given question. This is an important task in areas like question-answering systems and conversational AI. By leveraging the knowledge of multiple teacher models, GOVERN is able to outperform traditional single-teacher distillation approaches.
Technical Explanation
The paper introduces a novel ensemble distillation method called GOVERN (Gradient Orientation Vote Ensemble) that aims to effectively combine the knowledge from multiple teacher models to train a more accurate student model. GOVERN utilizes a gradient orientation voting mechanism to guide the student model's training process.
The key idea behind GOVERN is to leverage the gradients (the rates of change) during the training of the student model. By examining the directions of the gradients from multiple teacher models, GOVERN can identify the most consistent and relevant information to guide the student model's learning. This is achieved through a voting procedure that assigns weights to the gradients of each teacher model based on their alignment with the majority gradient orientation.
The authors evaluate GOVERN on the answer selection task, where the student model needs to select the most relevant answer to a given question. The experiments show that GOVERN outperforms traditional single-teacher distillation approaches, as well as other ensemble distillation methods, in terms of the student model's performance on this task.
The paper also discusses the potential benefits of GOVERN, such as its ability to effectively combine the knowledge from diverse teacher models, its robustness to noise or disagreement among the teachers, and its potential applicability to other tasks beyond answer selection.
Critical Analysis
The GOVERN method proposed in the paper offers a novel and promising approach to ensemble distillation, addressing some of the challenges in effectively integrating knowledge from multiple teacher models. The gradient orientation voting mechanism seems to be a clever way to identify the most relevant and consistent information to guide the student model's training.
One potential limitation of the approach, as mentioned in the paper, is that it assumes the teacher models have similar levels of performance. If there is a significant disparity in the quality of the teacher models, the voting mechanism may not be as effective in selecting the most useful gradients. Additionally, the paper does not explore the impact of the number of teacher models or the diversity of their architectures and training approaches on the performance of GOVERN.
Further research could investigate the robustness of GOVERN to more diverse teacher model sets, as well as its applicability to other tasks beyond answer selection. Exploring the interpretability of the gradient orientation voting process and how it can provide insights into the knowledge transfer from teachers to the student model could also be an interesting avenue for future work.
Overall, the GOVERN method presented in the paper is a valuable contribution to the field of ensemble distillation, offering a novel and effective approach to leveraging multiple teacher models. The results on the answer selection task are promising, and the potential for broader applicability makes this research an interesting area for further exploration.
Conclusion
The GOVERN method proposed in this paper represents a significant advancement in the field of ensemble distillation, offering a novel approach to effectively combining the knowledge from multiple teacher models. By utilizing a gradient orientation voting mechanism, GOVERN is able to guide the training of the student model in a way that leverages the most consistent and relevant information from the teachers.
The evaluation on the answer selection task demonstrates the effectiveness of GOVERN, with the student model outperforming traditional single-teacher distillation approaches. This suggests that the method could have broader applicability in various domains where ensemble learning and knowledge distillation are crucial, such as [internal link: https://aimodels.fyi/papers/arxiv/ensemble-distillation-unsupervised-constituency-parsing], [internal link: https://aimodels.fyi/papers/arxiv/improve-knowledge-distillation-via-label-revision-data], [internal link: https://aimodels.fyi/papers/arxiv/domain-generalization-crop-segmentation-standardized-ensemble-knowledge], and [internal link: https://aimodels.fyi/papers/arxiv/scaling-motion-forecasting-models-ensemble-distillation].
The critical analysis highlights the potential limitations of the GOVERN approach, such as its sensitivity to the quality and diversity of the teacher models. Exploring these areas further, as well as investigating the interpretability of the gradient orientation voting process, could lead to even more robust and insightful ensemble distillation methods.
Overall, the GOVERN method represents an important contribution to the field of knowledge distillation, with the potential to significantly improve the performance of student models by effectively leveraging the expertise of multiple teacher models. As the demand for efficient and accurate AI systems continues to grow, advancements like GOVERN will play a crucial role in [internal link: https://aimodels.fyi/papers/arxiv/noisy-node-classification-by-bi-level-optimization] and developing highly capable and robust AI models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Ensemble Distillation for Unsupervised Constituency Parsing
Behzad Shayegh, Yanshuai Cao, Xiaodan Zhu, Jackie C. K. Cheung, Lili Mou
0
0
We investigate the unsupervised constituency parsing task, which organizes words and phrases of a sentence into a hierarchical structure without using linguistically annotated data. We observe that existing unsupervised parsers capture differing aspects of parsing structures, which can be leveraged to enhance unsupervised parsing performance. To this end, we propose a notion of tree averaging, based on which we further propose a novel ensemble method for unsupervised parsing. To improve inference efficiency, we further distill the ensemble knowledge into a student model; such an ensemble-then-distill process is an effective approach to mitigate the over-smoothing problem existing in common multi-teacher distilling methods. Experiments show that our method surpasses all previous approaches, consistently demonstrating its effectiveness and robustness across various runs, with different ensemble components, and under domain-shift conditions.
4/29/2024
🌐
Toward Student-Oriented Teacher Network Training For Knowledge Distillation
Chengyu Dong, Liyuan Liu, Jingbo Shang
0
0
How to conduct teacher training for knowledge distillation is still an open problem. It has been widely observed that a best-performing teacher does not necessarily yield the best-performing student, suggesting a fundamental discrepancy between the current teacher training practice and the ideal teacher training strategy. To fill this gap, we explore the feasibility of training a teacher that is oriented toward student performance with empirical risk minimization (ERM). Our analyses are inspired by the recent findings that the effectiveness of knowledge distillation hinges on the teacher's capability to approximate the true label distribution of training inputs. We theoretically establish that the ERM minimizer can approximate the true label distribution of training data as long as the feature extractor of the learner network is Lipschitz continuous and is robust to feature transformations. In light of our theory, we propose a teacher training method SoTeacher which incorporates Lipschitz regularization and consistency regularization into ERM. Experiments on benchmark datasets using various knowledge distillation algorithms and teacher-student pairs confirm that SoTeacher can improve student accuracy consistently.
5/10/2024

Lightweight Model Pre-training via Language Guided Knowledge Distillation
Mingsheng Li, Lin Zhang, Mingzhen Zhu, Zilong Huang, Gang Yu, Jiayuan Fan, Tao Chen
0
0
This paper studies the problem of pre-training for small models, which is essential for many mobile devices. Current state-of-the-art methods on this problem transfer the representational knowledge of a large network (as a Teacher) into a smaller model (as a Student) using self-supervised distillation, improving the performance of the small model on downstream tasks. However, existing approaches are insufficient in extracting the crucial knowledge that is useful for discerning categories in downstream tasks during the distillation process. In this paper, for the first time, we introduce language guidance to the distillation process and propose a new method named Language-Guided Distillation (LGD) system, which uses category names of the target downstream task to help refine the knowledge transferred between the teacher and student. To this end, we utilize a pre-trained text encoder to extract semantic embeddings from language and construct a textual semantic space called Textual Semantics Bank (TSB). Furthermore, we design a Language-Guided Knowledge Aggregation (LGKA) module to construct the visual semantic space, also named Visual Semantics Bank (VSB). The task-related knowledge is transferred by driving a student encoder to mimic the similarity score distribution inferred by a teacher over TSB and VSB. Compared with other small models obtained by either ImageNet pre-training or self-supervised distillation, experiment results show that the distilled lightweight model using the proposed LGD method presents state-of-the-art performance and is validated on various downstream tasks, including classification, detection, and segmentation. We have made the code available at https://github.com/mZhenz/LGD.
6/18/2024
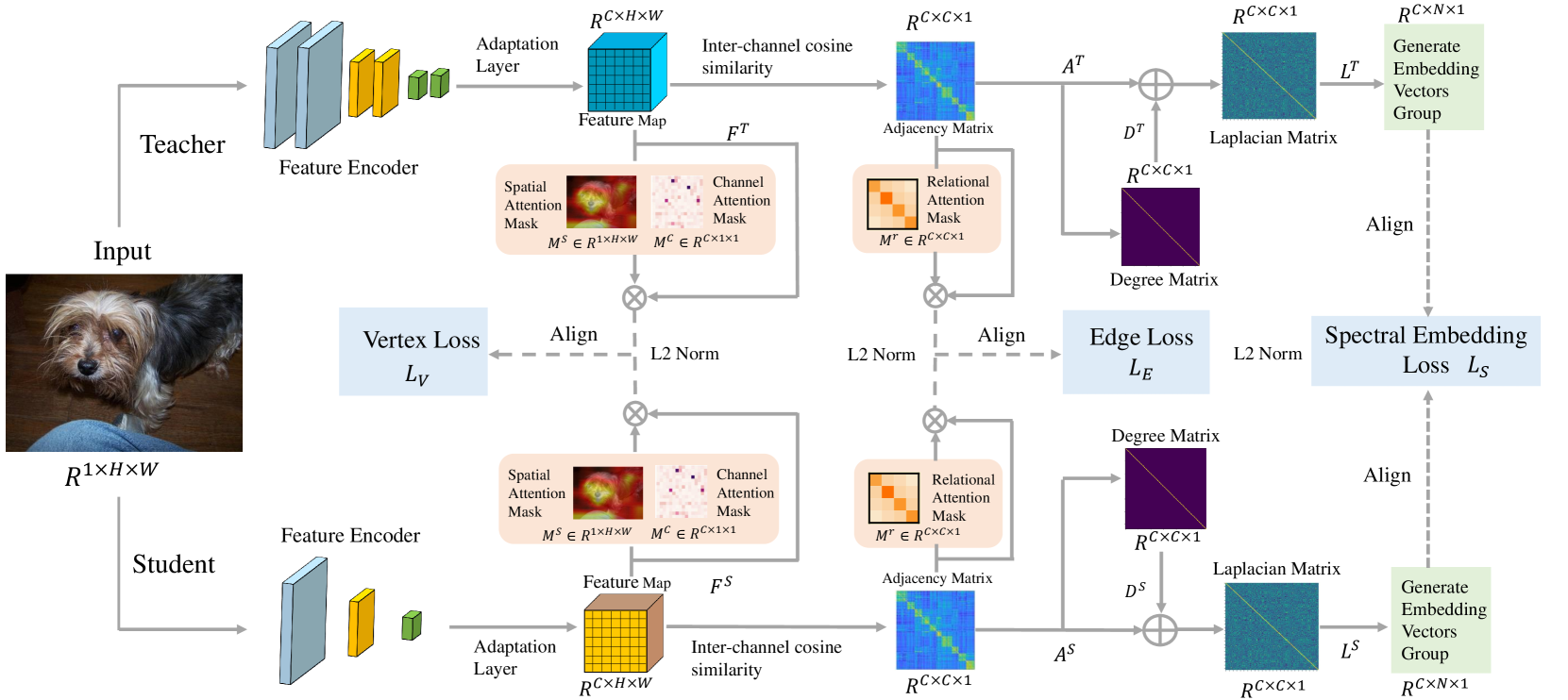
Exploring Graph-based Knowledge: Multi-Level Feature Distillation via Channels Relational Graph
Zhiwei Wang, Jun Huang, Longhua Ma, Chengyu Wu, Hongyu Ma
0
0
In visual tasks, large teacher models capture essential features and deep information, enhancing performance. However, distilling this information into smaller student models often leads to performance loss due to structural differences and capacity limitations. To tackle this, we propose a distillation framework based on graph knowledge, including a multi-level feature alignment strategy and an attention-guided mechanism to provide a targeted learning trajectory for the student model. We emphasize spectral embedding (SE) as a key technique in our distillation process, which merges the student's feature space with the relational knowledge and structural complexities similar to the teacher network. This method captures the teacher's understanding in a graph-based representation, enabling the student model to more accurately mimic the complex structural dependencies present in the teacher model. Compared to methods that focus only on specific distillation areas, our strategy not only considers key features within the teacher model but also endeavors to capture the relationships and interactions among feature sets, encoding these complex pieces of information into a graph structure to understand and utilize the dynamic relationships among these pieces of information from a global perspective. Experiments show that our method outperforms previous feature distillation methods on the CIFAR-100, MS-COCO, and Pascal VOC datasets, proving its efficiency and applicability.
5/17/2024