Toward Student-Oriented Teacher Network Training For Knowledge Distillation
2206.06661
0
0
🌐
Abstract
How to conduct teacher training for knowledge distillation is still an open problem. It has been widely observed that a best-performing teacher does not necessarily yield the best-performing student, suggesting a fundamental discrepancy between the current teacher training practice and the ideal teacher training strategy. To fill this gap, we explore the feasibility of training a teacher that is oriented toward student performance with empirical risk minimization (ERM). Our analyses are inspired by the recent findings that the effectiveness of knowledge distillation hinges on the teacher's capability to approximate the true label distribution of training inputs. We theoretically establish that the ERM minimizer can approximate the true label distribution of training data as long as the feature extractor of the learner network is Lipschitz continuous and is robust to feature transformations. In light of our theory, we propose a teacher training method SoTeacher which incorporates Lipschitz regularization and consistency regularization into ERM. Experiments on benchmark datasets using various knowledge distillation algorithms and teacher-student pairs confirm that SoTeacher can improve student accuracy consistently.
Create account to get full access
Overview
- Knowledge distillation, the process of transferring knowledge from a high-performance "teacher" model to a smaller "student" model, is a widely used technique in machine learning.
- However, training an effective teacher model that can optimally transfer knowledge to the student is still an open problem.
- The research paper explores a new approach called "SoTeacher" that aims to train a teacher model oriented towards improving student performance, rather than just maximizing the teacher's own performance.
Plain English Explanation
The paper explores a new way to train "teacher" machine learning models that can effectively transfer their knowledge to "student" models. In knowledge distillation, the goal is to take a powerful but complex teacher model and distill its knowledge into a simpler student model. This allows the student model to achieve high performance without the same computational requirements.
However, the authors note that a best-performing teacher does not necessarily yield the best-performing student, suggesting a gap between current teacher training practices and the ideal teacher training strategy. To address this, the researchers propose a new approach called "SoTeacher" that trains the teacher model in a way that is specifically oriented towards improving the student's performance, rather than just maximizing the teacher's own accuracy.
The key insight is that the effectiveness of knowledge distillation hinges on the teacher's ability to accurately approximate the true distribution of the training data's labels. The paper theoretically establishes that the optimal teacher model (in terms of this label distribution approximation) can be found using a method called empirical risk minimization (ERM), as long as the student model's feature extractor is Lipschitz continuous and robust to feature transformations.
Based on this theory, the researchers propose the SoTeacher method, which incorporates Lipschitz regularization and consistency regularization into the ERM training process for the teacher model. Experiments on benchmark datasets confirm that SoTeacher can consistently improve the accuracy of the student models across various knowledge distillation algorithms and teacher-student pairs.
Technical Explanation
The key technical contributions of the paper are as follows:
-
Theoretical Analysis: The authors theoretically establish that the ERM minimizer can approximate the true label distribution of the training data, as long as the feature extractor of the student network is Lipschitz continuous and robust to feature transformations. This provides a theoretical foundation for training a teacher model that is oriented towards student performance.
-
SoTeacher Method: Inspired by the theoretical analysis, the researchers propose the SoTeacher method, which incorporates Lipschitz regularization and consistency regularization into the ERM training process for the teacher model. The Lipschitz regularization ensures the feature extractor's robustness, while the consistency regularization encourages the teacher to produce consistent outputs for similar inputs.
-
Empirical Evaluation: The paper presents experiments on benchmark datasets using various knowledge distillation algorithms and teacher-student pairs. The results confirm that the SoTeacher method can consistently improve the accuracy of the student models compared to other teacher training approaches, such as training the teacher to maximize its own performance or using an ensemble of multiple teachers.
Critical Analysis
The paper provides a compelling theoretical and empirical case for the SoTeacher approach to training teacher models for knowledge distillation. However, there are a few potential limitations and areas for further research:
-
Generalization to Diverse Architectures: The theoretical analysis and empirical evaluation in the paper focus on specific network architectures and knowledge distillation algorithms. It would be valuable to investigate the performance of SoTeacher across a wider range of student and teacher model architectures, as well as different knowledge distillation techniques.
-
Computational Overhead: The addition of Lipschitz regularization and consistency regularization to the teacher training process may increase the computational complexity and training time compared to standard teacher training approaches. The researchers should further analyze the trade-offs between the performance gains and the increased computational requirements.
-
Real-world Deployment: The paper evaluates the SoTeacher method on benchmark datasets, but it would be important to assess its performance and practical applicability in real-world machine learning deployments, where the data and task characteristics may differ from the studied scenarios.
Despite these potential limitations, the SoTeacher approach represents a promising step forward in addressing the challenge of training effective teacher models for knowledge distillation, and the insights provided in the paper could inspire further research in this direction.
Conclusion
The research paper proposes a new method called SoTeacher for training teacher models in knowledge distillation tasks. By incorporating Lipschitz regularization and consistency regularization into the empirical risk minimization training process, SoTeacher aims to produce a teacher model that is specifically oriented towards improving the performance of the student model, rather than just maximizing the teacher's own accuracy.
The theoretical analysis and empirical evaluation presented in the paper provide strong evidence that the SoTeacher approach can consistently improve student model accuracy across various knowledge distillation algorithms and teacher-student pairs. This work represents an important step forward in addressing the challenge of effective teacher model training, which is crucial for the widespread adoption and practical deployment of knowledge distillation techniques in machine learning applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🎯
Tailoring Instructions to Student's Learning Levels Boosts Knowledge Distillation
Yuxin Ren, Zihan Zhong, Xingjian Shi, Yi Zhu, Chun Yuan, Mu Li
0
0
It has been commonly observed that a teacher model with superior performance does not necessarily result in a stronger student, highlighting a discrepancy between current teacher training practices and effective knowledge transfer. In order to enhance the guidance of the teacher training process, we introduce the concept of distillation influence to determine the impact of distillation from each training sample on the student's generalization ability. In this paper, we propose Learning Good Teacher Matters (LGTM), an efficient training technique for incorporating distillation influence into the teacher's learning process. By prioritizing samples that are likely to enhance the student's generalization ability, our LGTM outperforms 10 common knowledge distillation baselines on 6 text classification tasks in the GLUE benchmark.
5/16/2024
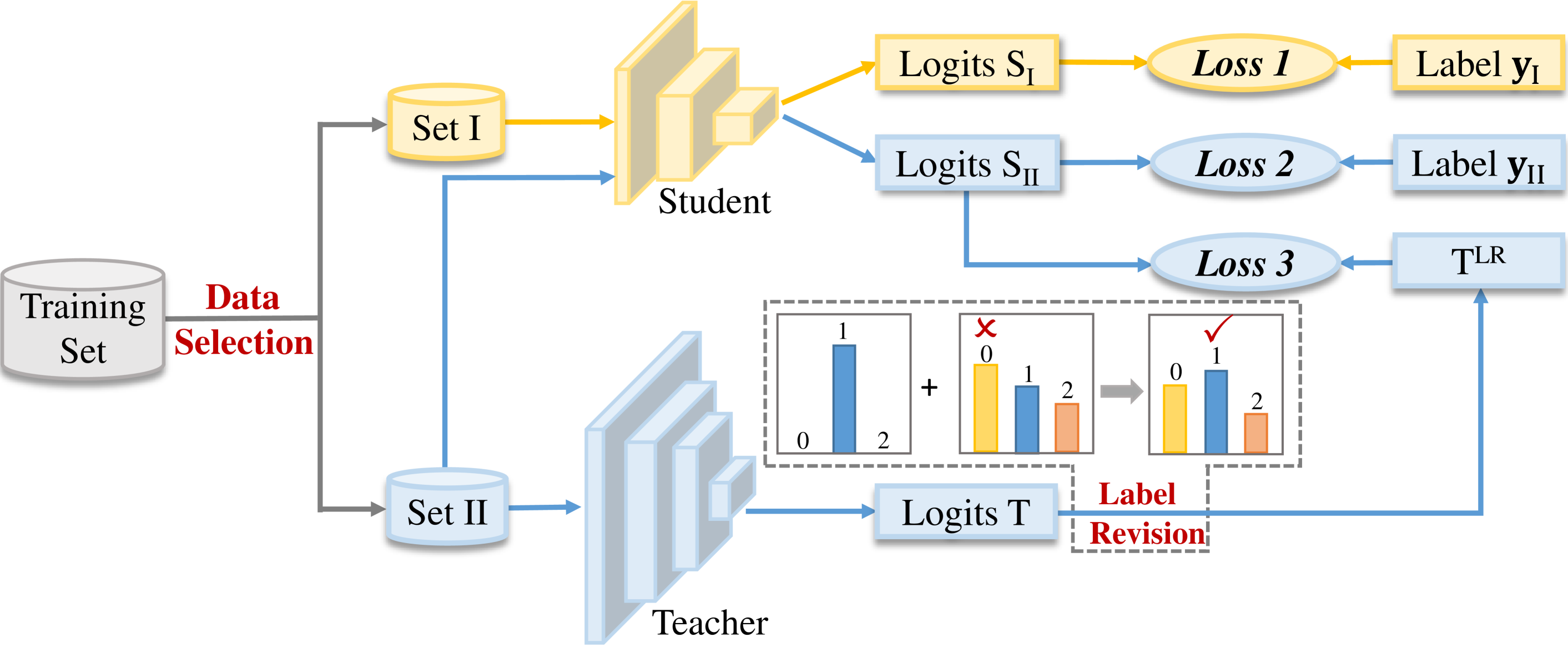
Improve Knowledge Distillation via Label Revision and Data Selection
Weichao Lan, Yiu-ming Cheung, Qing Xu, Buhua Liu, Zhikai Hu, Mengke Li, Zhenghua Chen
0
0
Knowledge distillation (KD) has become a widely used technique in the field of model compression, which aims to transfer knowledge from a large teacher model to a lightweight student model for efficient network development. In addition to the supervision of ground truth, the vanilla KD method regards the predictions of the teacher as soft labels to supervise the training of the student model. Based on vanilla KD, various approaches have been developed to further improve the performance of the student model. However, few of these previous methods have considered the reliability of the supervision from teacher models. Supervision from erroneous predictions may mislead the training of the student model. This paper therefore proposes to tackle this problem from two aspects: Label Revision to rectify the incorrect supervision and Data Selection to select appropriate samples for distillation to reduce the impact of erroneous supervision. In the former, we propose to rectify the teacher's inaccurate predictions using the ground truth. In the latter, we introduce a data selection technique to choose suitable training samples to be supervised by the teacher, thereby reducing the impact of incorrect predictions to some extent. Experiment results demonstrate the effectiveness of our proposed method, and show that our method can be combined with other distillation approaches, improving their performance.
4/8/2024
✨
Knowledge Distillation via the Target-aware Transformer
Sihao Lin, Hongwei Xie, Bing Wang, Kaicheng Yu, Xiaojun Chang, Xiaodan Liang, Gang Wang
0
0
Knowledge distillation becomes a de facto standard to improve the performance of small neural networks. Most of the previous works propose to regress the representational features from the teacher to the student in a one-to-one spatial matching fashion. However, people tend to overlook the fact that, due to the architecture differences, the semantic information on the same spatial location usually vary. This greatly undermines the underlying assumption of the one-to-one distillation approach. To this end, we propose a novel one-to-all spatial matching knowledge distillation approach. Specifically, we allow each pixel of the teacher feature to be distilled to all spatial locations of the student features given its similarity, which is generated from a target-aware transformer. Our approach surpasses the state-of-the-art methods by a significant margin on various computer vision benchmarks, such as ImageNet, Pascal VOC and COCOStuff10k. Code is available at https://github.com/sihaoevery/TaT.
4/9/2024

Robust Knowledge Distillation Based on Feature Variance Against Backdoored Teacher Model
Jinyin Chen, Xiaoming Zhao, Haibin Zheng, Xiao Li, Sheng Xiang, Haifeng Guo
0
0
Benefiting from well-trained deep neural networks (DNNs), model compression have captured special attention for computing resource limited equipment, especially edge devices. Knowledge distillation (KD) is one of the widely used compression techniques for edge deployment, by obtaining a lightweight student model from a well-trained teacher model released on public platforms. However, it has been empirically noticed that the backdoor in the teacher model will be transferred to the student model during the process of KD. Although numerous KD methods have been proposed, most of them focus on the distillation of a high-performing student model without robustness consideration. Besides, some research adopts KD techniques as effective backdoor mitigation tools, but they fail to perform model compression at the same time. Consequently, it is still an open problem to well achieve two objectives of robust KD, i.e., student model's performance and backdoor mitigation. To address these issues, we propose RobustKD, a robust knowledge distillation that compresses the model while mitigating backdoor based on feature variance. Specifically, RobustKD distinguishes the previous works in three key aspects: (1) effectiveness: by distilling the feature map of the teacher model after detoxification, the main task performance of the student model is comparable to that of the teacher model; (2) robustness: by reducing the characteristic variance between the teacher model and the student model, it mitigates the backdoor of the student model under backdoored teacher model scenario; (3) generic: RobustKD still has good performance in the face of multiple data models (e.g., WRN 28-4, Pyramid-200) and diverse DNNs (e.g., ResNet50, MobileNet).
6/6/2024