GPS-Gaussian: Generalizable Pixel-wise 3D Gaussian Splatting for Real-time Human Novel View Synthesis
2312.02155
0
0
🏷️
Abstract
We present a new approach, termed GPS-Gaussian, for synthesizing novel views of a character in a real-time manner. The proposed method enables 2K-resolution rendering under a sparse-view camera setting. Unlike the original Gaussian Splatting or neural implicit rendering methods that necessitate per-subject optimizations, we introduce Gaussian parameter maps defined on the source views and regress directly Gaussian Splatting properties for instant novel view synthesis without any fine-tuning or optimization. To this end, we train our Gaussian parameter regression module on a large amount of human scan data, jointly with a depth estimation module to lift 2D parameter maps to 3D space. The proposed framework is fully differentiable and experiments on several datasets demonstrate that our method outperforms state-of-the-art methods while achieving an exceeding rendering speed.
Create account to get full access
Overview
- This paper presents a new method called "GPS-Gaussian" for real-time synthesis of novel character views from sparse camera inputs.
- Unlike previous methods that require per-subject optimizations, the proposed approach uses Gaussian parameter maps to directly regress Gaussian Splatting properties for instant novel view synthesis.
- The method includes a depth estimation module to lift 2D parameter maps to 3D space, and is fully differentiable for end-to-end training.
- Experiments show the method outperforms state-of-the-art techniques while achieving high rendering speeds.
Plain English Explanation
The paper describes a new way to create realistic, high-resolution images of a character from a small number of camera views. This is useful for applications like video games or virtual reality, where you want to show a character from different angles without having to capture or model the character in 3D.
The key idea is to use a neural network to learn a set of "Gaussian parameters" that describe how to blend the available camera views together to synthesize new views. Unlike previous methods, this approach doesn't require any special tuning or optimization for each new character - the network can just directly apply the learned Gaussian parameters to generate the new views instantly.
To make this work, the method also includes a depth estimation component, which figures out the 3D structure of the character from the 2D camera views. This 3D information is then used to properly position the Gaussian blending parameters in 3D space.
The end result is a fast, flexible system that can generate high-quality novel views of characters, outperforming other state-of-the-art techniques. This could be very useful for creating realistic virtual environments and characters in real-time applications.
Technical Explanation
The proposed GPS-Gaussian method builds on previous work in Gaussian Splatting and neural implicit rendering techniques. However, unlike those approaches that require per-subject optimizations, the GPS-Gaussian framework introduces Gaussian parameter maps that can be directly regressed to enable instant novel view synthesis.
The core of the method is a neural network that takes in the available 2D camera views and estimates a set of Gaussian parameters that describe how to blend those views together. This avoids the need for slow, iterative optimization as in previous Gaussian Splatting or neural implicit rendering work.
To make the Gaussian parameters meaningful in 3D space, the method also includes a depth estimation module. This lifts the 2D parameter maps into 3D, allowing the Gaussian splatting to be properly positioned and oriented.
The full GPS-Gaussian pipeline is end-to-end differentiable, enabling joint training of the Gaussian parameter regression and depth estimation components. Experiments on several datasets show that this approach outperforms state-of-the-art methods like GS-SLAM while achieving real-time rendering speeds.
Critical Analysis
The paper presents a compelling approach for high-quality, real-time novel view synthesis of characters. The use of learned Gaussian parameter maps is a clever way to avoid the per-subject optimization required by prior methods, making the system much more flexible and practical.
One potential limitation is that the method was only evaluated on human characters, and it's unclear how well it would generalize to other types of subjects. The paper also does not provide much insight into the specific architectural choices or training process for the neural network components.
Additionally, while the rendering speed is impressive, the quality of the synthesized views is not compared to ground truth data, making it difficult to fully assess the fidelity of the approach. Further evaluation of the visual quality and potential artifacts would be helpful.
Overall, the GPS-Gaussian method seems like a promising direction for real-time character rendering, but additional research is needed to better understand its limitations and broader applicability.
Conclusion
This paper introduces a novel approach called GPS-Gaussian that enables real-time synthesis of high-resolution novel views of characters from sparse camera inputs. By learning Gaussian parameter maps instead of requiring per-subject optimization, the method achieves instant novel view generation without sacrificing quality.
The inclusion of a depth estimation module to lift the 2D parameter maps into 3D space is a key innovation that allows the Gaussian splatting to be properly positioned. Experiments demonstrate that this end-to-end differentiable framework outperforms previous state-of-the-art techniques while running in real-time.
If further validated, this work could have significant impact on applications like video games, virtual reality, and other interactive 3D environments where realistic character rendering is essential. The flexibility and speed of the GPS-Gaussian approach make it a promising direction for the future of real-time character synthesis.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
FSGS: Real-Time Few-shot View Synthesis using Gaussian Splatting
Zehao Zhu, Zhiwen Fan, Yifan Jiang, Zhangyang Wang
0
0
Novel view synthesis from limited observations remains an important and persistent task. However, high efficiency in existing NeRF-based few-shot view synthesis is often compromised to obtain an accurate 3D representation. To address this challenge, we propose a few-shot view synthesis framework based on 3D Gaussian Splatting that enables real-time and photo-realistic view synthesis with as few as three training views. The proposed method, dubbed FSGS, handles the extremely sparse initialized SfM points with a thoughtfully designed Gaussian Unpooling process. Our method iteratively distributes new Gaussians around the most representative locations, subsequently infilling local details in vacant areas. We also integrate a large-scale pre-trained monocular depth estimator within the Gaussians optimization process, leveraging online augmented views to guide the geometric optimization towards an optimal solution. Starting from sparse points observed from limited input viewpoints, our FSGS can accurately grow into unseen regions, comprehensively covering the scene and boosting the rendering quality of novel views. Overall, FSGS achieves state-of-the-art performance in both accuracy and rendering efficiency across diverse datasets, including LLFF, Mip-NeRF360, and Blender. Project website: https://zehaozhu.github.io/FSGS/.
6/18/2024

GaSpCT: Gaussian Splatting for Novel CT Projection View Synthesis
Emmanouil Nikolakakis, Utkarsh Gupta, Jonathan Vengosh, Justin Bui, Razvan Marinescu
0
0
We present GaSpCT, a novel view synthesis and 3D scene representation method used to generate novel projection views for Computer Tomography (CT) scans. We adapt the Gaussian Splatting framework to enable novel view synthesis in CT based on limited sets of 2D image projections and without the need for Structure from Motion (SfM) methodologies. Therefore, we reduce the total scanning duration and the amount of radiation dose the patient receives during the scan. We adapted the loss function to our use-case by encouraging a stronger background and foreground distinction using two sparsity promoting regularizers: a beta loss and a total variation (TV) loss. Finally, we initialize the Gaussian locations across the 3D space using a uniform prior distribution of where the brain's positioning would be expected to be within the field of view. We evaluate the performance of our model using brain CT scans from the Parkinson's Progression Markers Initiative (PPMI) dataset and demonstrate that the rendered novel views closely match the original projection views of the simulated scan, and have better performance than other implicit 3D scene representations methodologies. Furthermore, we empirically observe reduced training time compared to neural network based image synthesis for sparse-view CT image reconstruction. Finally, the memory requirements of the Gaussian Splatting representations are reduced by 17% compared to the equivalent voxel grid image representations.
4/5/2024

FreeSplat: Generalizable 3D Gaussian Splatting Towards Free-View Synthesis of Indoor Scenes
Yunsong Wang, Tianxin Huang, Hanlin Chen, Gim Hee Lee
0
0
Empowering 3D Gaussian Splatting with generalization ability is appealing. However, existing generalizable 3D Gaussian Splatting methods are largely confined to narrow-range interpolation between stereo images due to their heavy backbones, thus lacking the ability to accurately localize 3D Gaussian and support free-view synthesis across wide view range. In this paper, we present a novel framework FreeSplat that is capable of reconstructing geometrically consistent 3D scenes from long sequence input towards free-view synthesis.Specifically, we firstly introduce Low-cost Cross-View Aggregation achieved by constructing adaptive cost volumes among nearby views and aggregating features using a multi-scale structure. Subsequently, we present the Pixel-wise Triplet Fusion to eliminate redundancy of 3D Gaussians in overlapping view regions and to aggregate features observed across multiple views. Additionally, we propose a simple but effective free-view training strategy that ensures robust view synthesis across broader view range regardless of the number of views. Our empirical results demonstrate state-of-the-art novel view synthesis peformances in both novel view rendered color maps quality and depth maps accuracy across different numbers of input views. We also show that FreeSplat performs inference more efficiently and can effectively reduce redundant Gaussians, offering the possibility of feed-forward large scene reconstruction without depth priors.
6/11/2024
SparseGS: Real-Time 360{deg} Sparse View Synthesis using Gaussian Splatting
Haolin Xiong, Sairisheek Muttukuru, Rishi Upadhyay, Pradyumna Chari, Achuta Kadambi
0
0
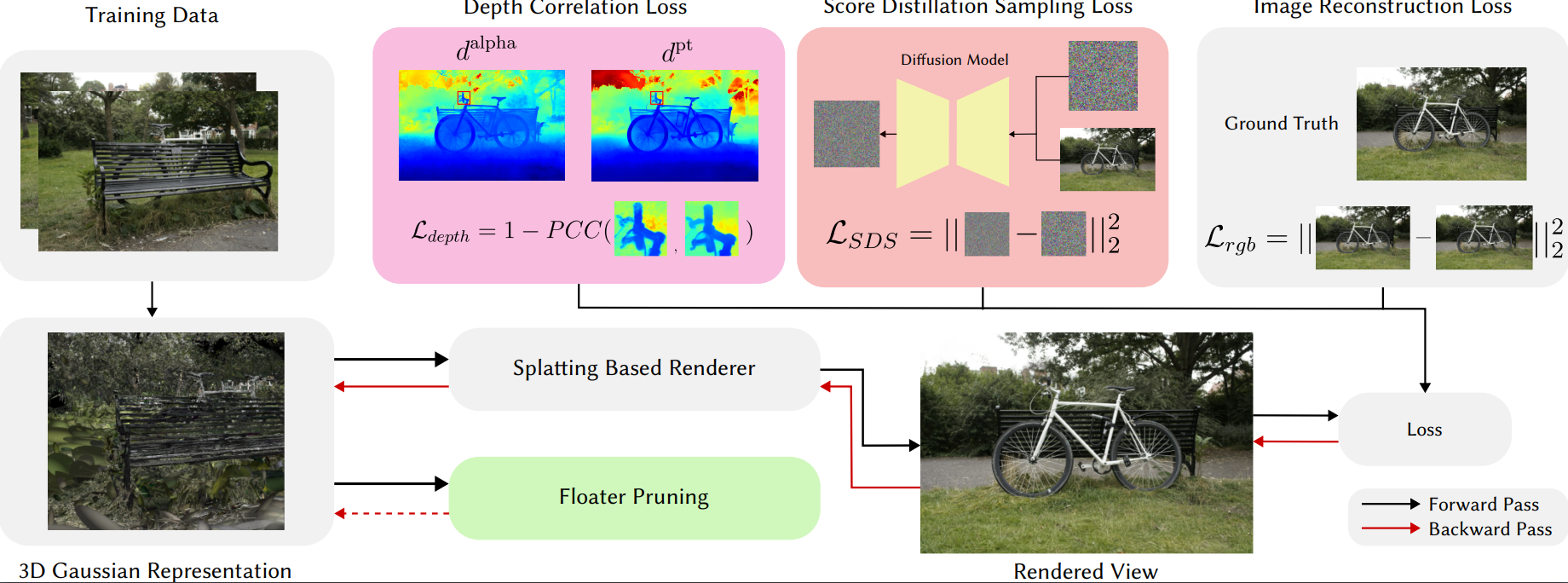
The problem of novel view synthesis has grown significantly in popularity recently with the introduction of Neural Radiance Fields (NeRFs) and other implicit scene representation methods. A recent advance, 3D Gaussian Splatting (3DGS), leverages an explicit representation to achieve real-time rendering with high-quality results. However, 3DGS still requires an abundance of training views to generate a coherent scene representation. In few shot settings, similar to NeRF, 3DGS tends to overfit to training views, causing background collapse and excessive floaters, especially as the number of training views are reduced. We propose a method to enable training coherent 3DGS-based radiance fields of 360-degree scenes from sparse training views. We integrate depth priors with generative and explicit constraints to reduce background collapse, remove floaters, and enhance consistency from unseen viewpoints. Experiments show that our method outperforms base 3DGS by 6.4% in LPIPS and by 12.2% in PSNR, and NeRF-based methods by at least 17.6% in LPIPS on the MipNeRF-360 dataset with substantially less training and inference cost.
5/14/2024