Gradient Inversion of Federated Diffusion Models

0

Sign in to get full access
Overview
- This research paper explores a technique called "gradient inversion" that can be used to attack federated diffusion models, which are a type of machine learning model used in various applications.
- Federated learning is a technique where a model is trained across multiple devices or data sources without the need to share the underlying data.
- The paper presents a gradient inversion attack that can be used to recover the training data from the gradients communicated during the federated learning process.
- The authors also discuss potential mitigation strategies and the broader implications of gradient inversion attacks on the security and privacy of federated learning systems.
Plain English Explanation
Imagine you have a group of people who want to train a machine learning model, but they don't want to share their private data with each other. They use a technique called federated learning where the model is trained on each person's device, and only the changes to the model (called gradients) are shared. This way, the private data never leaves the device.
However, the researchers in this paper found a way to "invert" or undo these gradients to try to figure out the original training data. This is called a "gradient inversion attack". By doing this, they can potentially recover the private data that the participants were trying to keep secret.
The researchers demonstrate this attack on a specific type of machine learning model called a "diffusion model", which is a powerful tool for generating realistic-looking images. They show that their gradient inversion attack can be used to recover the images that were used to train the diffusion model, even though the original data was never shared.
The paper also discusses ways to try to protect against these kinds of attacks, such as adding noise to the gradients or changing the way the diffusion model is trained. Overall, this research highlights an important security and privacy concern with federated learning that needs to be addressed as these technologies become more widely used.
Technical Explanation
The researchers present a gradient inversion attack that can be used to recover training data from federated diffusion models. Diffusion models are a type of generative model that has shown impressive performance in tasks like image generation.
In federated learning, the diffusion model is trained across multiple devices or data sources without the need to share the underlying training data. Instead, only the gradients (the changes to the model during training) are communicated between the devices and a central server.
The key idea behind the gradient inversion attack is to use an optimization-based approach to recover the training data from these shared gradients. The researchers formulate this as an inverse problem, where they try to find the input data that would have produced the observed gradients.
They demonstrate this attack on several federated diffusion model setups, including both centralized and decentralized configurations. The results show that the gradient inversion attack can effectively recover high-fidelity images that were used to train the diffusion models, even when the original data was never shared.
The researchers also explore potential mitigation strategies, such as adding differential privacy to the gradients or using more secure aggregation techniques. However, they note that these defenses come with their own challenges and trade-offs.
Critical Analysis
The gradient inversion attack presented in this paper highlights a significant security and privacy concern with federated learning systems, particularly when used in sensitive domains like healthcare or finance. While federated learning is intended to protect the privacy of the training data, this research shows that the shared gradients can potentially be exploited to recover the original data.
One limitation of the study is that it focuses solely on diffusion models, and it's unclear how the gradient inversion attack would perform on other types of machine learning models used in federated learning. Additionally, the researchers only evaluate their attack on relatively small-scale datasets, and it's uncertain how well it would scale to larger, more complex models and datasets.
Furthermore, the proposed mitigation strategies, such as adding differential privacy, come with their own drawbacks. Applying these techniques may impact the performance or utility of the federated learning system, and there are still open questions about their effectiveness against sophisticated gradient inversion attacks.
Despite these limitations, this research is an important contribution to the field of federated learning security. It serves as a wake-up call for the research community to continue exploring robust defenses against gradient inversion and other model inversion attacks. As federated learning becomes more widely adopted, ensuring the privacy and security of these systems will be crucial.
Conclusion
The gradient inversion attack presented in this paper demonstrates a significant vulnerability in federated diffusion models, where the shared gradients can be exploited to recover the original training data. This highlights the need for continued research into the security and privacy implications of federated learning, as these techniques become more widely adopted.
While the researchers propose several potential mitigation strategies, such as differential privacy and secure aggregation, these approaches come with their own challenges and trade-offs. Ultimately, ensuring the privacy and security of federated learning systems will require a multi-pronged effort, involving advances in both technical and policy-based solutions.
As the use of federated learning expands into sensitive domains, such as healthcare and finance, the findings of this paper underscore the critical importance of addressing these security concerns. By continuing to explore and address the vulnerabilities of federated learning, the research community can help unlock the full potential of this powerful technique while safeguarding the privacy and security of the individuals and organizations involved.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Gradient Inversion of Federated Diffusion Models
Jiyue Huang, Chi Hong, Lydia Y. Chen, Stefanie Roos
Diffusion models are becoming defector generative models, which generate exceptionally high-resolution image data. Training effective diffusion models require massive real data, which is privately owned by distributed parties. Each data party can collaboratively train diffusion models in a federated learning manner by sharing gradients instead of the raw data. In this paper, we study the privacy leakage risk of gradient inversion attacks. First, we design a two-phase fusion optimization, GIDM, to leverage the well-trained generative model itself as prior knowledge to constrain the inversion search (latent) space, followed by pixel-wise fine-tuning. GIDM is shown to be able to reconstruct images almost identical to the original ones. Considering a more privacy-preserving training scenario, we then argue that locally initialized private training noise $epsilon$ and sampling step t may raise additional challenges for the inversion attack. To solve this, we propose a triple-optimization GIDM+ that coordinates the optimization of the unknown data, $epsilon$ and $t$. Our extensive evaluation results demonstrate the vulnerability of sharing gradient for data protection of diffusion models, even high-resolution images can be reconstructed with high quality.
Read more6/3/2024

0
Exploring User-level Gradient Inversion with a Diffusion Prior
Zhuohang Li, Andrew Lowy, Jing Liu, Toshiaki Koike-Akino, Bradley Malin, Kieran Parsons, Ye Wang
We explore user-level gradient inversion as a new attack surface in distributed learning. We first investigate existing attacks on their ability to make inferences about private information beyond training data reconstruction. Motivated by the low reconstruction quality of existing methods, we propose a novel gradient inversion attack that applies a denoising diffusion model as a strong image prior in order to enhance recovery in the large batch setting. Unlike traditional attacks, which aim to reconstruct individual samples and suffer at large batch and image sizes, our approach instead aims to recover a representative image that captures the sensitive shared semantic information corresponding to the underlying user. Our experiments with face images demonstrate the ability of our methods to recover realistic facial images along with private user attributes.
Read more9/12/2024
📈
0
Model Inversion Attacks Through Target-Specific Conditional Diffusion Models
Ouxiang Li, Yanbin Hao, Zhicai Wang, Bin Zhu, Shuo Wang, Zaixi Zhang, Fuli Feng
Model inversion attacks (MIAs) aim to reconstruct private images from a target classifier's training set, thereby raising privacy concerns in AI applications. Previous GAN-based MIAs tend to suffer from inferior generative fidelity due to GAN's inherent flaws and biased optimization within latent space. To alleviate these issues, leveraging on diffusion models' remarkable synthesis capabilities, we propose Diffusion-based Model Inversion (Diff-MI) attacks. Specifically, we introduce a novel target-specific conditional diffusion model (CDM) to purposely approximate target classifier's private distribution and achieve superior accuracy-fidelity balance. Our method involves a two-step learning paradigm. Step-1 incorporates the target classifier into the entire CDM learning under a pretrain-then-finetune fashion, with creating pseudo-labels as model conditions in pretraining and adjusting specified layers with image predictions in fine-tuning. Step-2 presents an iterative image reconstruction method, further enhancing the attack performance through a combination of diffusion priors and target knowledge. Additionally, we propose an improved max-margin loss that replaces the hard max with top-k maxes, fully leveraging feature information and soft labels from the target classifier. Extensive experiments demonstrate that Diff-MI significantly improves generative fidelity with an average decrease of 20% in FID while maintaining competitive attack accuracy compared to state-of-the-art methods across various datasets and models. We will release our code and models.
Read more7/17/2024
0
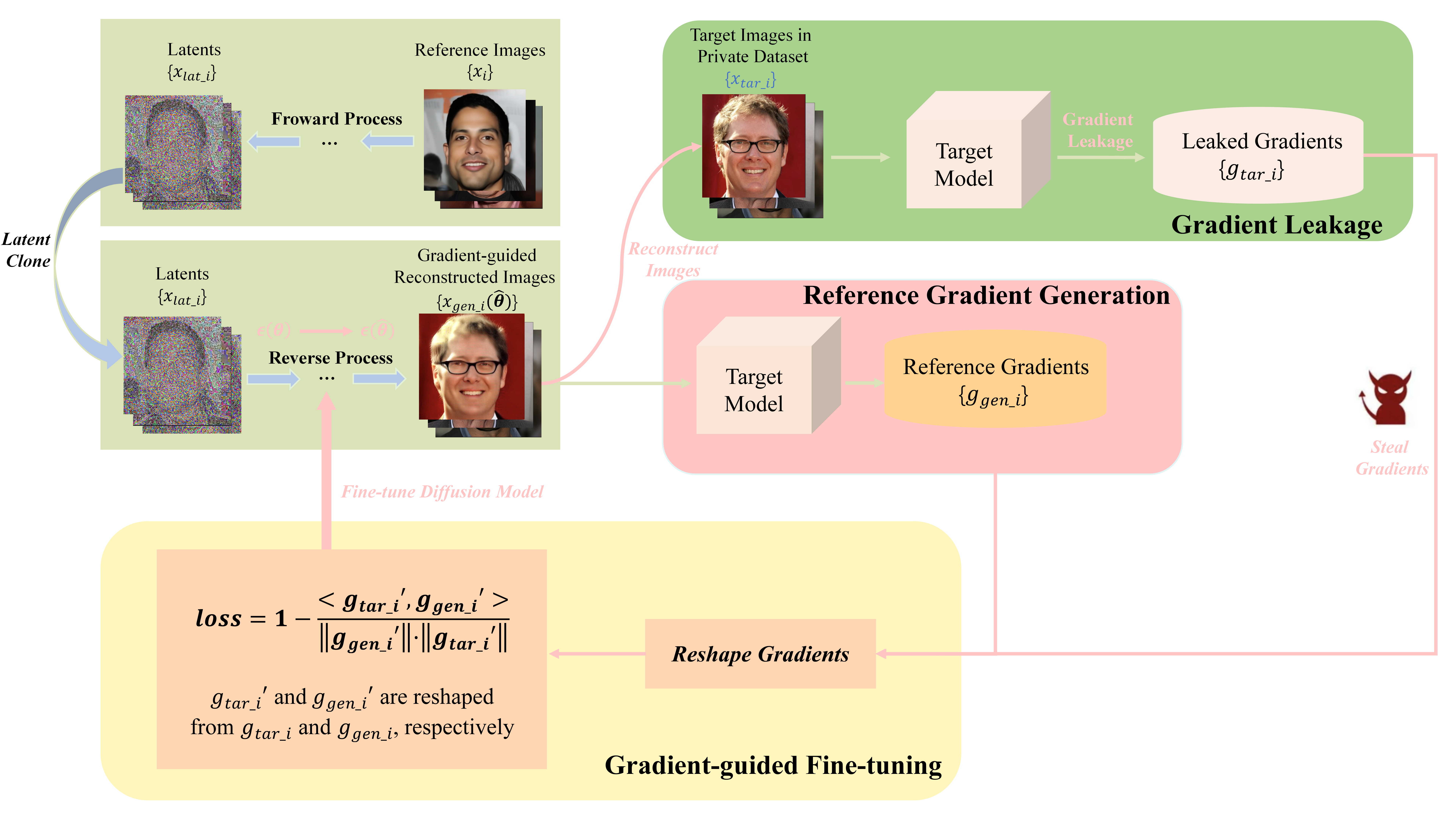
Is Diffusion Model Safe? Severe Data Leakage via Gradient-Guided Diffusion Model
Jiayang Meng, Tao Huang, Hong Chen, Cuiping Li
Gradient leakage has been identified as a potential source of privacy breaches in modern image processing systems, where the adversary can completely reconstruct the training images from leaked gradients. However, existing methods are restricted to reconstructing low-resolution images where data leakage risks of image processing systems are not sufficiently explored. In this paper, by exploiting diffusion models, we propose an innovative gradient-guided fine-tuning method and introduce a new reconstruction attack that is capable of stealing private, high-resolution images from image processing systems through leaked gradients where severe data leakage encounters. Our attack method is easy to implement and requires little prior knowledge. The experimental results indicate that current reconstruction attacks can steal images only up to a resolution of $128 times 128$ pixels, while our attack method can successfully recover and steal images with resolutions up to $512 times 512$ pixels. Our attack method significantly outperforms the SOTA attack baselines in terms of both pixel-wise accuracy and time efficiency of image reconstruction. Furthermore, our attack can render differential privacy ineffective to some extent.
Read more6/17/2024