Graph-based multi-Feature fusion method for speech emotion recognition
2406.07437
0
0
Abstract
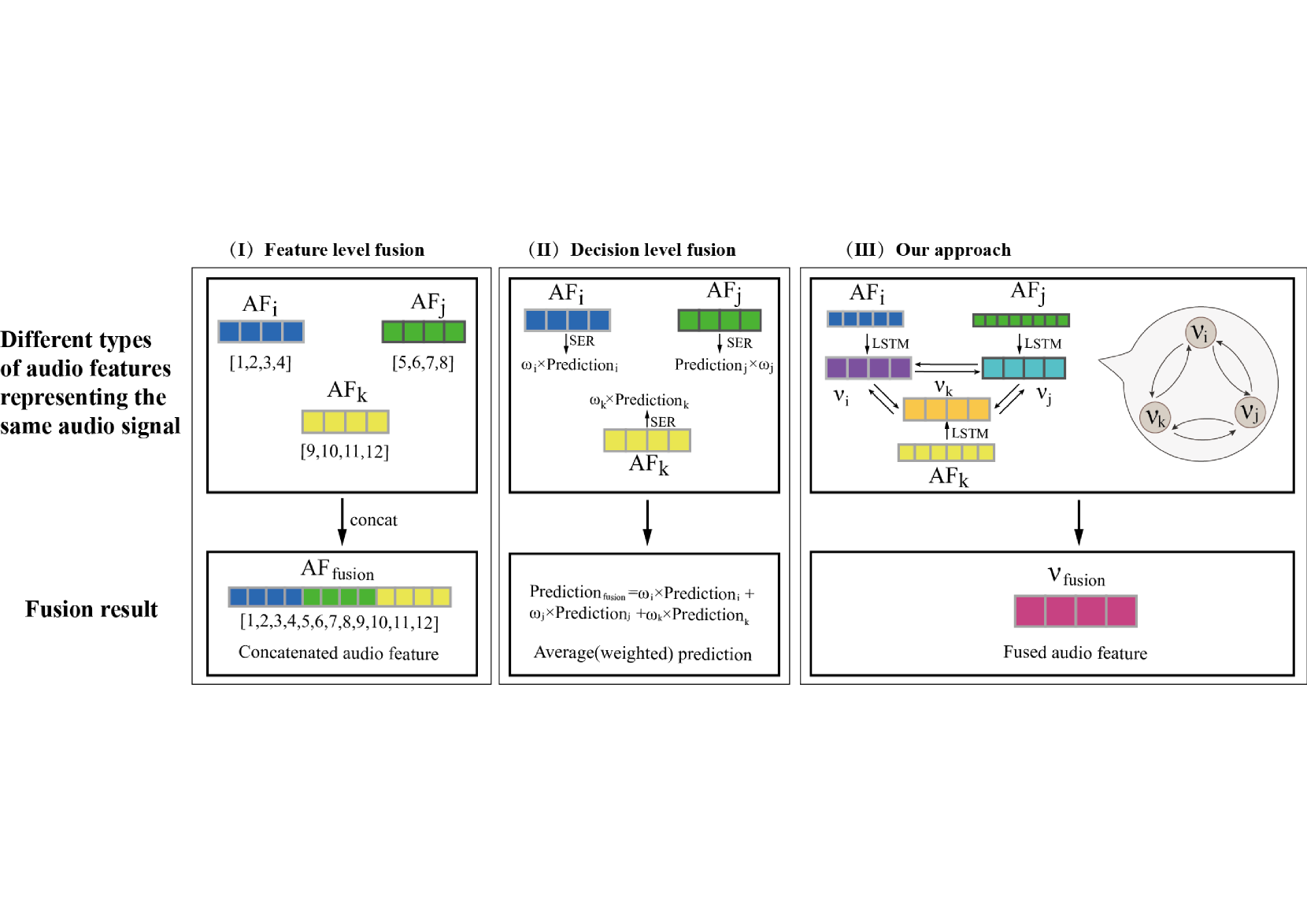
Exploring proper way to conduct multi-speech feature fusion for cross-corpus speech emotion recognition is crucial as different speech features could provide complementary cues reflecting human emotion status. While most previous approaches only extract a single speech feature for emotion recognition, existing fusion methods such as concatenation, parallel connection, and splicing ignore heterogeneous patterns in the interaction between features and features, resulting in performance of existing systems. In this paper, we propose a novel graph-based fusion method to explicitly model the relationships between every pair of speech features. Specifically, we propose a multi-dimensional edge features learning strategy called Graph-based multi-Feature fusion method for speech emotion recognition. It represents each speech feature as a node and learns multi-dimensional edge features to explicitly describe the relationship between each feature-feature pair in the context of emotion recognition. This way, the learned multi-dimensional edge features encode speech feature-level information from both the vertex and edge dimensions. Our Approach consists of three modules: an Audio Feature Generation(AFG)module, an Audio-Feature Multi-dimensional Edge Feature(AMEF) module and a Speech Emotion Recognition (SER) module. The proposed methodology yielded satisfactory outcomes on the SEWA dataset. Furthermore, the method demonstrated enhanced performance compared to the baseline in the AVEC 2019 Workshop and Challenge. We used data from two cultures as our training and validation sets: two cultures containing German and Hungarian on the SEWA dataset, the CCC scores for German are improved by 17.28% for arousal and 7.93% for liking. The outcomes of our methodology demonstrate a 13% improvement over alternative fusion techniques, including those employing one dimensional edge-based feature fusion approach.
Create account to get full access
Overview
- This paper presents a graph-based multi-feature fusion method for improved speech emotion recognition.
- The approach combines various acoustic, linguistic, and paralinguistic features to capture a more comprehensive representation of emotional speech.
- The authors leverage graph neural networks to model the complex relationships between these diverse features and effectively fuse the information for emotion classification.
Plain English Explanation
Speech emotion recognition is the task of identifying the emotional state of a person from their speech. This is an important capability for various applications, such as improving conversational AI or providing personalized digital assistants.
The authors of this paper recognized that existing approaches often rely on a limited set of features, which may not fully capture the complexity of emotional speech. To address this, they developed a new method that combines a wide range of acoustic, linguistic, and paralinguistic features, such as pitch, energy, and lexical cues.
The key innovation is the use of graph neural networks to model the relationships between these diverse features. By representing the features as nodes in a graph and learning the connections between them, the model can better understand how different aspects of speech contribute to the overall emotional expression. This iterative feature boosting approach allows the model to capture more nuanced and comprehensive emotional cues compared to traditional methods.
Technical Explanation
The proposed method, called Graph-based multi-Feature Fusion (GFF), leverages a graph neural network architecture to effectively integrate various acoustic, linguistic, and paralinguistic features for speech emotion recognition.
The authors first extract a comprehensive set of features from the speech signals, including Low-Level Descriptors (LLDs) such as pitch, energy, and spectral characteristics, as well as higher-level features like lexical and prosodic cues. These features are then represented as nodes in a graph, with edges connecting related features based on their correlation and semantic associations.
The graph neural network learns to model the complex relationships between the different features, capturing both their individual contributions and their collective interactions in expressing emotional states. This allows the model to learn a more holistic and adaptive representation of emotional speech compared to traditional feature concatenation or fusion approaches.
The authors evaluate their method on several benchmark speech emotion recognition datasets and demonstrate significant improvements in classification accuracy compared to state-of-the-art baselines. The graph-based fusion approach proves to be particularly effective in scenarios with diverse and heterogeneous feature sets, highlighting its ability to leverage the complementary information provided by different modalities.
Critical Analysis
The paper presents a well-designed and empirically validated approach for improving speech emotion recognition through the use of graph-based multi-feature fusion. The authors' insights on the importance of capturing the complex relationships between diverse emotional cues are compelling and are supported by the experimental results.
However, the study does not thoroughly address the potential limitations of the proposed method. For example, the authors do not discuss the computational complexity of the graph neural network architecture or the scalability of the approach to large-scale, real-world applications. Additionally, the paper lacks a detailed analysis of the model's interpretability and the ability to explain the reasoning behind its emotion predictions, which is an important consideration for many practical use cases.
Further research could explore ways to optimize the graph-based fusion approach for efficiency and enhance its explainability, as well as investigate its performance in more diverse and challenging speech emotion recognition scenarios.
Conclusion
This paper presents a novel graph-based multi-feature fusion method for improving speech emotion recognition. By leveraging graph neural networks to model the complex relationships between a comprehensive set of acoustic, linguistic, and paralinguistic features, the proposed approach can capture a more holistic representation of emotional speech, leading to significant performance gains over traditional methods.
The authors' insights on the importance of feature fusion and the advantages of graph-based modeling demonstrate the potential of this approach to advance the state-of-the-art in speech emotion recognition and contribute to the development of more natural and empathetic conversational AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Revisiting Multimodal Emotion Recognition in Conversation from the Perspective of Graph Spectrum
Tao Meng, Fuchen Zhang, Yuntao Shou, Wei Ai, Nan Yin, Keqin Li
0
0
Efficiently capturing consistent and complementary semantic features in a multimodal conversation context is crucial for Multimodal Emotion Recognition in Conversation (MERC). Existing methods mainly use graph structures to model dialogue context semantic dependencies and employ Graph Neural Networks (GNN) to capture multimodal semantic features for emotion recognition. However, these methods are limited by some inherent characteristics of GNN, such as over-smoothing and low-pass filtering, resulting in the inability to learn long-distance consistency information and complementary information efficiently. Since consistency and complementarity information correspond to low-frequency and high-frequency information, respectively, this paper revisits the problem of multimodal emotion recognition in conversation from the perspective of the graph spectrum. Specifically, we propose a Graph-Spectrum-based Multimodal Consistency and Complementary collaborative learning framework GS-MCC. First, GS-MCC uses a sliding window to construct a multimodal interaction graph to model conversational relationships and uses efficient Fourier graph operators to extract long-distance high-frequency and low-frequency information, respectively. Then, GS-MCC uses contrastive learning to construct self-supervised signals that reflect complementarity and consistent semantic collaboration with high and low-frequency signals, thereby improving the ability of high and low-frequency information to reflect real emotions. Finally, GS-MCC inputs the collaborative high and low-frequency information into the MLP network and softmax function for emotion prediction. Extensive experiments have proven the superiority of the GS-MCC architecture proposed in this paper on two benchmark data sets.
5/6/2024

Feature Fusion Based on Mutual-Cross-Attention Mechanism for EEG Emotion Recognition
Yimin Zhao, Jin Gu
0
0
An objective and accurate emotion diagnostic reference is vital to psychologists, especially when dealing with patients who are difficult to communicate with for pathological reasons. Nevertheless, current systems based on Electroencephalography (EEG) data utilized for sentiment discrimination have some problems, including excessive model complexity, mediocre accuracy, and limited interpretability. Consequently, we propose a novel and effective feature fusion mechanism named Mutual-Cross-Attention (MCA). Combining with a specially customized 3D Convolutional Neural Network (3D-CNN), this purely mathematical mechanism adeptly discovers the complementary relationship between time-domain and frequency-domain features in EEG data. Furthermore, the new designed Channel-PSD-DE 3D feature also contributes to the high performance. The proposed method eventually achieves 99.49% (valence) and 99.30% (arousal) accuracy on DEAP dataset.
6/21/2024
MF-AED-AEC: Speech Emotion Recognition by Leveraging Multimodal Fusion, Asr Error Detection, and Asr Error Correction
Jiajun He, Xiaohan Shi, Xingfeng Li, Tomoki Toda
0
0
The prevalent approach in speech emotion recognition (SER) involves integrating both audio and textual information to comprehensively identify the speaker's emotion, with the text generally obtained through automatic speech recognition (ASR). An essential issue of this approach is that ASR errors from the text modality can worsen the performance of SER. Previous studies have proposed using an auxiliary ASR error detection task to adaptively assign weights of each word in ASR hypotheses. However, this approach has limited improvement potential because it does not address the coherence of semantic information in the text. Additionally, the inherent heterogeneity of different modalities leads to distribution gaps between their representations, making their fusion challenging. Therefore, in this paper, we incorporate two auxiliary tasks, ASR error detection (AED) and ASR error correction (AEC), to enhance the semantic coherence of ASR text, and further introduce a novel multi-modal fusion (MF) method to learn shared representations across modalities. We refer to our method as MF-AED-AEC. Experimental results indicate that MF-AED-AEC significantly outperforms the baseline model by a margin of 4.1%.
5/29/2024
🗣️
Adaptive Speech Emotion Representation Learning Based On Dynamic Graph
Yingxue Gao, Huan Zhao, Zixing Zhang
0
0
Graph representation learning has become a hot research topic due to its powerful nonlinear fitting capability in extracting representative node embeddings. However, for sequential data such as speech signals, most traditional methods merely focus on the static graph created within a sequence, and largely overlook the intrinsic evolving patterns of these data. This may reduce the efficiency of graph representation learning for sequential data. For this reason, we propose an adaptive graph representation learning method based on dynamically evolved graphs, which are consecutively constructed on a series of subsequences segmented by a sliding window. In doing this, it is better to capture local and global context information within a long sequence. Moreover, we introduce a weighted approach to update the node representation rather than the conventional average one, where the weights are calculated by a novel matrix computation based on the degree of neighboring nodes. Finally, we construct a learnable graph convolutional layer that combines the graph structure loss and classification loss to optimize the graph structure. To verify the effectiveness of the proposed method, we conducted experiments for speech emotion recognition on the IEMOCAP and RAVDESS datasets. Experimental results show that the proposed method outperforms the latest (non-)graph-based models.
5/8/2024