Feature Fusion Based on Mutual-Cross-Attention Mechanism for EEG Emotion Recognition
2406.14014
0
0

Abstract
An objective and accurate emotion diagnostic reference is vital to psychologists, especially when dealing with patients who are difficult to communicate with for pathological reasons. Nevertheless, current systems based on Electroencephalography (EEG) data utilized for sentiment discrimination have some problems, including excessive model complexity, mediocre accuracy, and limited interpretability. Consequently, we propose a novel and effective feature fusion mechanism named Mutual-Cross-Attention (MCA). Combining with a specially customized 3D Convolutional Neural Network (3D-CNN), this purely mathematical mechanism adeptly discovers the complementary relationship between time-domain and frequency-domain features in EEG data. Furthermore, the new designed Channel-PSD-DE 3D feature also contributes to the high performance. The proposed method eventually achieves 99.49% (valence) and 99.30% (arousal) accuracy on DEAP dataset.
Create account to get full access
Overview
- The paper presents a novel feature fusion approach based on a mutual-cross-attention mechanism for EEG-based emotion recognition.
- It combines features from different neural network layers using a mutual-cross-attention mechanism to capture both local and global information.
- The proposed method outperforms state-of-the-art approaches on benchmark EEG emotion recognition datasets.
Plain English Explanation
The paper describes a new way to combine different types of features from brain activity data (EEG) to recognize emotions. Typically, machine learning models for emotion recognition from EEG data rely on features extracted from different layers of a neural network. However, these features may not fully capture both the local details and the broader context needed for accurate emotion recognition.
To address this, the researchers developed a "mutual-cross-attention mechanism" that allows the model to dynamically weigh and fuse the most relevant features from different layers. This helps the model understand both the fine-grained details and the overall patterns in the EEG data, leading to better emotion recognition performance.
The key idea is to have the different feature representations "attend" to each other, allowing them to exchange and combine information in an intelligent way. This mutual attention process enables the model to focus on the most important aspects of the data for the emotion recognition task.
The researchers evaluated their approach on standard EEG emotion recognition benchmarks and found that it outperformed other state-of-the-art methods. This suggests that the mutual-cross-attention mechanism is an effective way to leverage the complementary strengths of different features for improved emotion recognition from brain activity data.
Technical Explanation
The paper proposes a feature fusion approach based on a mutual-cross-attention mechanism for EEG-based emotion recognition. The core idea is to combine features from different layers of a 3D convolutional neural network (3D-CNN) encoder using a mutual-cross-attention mechanism.
The 3D-CNN encoder extracts low-level, mid-level, and high-level features from the input EEG data. These features are then fed into the mutual-cross-attention module, which learns to dynamically weight and fuse the most relevant features from different layers. This allows the model to capture both local details and global context, leading to improved emotion recognition performance.
The mutual-cross-attention mechanism works by having each feature representation attend to and exchange information with the other feature representations. This mutual attention process enables the model to focus on the most important aspects of the data for the emotion recognition task.
The researchers evaluated their approach on two benchmark EEG emotion recognition datasets and found that it outperformed state-of-the-art methods, including joint contrastive learning and feature alignment, multi-modal mood reader, and graph-based multi-feature fusion techniques.
Critical Analysis
The paper presents a promising approach for improving EEG-based emotion recognition by leveraging a mutual-cross-attention mechanism to effectively fuse features from different neural network layers. The key strength of the method is its ability to capture both local details and global context, which is crucial for accurate emotion recognition from complex brain activity data.
However, the paper does not provide a detailed analysis of the limitations of the proposed approach. For example, it would be helpful to understand how the method performs under different EEG data conditions, such as varying levels of noise or subject-specific variations. Additionally, the paper does not discuss the computational complexity of the mutual-cross-attention mechanism and how it might scale with larger or more complex EEG datasets.
Further research could also explore the integration of this feature fusion approach with other multimodal emotion recognition techniques, such as combining EEG data with other physiological signals or contextual information. This could lead to even more robust and comprehensive emotion recognition systems.
Conclusion
The proposed feature fusion approach based on a mutual-cross-attention mechanism demonstrates promising results for EEG-based emotion recognition. By dynamically combining low-level, mid-level, and high-level features, the model is able to capture both local details and global context, leading to improved performance over state-of-the-art methods.
This work highlights the importance of effective feature fusion for complex machine learning tasks like emotion recognition from brain activity data. The mutual-cross-attention mechanism provides a novel and effective way to leverage the complementary strengths of different feature representations, which could have broader applications in other areas of multimodal learning and analysis.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Joint Contrastive Learning with Feature Alignment for Cross-Corpus EEG-based Emotion Recognition
Qile Liu, Zhihao Zhou, Jiyuan Wang, Zhen Liang
0
0
The integration of human emotions into multimedia applications shows great potential for enriching user experiences and enhancing engagement across various digital platforms. Unlike traditional methods such as questionnaires, facial expressions, and voice analysis, brain signals offer a more direct and objective understanding of emotional states. However, in the field of electroencephalography (EEG)-based emotion recognition, previous studies have primarily concentrated on training and testing EEG models within a single dataset, overlooking the variability across different datasets. This oversight leads to significant performance degradation when applying EEG models to cross-corpus scenarios. In this study, we propose a novel Joint Contrastive learning framework with Feature Alignment (JCFA) to address cross-corpus EEG-based emotion recognition. The JCFA model operates in two main stages. In the pre-training stage, a joint domain contrastive learning strategy is introduced to characterize generalizable time-frequency representations of EEG signals, without the use of labeled data. It extracts robust time-based and frequency-based embeddings for each EEG sample, and then aligns them within a shared latent time-frequency space. In the fine-tuning stage, JCFA is refined in conjunction with downstream tasks, where the structural connections among brain electrodes are considered. The model capability could be further enhanced for the application in emotion detection and interpretation. Extensive experimental results on two well-recognized emotional datasets show that the proposed JCFA model achieves state-of-the-art (SOTA) performance, outperforming the second-best method by an average accuracy increase of 4.09% in cross-corpus EEG-based emotion recognition tasks.
4/16/2024

Multi-modal Mood Reader: Pre-trained Model Empowers Cross-Subject Emotion Recognition
Yihang Dong, Xuhang Chen, Yanyan Shen, Michael Kwok-Po Ng, Tao Qian, Shuqiang Wang
0
0
Emotion recognition based on Electroencephalography (EEG) has gained significant attention and diversified development in fields such as neural signal processing and affective computing. However, the unique brain anatomy of individuals leads to non-negligible natural differences in EEG signals across subjects, posing challenges for cross-subject emotion recognition. While recent studies have attempted to address these issues, they still face limitations in practical effectiveness and model framework unity. Current methods often struggle to capture the complex spatial-temporal dynamics of EEG signals and fail to effectively integrate multimodal information, resulting in suboptimal performance and limited generalizability across subjects. To overcome these limitations, we develop a Pre-trained model based Multimodal Mood Reader for cross-subject emotion recognition that utilizes masked brain signal modeling and interlinked spatial-temporal attention mechanism. The model learns universal latent representations of EEG signals through pre-training on large scale dataset, and employs Interlinked spatial-temporal attention mechanism to process Differential Entropy(DE) features extracted from EEG data. Subsequently, a multi-level fusion layer is proposed to integrate the discriminative features, maximizing the advantages of features across different dimensions and modalities. Extensive experiments on public datasets demonstrate Mood Reader's superior performance in cross-subject emotion recognition tasks, outperforming state-of-the-art methods. Additionally, the model is dissected from attention perspective, providing qualitative analysis of emotion-related brain areas, offering valuable insights for affective research in neural signal processing.
5/31/2024
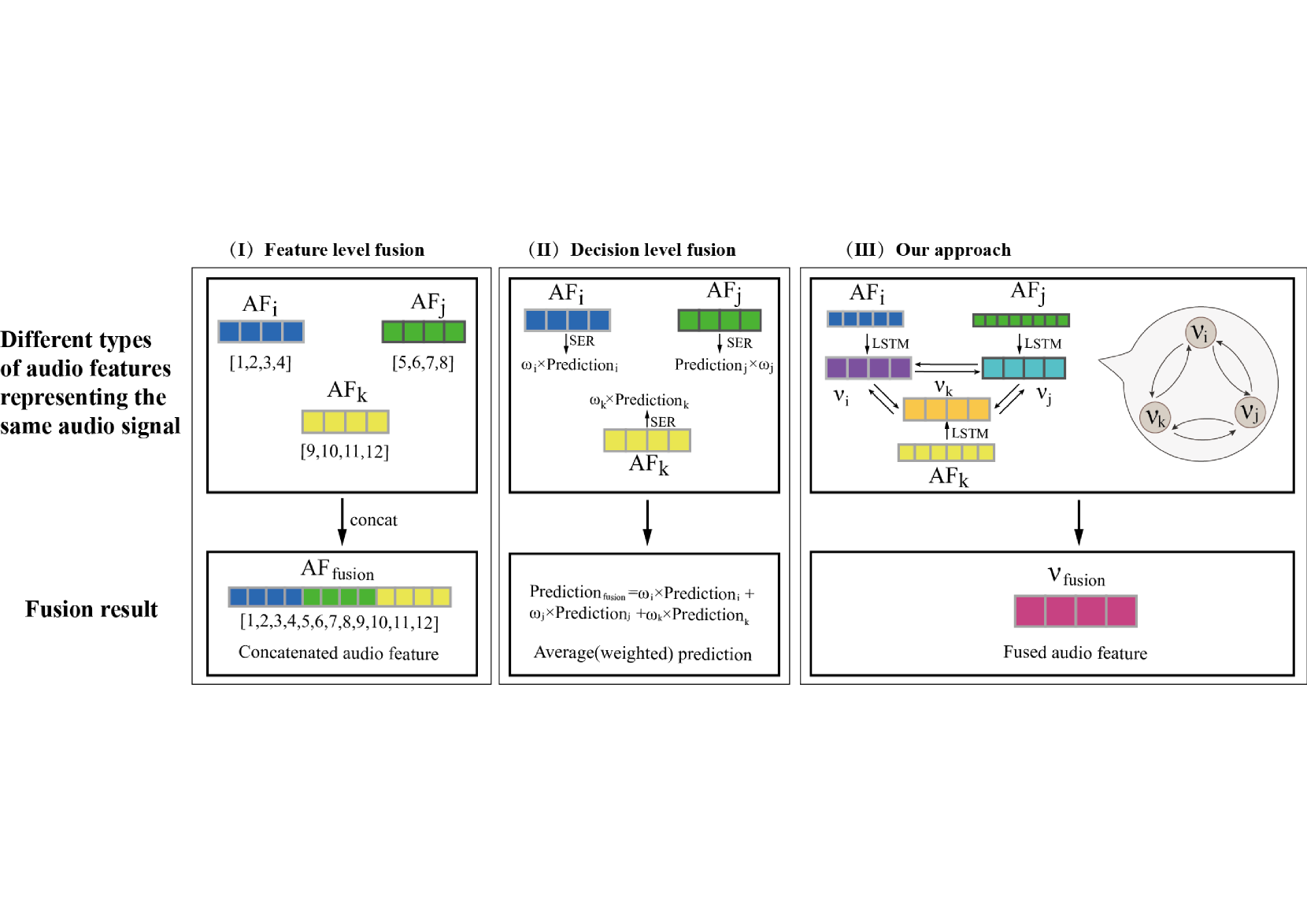
Graph-based multi-Feature fusion method for speech emotion recognition
Xueyu Liu, Jie Lin, Chao Wang
0
0
Exploring proper way to conduct multi-speech feature fusion for cross-corpus speech emotion recognition is crucial as different speech features could provide complementary cues reflecting human emotion status. While most previous approaches only extract a single speech feature for emotion recognition, existing fusion methods such as concatenation, parallel connection, and splicing ignore heterogeneous patterns in the interaction between features and features, resulting in performance of existing systems. In this paper, we propose a novel graph-based fusion method to explicitly model the relationships between every pair of speech features. Specifically, we propose a multi-dimensional edge features learning strategy called Graph-based multi-Feature fusion method for speech emotion recognition. It represents each speech feature as a node and learns multi-dimensional edge features to explicitly describe the relationship between each feature-feature pair in the context of emotion recognition. This way, the learned multi-dimensional edge features encode speech feature-level information from both the vertex and edge dimensions. Our Approach consists of three modules: an Audio Feature Generation(AFG)module, an Audio-Feature Multi-dimensional Edge Feature(AMEF) module and a Speech Emotion Recognition (SER) module. The proposed methodology yielded satisfactory outcomes on the SEWA dataset. Furthermore, the method demonstrated enhanced performance compared to the baseline in the AVEC 2019 Workshop and Challenge. We used data from two cultures as our training and validation sets: two cultures containing German and Hungarian on the SEWA dataset, the CCC scores for German are improved by 17.28% for arousal and 7.93% for liking. The outcomes of our methodology demonstrate a 13% improvement over alternative fusion techniques, including those employing one dimensional edge-based feature fusion approach.
6/14/2024
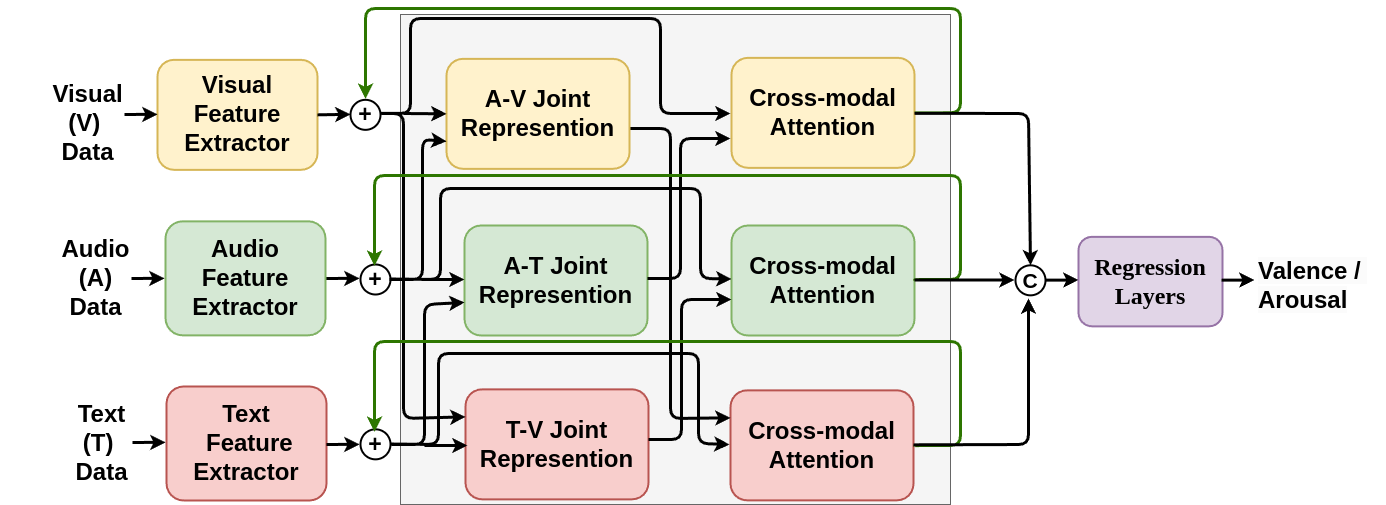
Recursive Joint Cross-Modal Attention for Multimodal Fusion in Dimensional Emotion Recognition
R. Gnana Praveen, Jahangir Alam
0
0
Though multimodal emotion recognition has achieved significant progress over recent years, the potential of rich synergic relationships across the modalities is not fully exploited. In this paper, we introduce Recursive Joint Cross-Modal Attention (RJCMA) to effectively capture both intra- and inter-modal relationships across audio, visual, and text modalities for dimensional emotion recognition. In particular, we compute the attention weights based on cross-correlation between the joint audio-visual-text feature representations and the feature representations of individual modalities to simultaneously capture intra- and intermodal relationships across the modalities. The attended features of the individual modalities are again fed as input to the fusion model in a recursive mechanism to obtain more refined feature representations. We have also explored Temporal Convolutional Networks (TCNs) to improve the temporal modeling of the feature representations of individual modalities. Extensive experiments are conducted to evaluate the performance of the proposed fusion model on the challenging Affwild2 dataset. By effectively capturing the synergic intra- and inter-modal relationships across audio, visual, and text modalities, the proposed fusion model achieves a Concordance Correlation Coefficient (CCC) of 0.585 (0.542) and 0.674 (0.619) for valence and arousal respectively on the validation set(test set). This shows a significant improvement over the baseline of 0.240 (0.211) and 0.200 (0.191) for valence and arousal, respectively, in the validation set (test set), achieving second place in the valence-arousal challenge of the 6th Affective Behavior Analysis in-the-Wild (ABAW) competition.
4/16/2024