Graph for Science: From API based Programming to Graph Engine based Programming for HPC
2312.04900
0
0
👀
Abstract
Modern scientific applications predominantly run on large-scale computing platforms, necessitating collaboration between scientific domain experts and high-performance computing (HPC) experts. While domain experts are often skilled in customizing domain-specific scientific computing routines, which often involves various matrix computations, HPC experts are essential for achieving efficient execution of these computations on large-scale platforms. This process often involves utilizing complex parallel computing libraries tailored to specific matrix computation scenarios. However, the intricate programming procedure and the need for deep understanding in both application domains and HPC poses significant challenges to the widespread adoption of scientific computing. In this research, we observe that matrix computations can be transformed into equivalent graph representations, and that by utilizing graph processing engines, HPC experts can be freed from the burden of implementing efficient scientific computations. Based on this observation, we introduce a graph engine-based scientific computing (Graph for Science) paradigm, which provides a unified graph programming interface, enabling domain experts to promptly implement various types of matrix computations. The proposed paradigm leverages the underlying graph processing engine to achieve efficient execution, eliminating the needs for HPC expertise in programming large-scale scientific applications. Our results show that the graph engine-based scientific computing paradigm achieves performance comparable to the best-performing implementations based on existing parallel computing libraries and bespoke implementations. Importantly, the paradigm greatly simplifies the development of scientific computations on large-scale platforms, reducing the programming difficulty for scientists and facilitating broader adoption of scientific computing.
Create account to get full access
Overview
- Scientific applications often require large-scale computing platforms, leading to the need for collaboration between domain experts and high-performance computing (HPC) experts.
- Domain experts are skilled in customizing domain-specific scientific computing routines, which often involve matrix computations.
- HPC experts are essential for achieving efficient execution of these computations on large-scale platforms, often using complex parallel computing libraries.
- The intricate programming procedures and the need for deep understanding in both application domains and HPC pose challenges for the widespread adoption of scientific computing.
Plain English Explanation
Scientific research is increasingly relying on large-scale computing platforms to perform complex calculations and simulations. This has created a need for collaboration between two different types of experts: those who specialize in the scientific domain (like physics, biology, or climate science) and those who specialize in high-performance computing (HPC).
The domain experts are skilled at designing and customizing the specific computational routines required for their research, which often involve a lot of matrix-based calculations. The HPC experts, on the other hand, are needed to help ensure these computations are executed efficiently on the large-scale computing platforms.
The HPC experts often use specialized parallel computing libraries to optimize the performance of the scientific computations. However, working with these libraries and integrating them into the domain-specific code can be very complex and challenging, requiring a deep understanding of both the scientific domain and HPC programming.
This complexity has made it difficult for many scientists to fully take advantage of large-scale computing platforms, hampering the progress of scientific research. The researchers in this study sought to find a way to simplify this process and make scientific computing more accessible to domain experts.
Technical Explanation
The researchers observed that matrix computations, which are a core part of many scientific computing routines, can be represented as equivalent graph structures. By leveraging graph processing engines, they were able to develop a new "Graph for Science" paradigm that provides a unified graph programming interface.
This interface allows domain experts to easily implement various types of matrix computations without needing extensive HPC expertise. The graph processing engine handles the efficient execution of these computations on large-scale platforms, freeing the domain experts from the burden of implementing complex parallel algorithms.
The researchers evaluated the performance of their Graph for Science approach and found that it achieved results comparable to the best-performing implementations using traditional parallel computing libraries and bespoke HPC programming. Importantly, their paradigm greatly simplifies the development of scientific computing applications, reducing the programming difficulty for domain experts and enabling broader adoption of these powerful computing capabilities.
Critical Analysis
The researchers acknowledge that their Graph for Science paradigm relies on the capabilities of the underlying graph processing engine. The performance and efficiency of the approach will ultimately depend on the maturity and optimization of the graph processing technologies.
Additionally, the researchers note that their current implementation targets a specific set of matrix computation patterns. Further research may be needed to expand the range of scientific computing routines that can be effectively represented and executed using the graph-based approach.
While the results are promising, it will be important to see how the Graph for Science paradigm performs on a wider range of real-world scientific computing workloads and to evaluate its suitability for more diverse application domains.
Conclusion
The researchers have introduced a novel approach to simplifying the development of large-scale scientific computing applications. By leveraging graph processing engines, they have created a paradigm that allows domain experts to easily implement complex matrix computations without needing deep expertise in high-performance computing.
This has the potential to significantly lower the barriers to entry for scientific computing, enabling more researchers to take advantage of powerful computing platforms and accelerating the pace of scientific discovery. As graph processing technologies continue to evolve, the Graph for Science paradigm may become an increasingly valuable tool for driving progress in a wide range of scientific fields.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
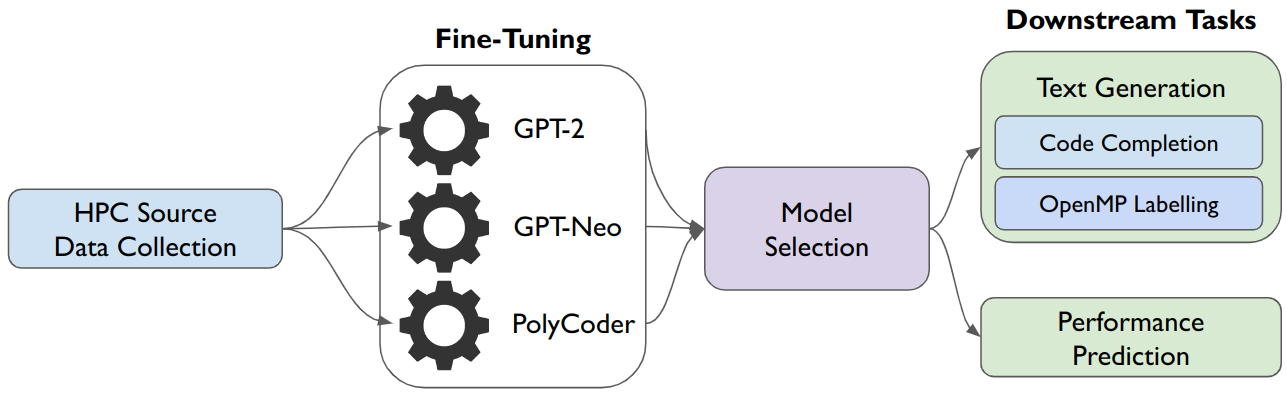
HPC-Coder: Modeling Parallel Programs using Large Language Models
Daniel Nichols, Aniruddha Marathe, Harshitha Menon, Todd Gamblin, Abhinav Bhatele
0
0
Parallel programs in high performance computing (HPC) continue to grow in complexity and scale in the exascale era. The diversity in hardware and parallel programming models make developing, optimizing, and maintaining parallel software even more burdensome for developers. One way to alleviate some of these burdens is with automated development and analysis tools. Such tools can perform complex and/or remedial tasks for developers that increase their productivity and decrease the chance for error. Until recently, such tools for code development and performance analysis have been limited in the complexity of tasks they can perform, especially for parallel programs. However, with recent advancements in language modeling, and the availability of large amounts of open-source code related data, these tools have started to utilize predictive language models to automate more complex tasks. In this paper, we show how large language models (LLMs) can be applied to tasks specific to high performance and scientific codes. We introduce a new dataset of HPC and scientific codes and use it to fine-tune several pre-trained models. We compare several pre-trained LLMs on HPC-related tasks and introduce a new model, HPC-Coder, fine-tuned on parallel codes. In our experiments, we show that this model can auto-complete HPC functions where generic models cannot, decorate for loops with OpenMP pragmas, and model performance changes in scientific application repositories as well as programming competition solutions.
5/15/2024

TEGRA -- Scaling Up Terascale Graph Processing with Disaggregated Computing
William Shaddix, Mahyar Samani, Marjan Fariborz, S. J. Ben Yoo, Jason Lowe-Power, Venkatesh Akella
0
0
Graphs are essential for representing relationships in various domains, driving modern AI applications such as graph analytics and neural networks across science, engineering, cybersecurity, transportation, and economics. However, the size of modern graphs are rapidly expanding, posing challenges for traditional CPUs and GPUs in meeting real-time processing demands. As a result, hardware accelerators for graph processing have been proposed. However, the largest graphs that can be handled by these systems is still modest often targeting Twitter graph(1.4B edges approximately). This paper aims to address this limitation by developing a graph accelerator capable of terascale graph processing. Scale out architectures, architectures where nodes are replicated to expand to larger datasets, are natural for handling larger graphs. We argue that this approach is not appropriate for very large-scale graphs because it leads to under utilization of both memory resources and compute resources. Additionally, vertex and edge processing have different access patterns. Communication overheads also pose further challenges in designing scalable architectures. To overcome these issues, this paper proposes TEGRA, a scale-up architecture for terascale graph processing. TEGRA leverages a composable computing system with disaggregated resources and a communication architecture inspired by Active Messages. By employing direct communication between cores and optimizing memory interconnect utilization, TEGRA effectively reduces communication overhead and improves resource utilization, therefore enabling efficient processing of terascale graphs.
4/5/2024
✨
A shared compilation stack for distributed-memory parallelism in stencil DSLs
George Bisbas, Anton Lydike, Emilien Bauer, Nick Brown, Mathieu Fehr, Lawrence Mitchell, Gabriel Rodriguez-Canal, Maurice Jamieson, Paul H. J. Kelly, Michel Steuwer, Tobias Grosser
0
0
Domain Specific Languages (DSLs) increase programmer productivity and provide high performance. Their targeted abstractions allow scientists to express problems at a high level, providing rich details that optimizing compilers can exploit to target current- and next-generation supercomputers. The convenience and performance of DSLs come with significant development and maintenance costs. The siloed design of DSL compilers and the resulting inability to benefit from shared infrastructure cause uncertainties around longevity and the adoption of DSLs at scale. By tailoring the broadly-adopted MLIR compiler framework to HPC, we bring the same synergies that the machine learning community already exploits across their DSLs (e.g. Tensorflow, PyTorch) to the finite-difference stencil HPC community. We introduce new HPC-specific abstractions for message passing targeting distributed stencil computations. We demonstrate the sharing of common components across three distinct HPC stencil-DSL compilers: Devito, PSyclone, and the Open Earth Compiler, showing that our framework generates high-performance executables based upon a shared compiler ecosystem.
4/4/2024

Use Cases for High Performance Research Desktops
Robert Henschel, Jonas Lindemann, Anders Follin, Bernd Dammann, Cicada Dennis, Abhinav Thota
0
0
High Performance Research Desktops are used by HPC centers and research computing organizations to lower the barrier of entry to HPC systems. These Linux desktops are deployed alongside HPC systems, leveraging the investments in HPC compute and storage infrastructure. By serving as a gateway to HPC systems they provide users with an environment to perform setup and infrastructure tasks related to the actual HPC work. Such tasks can take significant amounts of time, are vital to the successful use of HPC systems, and can benefit from a graphical desktop environment. In addition to serving as a gateway to HPC systems, High Performance Research Desktops are also used to run interactive graphical applications like MATLAB, RStudio or VMD. This paper defines the concept of High Performance Research Desktops and summarizes use cases from Indiana University, Lund University and Technical University of Denmark, which have implemented and operated such a system for more than 10 years. Based on these use cases, possible future directions are presented.
4/5/2024