HPC-Coder: Modeling Parallel Programs using Large Language Models
2306.17281
0
0
Abstract
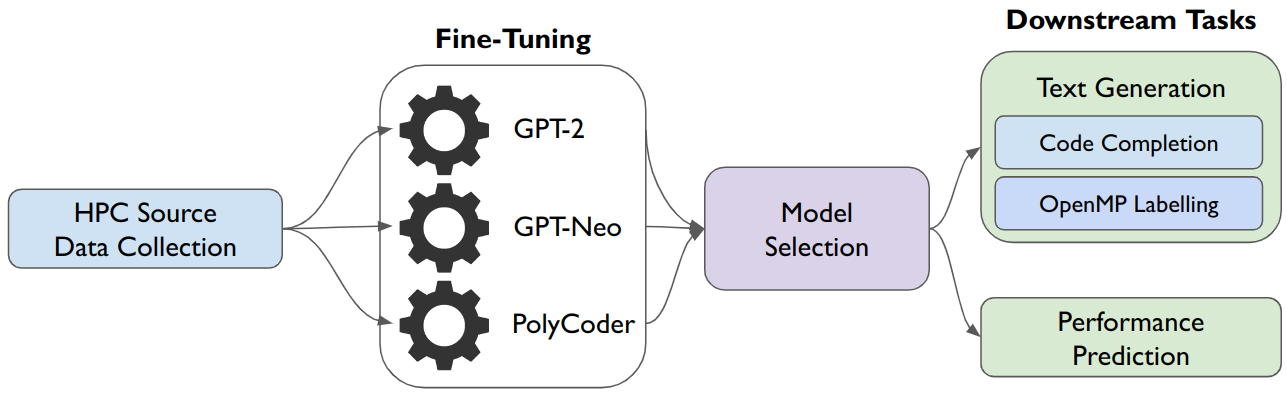
Parallel programs in high performance computing (HPC) continue to grow in complexity and scale in the exascale era. The diversity in hardware and parallel programming models make developing, optimizing, and maintaining parallel software even more burdensome for developers. One way to alleviate some of these burdens is with automated development and analysis tools. Such tools can perform complex and/or remedial tasks for developers that increase their productivity and decrease the chance for error. Until recently, such tools for code development and performance analysis have been limited in the complexity of tasks they can perform, especially for parallel programs. However, with recent advancements in language modeling, and the availability of large amounts of open-source code related data, these tools have started to utilize predictive language models to automate more complex tasks. In this paper, we show how large language models (LLMs) can be applied to tasks specific to high performance and scientific codes. We introduce a new dataset of HPC and scientific codes and use it to fine-tune several pre-trained models. We compare several pre-trained LLMs on HPC-related tasks and introduce a new model, HPC-Coder, fine-tuned on parallel codes. In our experiments, we show that this model can auto-complete HPC functions where generic models cannot, decorate for loops with OpenMP pragmas, and model performance changes in scientific application repositories as well as programming competition solutions.
Create account to get full access
Overview
- This paper explores the use of large language models (LLMs) for modeling and generating parallel programs.
- The researchers investigate whether LLMs can learn to write efficient parallel code that performs well on various benchmarks.
- They also explore techniques for optimizing the performance of LLM-generated parallel code, such as performance-aligned LLMs and learning performance-improving code edits.
Plain English Explanation
Large language models (LLMs) like GPT-3 have shown impressive abilities in natural language generation, but can they also be used to write efficient computer programs? That's the question this research paper set out to explore.
The researchers wanted to see if LLMs could learn to create parallel programs - programs that can run different parts of the code at the same time to speed up computations. Parallel programming can be complex, so the researchers were curious if LLMs could handle the challenges.
They experimented with different techniques to help the LLMs generate high-performance parallel code. For example, they tried training the LLMs to produce code that aligns with good performance on benchmark tests. They also looked at ways the LLMs could learn to automatically make edits to improve the performance of the generated code.
Overall, the researchers found that LLMs can be a promising approach for parallel programming, but there are still some challenges to overcome. Their work provides insights into how we might be able to harness the power of these large language models to write efficient, high-performing parallel code in the future.
Technical Explanation
The researchers explored the use of large language models (LLMs) for modeling and generating parallel programs. They investigated whether LLMs can learn to write efficient parallel code that performs well on various benchmarks, and they experimented with techniques to optimize the performance of LLM-generated parallel code.
One approach they explored was performance-aligned LLMs, where the LLMs were trained to produce code that aligns with good performance on benchmark tests. The researchers found that this technique helped the LLMs generate parallel code with higher performance than standard LLMs.
The researchers also investigated learning performance-improving code edits, where the LLMs were trained to automatically make edits to the generated code that would improve its performance. This allowed the LLMs to iteratively refine the parallel code they produced to achieve better results.
Additionally, the researchers developed a model called OMPGPT, which is a generative pre-trained transformer model specifically designed for generating OpenMP code, a popular parallel programming framework. This model was trained on a large corpus of OpenMP code to learn the patterns and structures of parallel programming.
The researchers also compared their LLM-based approach to a traditional code generation method called MPIrigen, which generates MPI (Message Passing Interface) code, another parallel programming framework. They found that their LLM-based approach was able to outperform the traditional method on certain benchmarks.
Critical Analysis
The researchers acknowledged several limitations and areas for further research in their paper. One key limitation is that the LLMs they used were not specifically designed for parallel programming, and there may be opportunities to further improve performance by developing LLMs that are more tailored to the unique challenges of parallel code generation.
Additionally, the researchers noted that their experiments were conducted on a relatively small set of parallel programming tasks and benchmarks. More extensive testing on a wider range of parallel programming problems would be necessary to fully assess the capabilities and limitations of their LLM-based approach.
Another area for further research is the interpretability and explainability of the LLM-generated parallel code. As these models become more complex, it can be challenging to understand the reasoning behind the decisions they make when generating code. Developing techniques to improve the transparency and interpretability of LLM-based code generation could be valuable for building trust and acceptance in the use of these models for real-world applications.
Despite these limitations, the researchers' work provides valuable insights into the potential of using large language models for parallel programming. Their exploration of techniques like performance-aligned LLMs and learning performance-improving code edits suggests that there may be fruitful avenues for further research and development in this area.
Conclusion
This research paper has explored the use of large language models (LLMs) for modeling and generating parallel programs. The researchers found that LLMs can be a promising approach for parallel programming, but there are still some challenges to overcome.
By experimenting with techniques like performance-aligned LLMs and learning performance-improving code edits, the researchers were able to demonstrate that LLMs can generate parallel code that performs well on various benchmarks. This suggests that LLMs could potentially be leveraged to simplify the complex task of parallel programming, making it more accessible to a wider range of developers.
As the field of AI and machine learning continues to advance, the ability to harness the power of large language models for tasks like code generation could have significant implications for the future of software development. This research provides an important foundation for further exploration in this area, paving the way for more efficient and accessible parallel programming in the years to come.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
Can Large Language Models Write Parallel Code?
Daniel Nichols, Joshua H. Davis, Zhaojun Xie, Arjun Rajaram, Abhinav Bhatele
0
0
Large language models are increasingly becoming a popular tool for software development. Their ability to model and generate source code has been demonstrated in a variety of contexts, including code completion, summarization, translation, and lookup. However, they often struggle to generate code for complex programs. In this paper, we study the capabilities of state-of-the-art language models to generate parallel code. In order to evaluate language models, we create a benchmark, ParEval, consisting of prompts that represent 420 different coding tasks related to scientific and parallel computing. We use ParEval to evaluate the effectiveness of several state-of-the-art open- and closed-source language models on these tasks. We introduce novel metrics for evaluating the performance of generated code, and use them to explore how well each large language model performs for 12 different computational problem types and six different parallel programming models.
5/15/2024
➖
Performance-Aligned LLMs for Generating Fast Code
Daniel Nichols, Pranav Polasam, Harshitha Menon, Aniruddha Marathe, Todd Gamblin, Abhinav Bhatele
0
0
Optimizing scientific software is a difficult task because codebases are often large and complex, and performance can depend upon several factors including the algorithm, its implementation, and hardware among others. Causes of poor performance can originate from disparate sources and be difficult to diagnose. Recent years have seen a multitude of work that use large language models (LLMs) to assist in software development tasks. However, these tools are trained to model the distribution of code as text, and are not specifically designed to understand performance aspects of code. In this work, we introduce a reinforcement learning based methodology to align the outputs of code LLMs with performance. This allows us to build upon the current code modeling capabilities of LLMs and extend them to generate better performing code. We demonstrate that our fine-tuned model improves the expected speedup of generated code over base models for a set of benchmark tasks from 0.9 to 1.6 for serial code and 1.9 to 4.5 for OpenMP code.
4/30/2024
💬
Scientific Computing with Large Language Models
Christopher Culver, Peter Hicks, Mihailo Milenkovic, Sanjif Shanmugavelu, Tobias Becker
0
0
We provide an overview of the emergence of large language models for scientific computing applications. We highlight use cases that involve natural language processing of scientific documents and specialized languages designed to describe physical systems. For the former, chatbot style applications appear in medicine, mathematics and physics and can be used iteratively with domain experts for problem solving. We also review specialized languages within molecular biology, the languages of molecules, proteins, and DNA where language models are being used to predict properties and even create novel physical systems at much faster rates than traditional computing methods.
6/12/2024
💬
Investigating the translation capabilities of Large Language Models trained on parallel data only
Javier Garc'ia Gilabert, Carlos Escolano, Aleix Sant Savall, Francesca De Luca Fornaciari, Audrey Mash, Xixian Liao, Maite Melero
0
0
In recent years, Large Language Models (LLMs) have demonstrated exceptional proficiency across a broad spectrum of Natural Language Processing (NLP) tasks, including Machine Translation. However, previous methods predominantly relied on iterative processes such as instruction fine-tuning or continual pre-training, leaving unexplored the challenges of training LLMs solely on parallel data. In this work, we introduce PLUME (Parallel Language Model), a collection of three 2B LLMs featuring varying vocabulary sizes (32k, 128k, and 256k) trained exclusively on Catalan-centric parallel examples. These models perform comparably to previous encoder-decoder architectures on 16 supervised translation directions and 56 zero-shot ones. Utilizing this set of models, we conduct a thorough investigation into the translation capabilities of LLMs, probing their performance, the impact of the different elements of the prompt, and their cross-lingual representation space.
6/14/2024