Handling Distribution Shifts on Graphs: An Invariance Perspective

0
🏷️
Sign in to get full access
Overview
- Neural networks have shown sensitivity to distribution shifts, leading to increased research on out-of-distribution (OOD) generalization.
- Current work focuses on Euclidean data, but the formulation for graph-structured data is unclear and under-explored.
- Two challenges: 1) non-IID data generation due to node interconnections, and 2) the informative structural information in the input graph.
- This paper formulates the OOD problem on graphs and introduces a new approach called Explore-to-Extrapolate Risk Minimization (EERM) to enable graph neural networks to leverage invariance principles for prediction.
Plain English Explanation
<a href="https://aimodels.fyi/papers/arxiv/graph-structure-feature-extrapolation-out-distribution-generalization">Neural networks</a> are powerful machine learning models that can learn complex patterns in data. However, researchers have found that these models can be sensitive to changes in the distribution of the data they're trained on. This means that a model trained on one type of data may not perform well on a different, but related, type of data.
This issue, known as <a href="https://aimodels.fyi/papers/arxiv/graph-out-distribution-generalization-via-causal-intervention">out-of-distribution (OOD) generalization</a>, has become an important area of research. Much of the work in this field has focused on data that can be represented as points in a flat, Euclidean space, such as images or text. But the researchers behind this paper were interested in exploring OOD generalization for <a href="https://aimodels.fyi/papers/arxiv/improving-out-distribution-generalization-graphs-via-hierarchical">graph-structured data</a>, where the data points (nodes) are connected in a complex network.
Graphs pose some unique challenges for OOD generalization. First, the connections between nodes mean that the data points are not independent, so they can't be easily split into training and testing sets. Second, the structure of the graph itself can contain valuable information for making predictions, which needs to be taken into account.
To address these challenges, the researchers developed a new approach called Explore-to-Extrapolate Risk Minimization (EERM). The key idea is to train the model to be robust to changes in the graph structure by exposing it to a variety of "virtual environments" during training. This helps the model learn to generalize beyond the specific environment it was trained on, <a href="https://aimodels.fyi/papers/arxiv/iene-identifying-extrapolating-node-environment-out-distribution">allowing it to make accurate predictions even when the data distribution shifts</a>.
The researchers demonstrated the power of their EERM approach on various real-world datasets, showing that it can handle distribution shifts from things like artificial spurious features, cross-domain transfers, and dynamic graph evolution. This work represents an important step forward in addressing the challenging problem of OOD generalization for graph-structured data.
Technical Explanation
The paper formulates the OOD problem for graph-structured data and introduces a new approach called Explore-to-Extrapolate Risk Minimization (EERM) to address the unique challenges.
The key challenges with OOD generalization on graphs are:
- Non-IID data generation: The interconnections between nodes in a graph mean that the data points (nodes) are not independently and identically distributed (IID), even under the same environment.
- Informative structural information: The structure of the input graph contains valuable information for making predictions, which needs to be taken into account.
To tackle these challenges, the EERM approach resorts to multiple "context explorers" (specified as graph structure editors in this case) that are adversarially trained to maximize the variance of risks from multiple virtual environments. This design enables the model to extrapolate from a single observed environment, which is the common case for node-level prediction tasks.
The researchers prove the validity of their method by showing that EERM guarantees a valid OOD solution. They further demonstrate its effectiveness on various real-world datasets, handling distribution shifts from artificial spurious features, cross-domain transfers, and dynamic graph evolution.
Critical Analysis
The paper presents a novel and promising approach to addressing the challenging problem of OOD generalization for graph-structured data. The key strengths of the EERM method are:
- Addressing the unique challenges of graphs: By explicitly accounting for the non-IID nature of graph data and the informative structural information, the researchers have developed a solution tailored to the specific needs of this domain.
- Theoretical guarantees: The paper provides a theoretical analysis showing that EERM can guarantee a valid OOD solution, which is an important step in validating the approach.
- Empirical demonstrations: The researchers demonstrate the effectiveness of EERM on various real-world datasets, showcasing its ability to handle different types of distribution shifts.
However, the paper also acknowledges some limitations and areas for future research:
- Computational complexity: The need to train multiple "context explorers" adversarially may introduce significant computational overhead, which could limit the scalability of the approach.
- Interpretability: The paper does not delve deeply into the interpretability of the learned representations and the insights they may provide into the underlying causes of distribution shifts.
- Generalization to other graph tasks: While the paper focuses on node-level prediction tasks, it would be valuable to explore the applicability of EERM to other graph-based problems, such as link prediction or graph classification.
Overall, this paper represents an important contribution to the field of OOD generalization for graph-structured data, and the EERM approach shows promise as a way to improve the robustness and reliability of graph neural networks in real-world applications. <a href="https://aimodels.fyi/papers/arxiv/improving-graph-out-distribution-generalization-real-world">Further research in this direction could lead to significant advancements in the field</a>.
Conclusion
This paper tackles the challenge of out-of-distribution (OOD) generalization for graph-structured data, which has received relatively little attention compared to Euclidean data. The researchers formulate the OOD problem on graphs and develop a new approach called Explore-to-Extrapolate Risk Minimization (EERM) to enable graph neural networks to leverage invariance principles for prediction.
EERM addresses the two key challenges of non-IID data generation and informative structural information in graphs by training multiple "context explorers" to maximize the variance of risks from virtual environments. This design allows the model to extrapolate from a single observed environment, which is common for node-level prediction tasks.
The paper provides theoretical guarantees for the validity of the EERM approach and demonstrates its effectiveness on various real-world datasets, handling distribution shifts from artificial spurious features, cross-domain transfers, and dynamic graph evolution. This work represents an important step forward in improving the robustness and reliability of graph neural networks, with potential applications in a wide range of domains that rely on graph-structured data.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🏷️
0
Handling Distribution Shifts on Graphs: An Invariance Perspective
Qitian Wu, Hengrui Zhang, Junchi Yan, David Wipf
There is increasing evidence suggesting neural networks' sensitivity to distribution shifts, so that research on out-of-distribution (OOD) generalization comes into the spotlight. Nonetheless, current endeavors mostly focus on Euclidean data, and its formulation for graph-structured data is not clear and remains under-explored, given two-fold fundamental challenges: 1) the inter-connection among nodes in one graph, which induces non-IID generation of data points even under the same environment, and 2) the structural information in the input graph, which is also informative for prediction. In this paper, we formulate the OOD problem on graphs and develop a new invariant learning approach, Explore-to-Extrapolate Risk Minimization (EERM), that facilitates graph neural networks to leverage invariance principles for prediction. EERM resorts to multiple context explorers (specified as graph structure editers in our case) that are adversarially trained to maximize the variance of risks from multiple virtual environments. Such a design enables the model to extrapolate from a single observed environment which is the common case for node-level prediction. We prove the validity of our method by theoretically showing its guarantee of a valid OOD solution and further demonstrate its power on various real-world datasets for handling distribution shifts from artificial spurious features, cross-domain transfers and dynamic graph evolution.
Read more8/19/2024
0
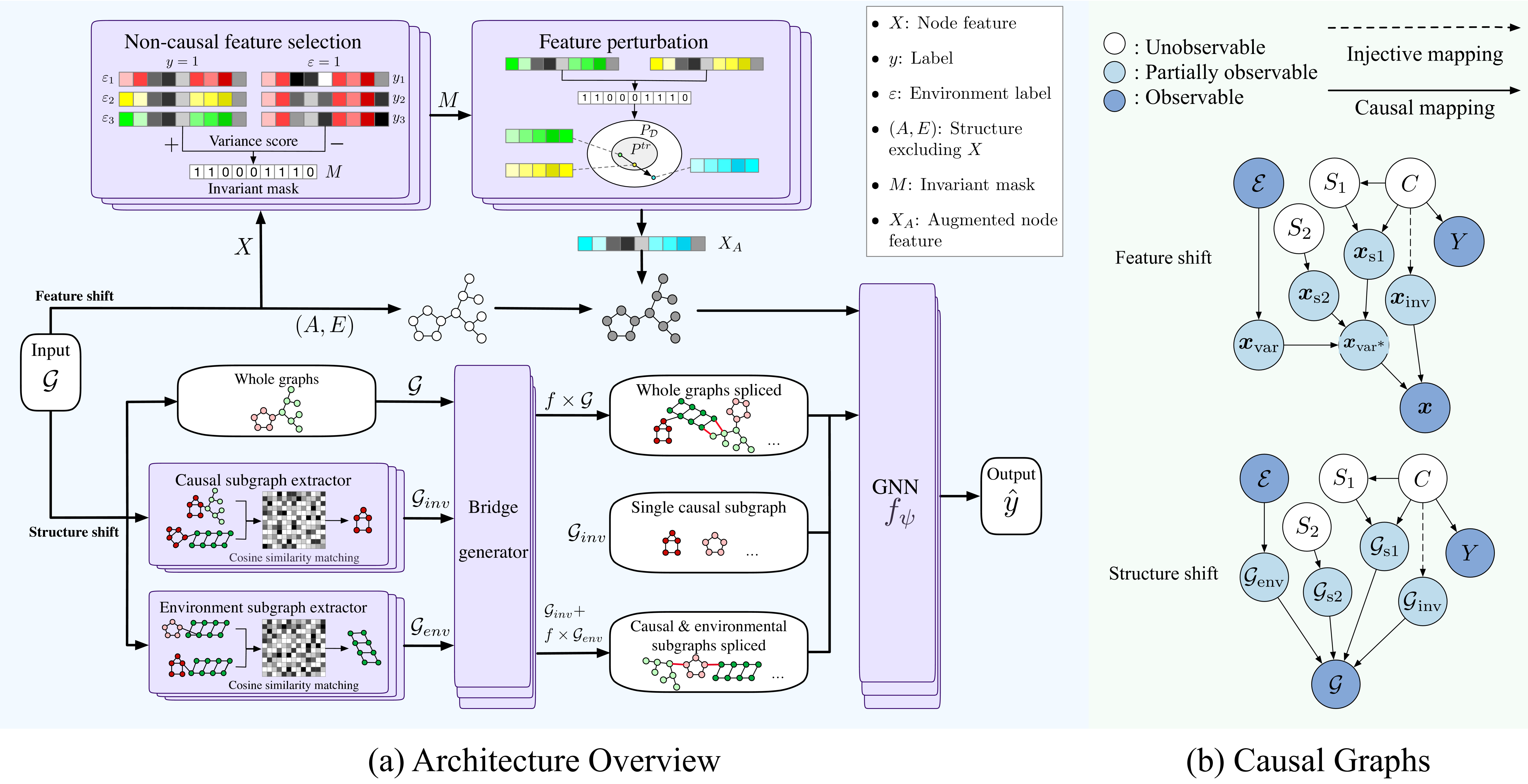
Graph Structure and Feature Extrapolation for Out-of-Distribution Generalization
Xiner Li, Shurui Gui, Youzhi Luo, Shuiwang Ji
Out-of-distribution (OOD) generalization deals with the prevalent learning scenario where test distribution shifts from training distribution. With rising application demands and inherent complexity, graph OOD problems call for specialized solutions. While data-centric methods exhibit performance enhancements on many generic machine learning tasks, there is a notable absence of data augmentation methods tailored for graph OOD generalization. In this work, we propose to achieve graph OOD generalization with the novel design of non-Euclidean-space linear extrapolation. The proposed augmentation strategy extrapolates both structure and feature spaces to generate OOD graph data. Our design tailors OOD samples for specific shifts without corrupting underlying causal mechanisms. Theoretical analysis and empirical results evidence the effectiveness of our method in solving target shifts, showing substantial and constant improvements across various graph OOD tasks.
Read more6/6/2024

0
Graph Out-of-Distribution Generalization via Causal Intervention
Qitian Wu, Fan Nie, Chenxiao Yang, Tianyi Bao, Junchi Yan
Out-of-distribution (OOD) generalization has gained increasing attentions for learning on graphs, as graph neural networks (GNNs) often exhibit performance degradation with distribution shifts. The challenge is that distribution shifts on graphs involve intricate interconnections between nodes, and the environment labels are often absent in data. In this paper, we adopt a bottom-up data-generative perspective and reveal a key observation through causal analysis: the crux of GNNs' failure in OOD generalization lies in the latent confounding bias from the environment. The latter misguides the model to leverage environment-sensitive correlations between ego-graph features and target nodes' labels, resulting in undesirable generalization on new unseen nodes. Built upon this analysis, we introduce a conceptually simple yet principled approach for training robust GNNs under node-level distribution shifts, without prior knowledge of environment labels. Our method resorts to a new learning objective derived from causal inference that coordinates an environment estimator and a mixture-of-expert GNN predictor. The new approach can counteract the confounding bias in training data and facilitate learning generalizable predictive relations. Extensive experiment demonstrates that our model can effectively enhance generalization with various types of distribution shifts and yield up to 27.4% accuracy improvement over state-of-the-arts on graph OOD generalization benchmarks. Source codes are available at https://github.com/fannie1208/CaNet.
Read more8/19/2024
0
Improving out-of-distribution generalization in graphs via hierarchical semantic environments
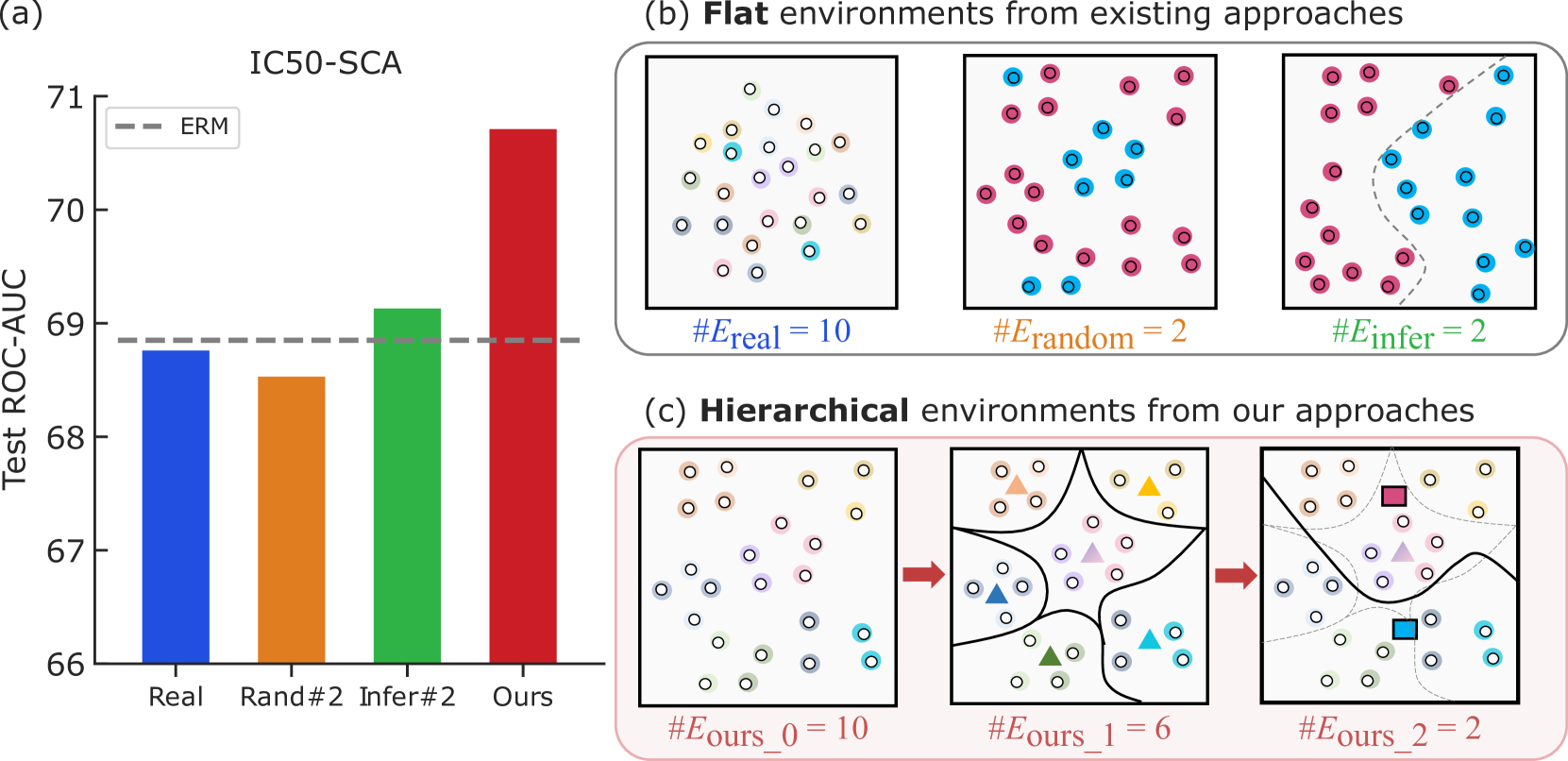
Yinhua Piao, Sangseon Lee, Yijingxiu Lu, Sun Kim
Out-of-distribution (OOD) generalization in the graph domain is challenging due to complex distribution shifts and a lack of environmental contexts. Recent methods attempt to enhance graph OOD generalization by generating flat environments. However, such flat environments come with inherent limitations to capture more complex data distributions. Considering the DrugOOD dataset, which contains diverse training environments (e.g., scaffold, size, etc.), flat contexts cannot sufficiently address its high heterogeneity. Thus, a new challenge is posed to generate more semantically enriched environments to enhance graph invariant learning for handling distribution shifts. In this paper, we propose a novel approach to generate hierarchical semantic environments for each graph. Firstly, given an input graph, we explicitly extract variant subgraphs from the input graph to generate proxy predictions on local environments. Then, stochastic attention mechanisms are employed to re-extract the subgraphs for regenerating global environments in a hierarchical manner. In addition, we introduce a new learning objective that guides our model to learn the diversity of environments within the same hierarchy while maintaining consistency across different hierarchies. This approach enables our model to consider the relationships between environments and facilitates robust graph invariant learning. Extensive experiments on real-world graph data have demonstrated the effectiveness of our framework. Particularly, in the challenging dataset DrugOOD, our method achieves up to 1.29% and 2.83% improvement over the best baselines on IC50 and EC50 prediction tasks, respectively.
Read more6/4/2024