Hardware-Assisted Virtualization of Neural Processing Units for Cloud Platforms

0
Sign in to get full access
Overview
- Introduces a hardware-assisted virtualization approach for Neural Processing Units (NPUs) in cloud platforms
- Aims to improve the efficiency and utilization of NPUs by enabling on-demand allocation and sharing among multiple tenants
- Leverages hardware-assisted virtualization techniques to partition and isolate NPU resources for secure multi-tenant deployment
Plain English Explanation
This paper explores a new way to use Neural Processing Units (NPUs) more efficiently in cloud computing environments. NPUs are specialized hardware designed to accelerate neural network workloads, but they can be expensive and underutilized when deployed in the cloud.
The researchers propose a hardware-assisted virtualization approach that allows cloud providers to partition and isolate NPU resources so they can be shared securely among multiple tenants (customers). This enables on-demand allocation of NPU capacity, improving the overall efficiency and utilization of the hardware.
By leveraging virtualization techniques, the system can assign dedicated NPU resources to each tenant while maintaining strong isolation and security guarantees. This allows cloud users to access the specialized NPU hardware as needed without having to purchase and manage the physical devices themselves.
The key idea is to create a virtualized NPU abstraction that can be dynamically provisioned and shared, much like virtual machines or containers are used to partition and allocate general-purpose computing resources in the cloud today.
Technical Explanation
The paper first provides background on the challenges of efficiently deploying and utilizing NPUs in cloud environments. NPUs offer significant performance improvements for neural network workloads compared to general-purpose CPUs, but they can be expensive and difficult to share securely among multiple tenants.
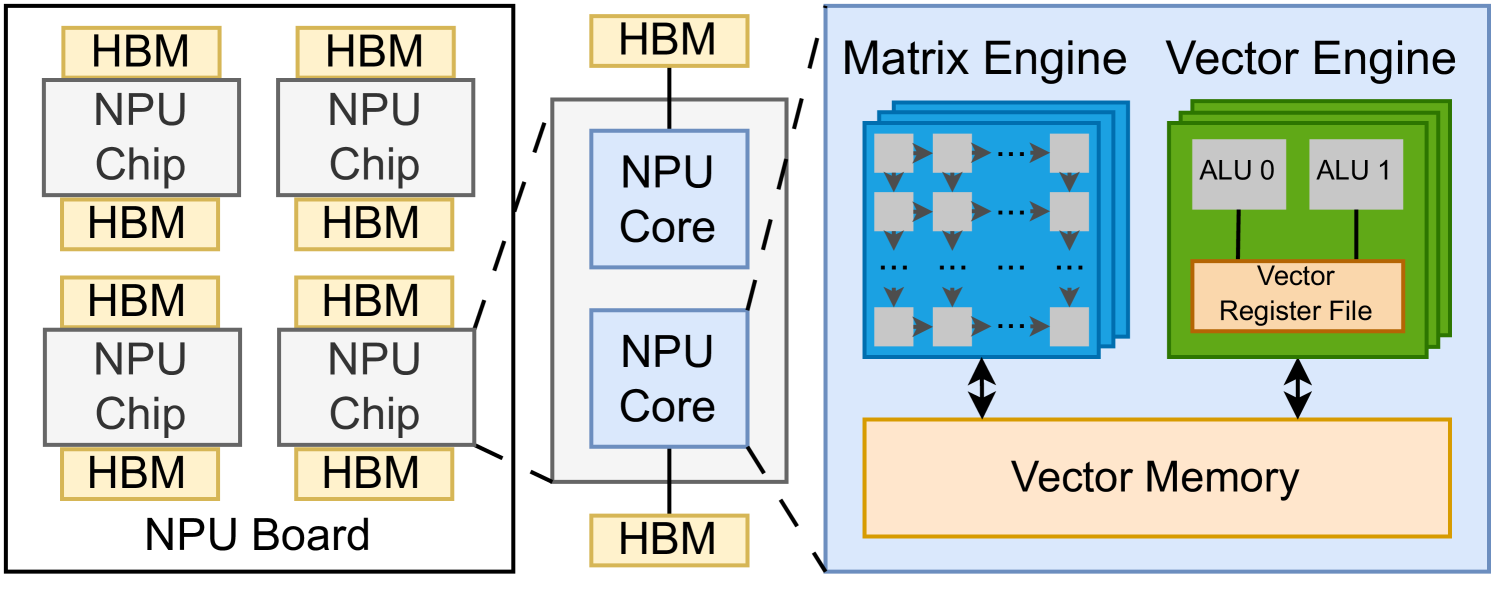
The researchers propose a hardware-assisted virtualization architecture that introduces a Virtual NPU (VNPU) abstraction. VNPUs encapsulate the state and resources of individual NPU devices, allowing them to be partitioned, assigned, and managed independently for each tenant.
The VNPU design leverages features of modern system-on-chip (SoC) architectures that enable hardware-enforced isolation and resource allocation. This includes mechanisms like memory protection units (MPUs), peripheral protection units (PPUs), and interrupt controllers to carve up and control access to NPU subsystems.
The paper describes the VNPU lifecycle, including provisioning, scheduling, and migration. It also covers the software stack required to manage the virtualized NPU resources, including a hypervisor, device drivers, and tenant-facing APIs.
The researchers evaluate their approach through a prototype implementation and experiments, demonstrating performance improvements in terms of NPU utilization and tenant isolation compared to a non-virtualized baseline.
Critical Analysis
The paper proposes a promising solution to a real-world problem facing cloud providers as they seek to offer specialized AI hardware to customers in a scalable and secure manner. The hardware-assisted virtualization approach seems well-suited to the unique requirements of NPUs and could help unlock their full potential in cloud environments.
That said, the paper does not address certain practical considerations, such as the overhead and complexities introduced by the virtualization layer, or the potential for performance degradation compared to direct bare-metal access to the NPU hardware. Additionally, the authors do not explore how their technique might extend to other types of specialized accelerators beyond NPUs.
Further research would be needed to fully understand the tradeoffs and limitations of this approach, as well as its applicability to a broader range of accelerator technologies. It would also be interesting to see how this work might integrate with other efforts in the field, such as approaches for efficient deployment of hybrid SNNs on neuromorphic hardware or techniques for characterizing the soft error resilience of ARM's Ethos-U55 NPU.
Conclusion
This paper presents a novel hardware-assisted virtualization technique for efficiently deploying and utilizing Neural Processing Units in cloud computing environments. By creating a Virtual NPU abstraction that can be securely partitioned and shared among multiple tenants, the approach aims to improve the overall utilization and cost-effectiveness of these specialized AI accelerators.
The research demonstrates the potential for virtualization to unlock the benefits of NPUs in the cloud, and could have broader implications for the deployment of other types of accelerators as well. As cloud-based AI continues to grow in importance, techniques like this that enable efficient and flexible access to specialized hardware will become increasingly valuable.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Hardware-Assisted Virtualization of Neural Processing Units for Cloud Platforms
Yuqi Xue, Yiqi Liu, Lifeng Nai, Jian Huang
Cloud platforms today have been deploying hardware accelerators like neural processing units (NPUs) for powering machine learning (ML) inference services. To maximize the resource utilization while ensuring reasonable quality of service, a natural approach is to virtualize NPUs for efficient resource sharing for multi-tenant ML services. However, virtualizing NPUs for modern cloud platforms is not easy. This is not only due to the lack of system abstraction support for NPU hardware, but also due to the lack of architectural and ISA support for enabling fine-grained dynamic operator scheduling for virtualized NPUs. We present Neu10, a holistic NPU virtualization framework. We investigate virtualization techniques for NPUs across the entire software and hardware stack. Neu10 consists of (1) a flexible NPU abstraction called vNPU, which enables fine-grained virtualization of the heterogeneous compute units in a physical NPU (pNPU); (2) a vNPU resource allocator that enables pay-as-you-go computing model and flexible vNPU-to-pNPU mappings for improved resource utilization and cost-effectiveness; (3) an ISA extension of modern NPU architecture for facilitating fine-grained tensor operator scheduling for multiple vNPUs. We implement Neu10 based on a production-level NPU simulator. Our experiments show that Neu10 improves the throughput of ML inference services by up to 1.4$times$ and reduces the tail latency by up to 4.6$times$, while improving the NPU utilization by 1.2$times$ on average, compared to state-of-the-art NPU sharing approaches.
Read more9/16/2024
🤖
0
Neuromorphic hardware for sustainable AI data centers
Bernhard Vogginger, Amirhossein Rostami, Vaibhav Jain, Sirine Arfa, Andreas Hantsch, David Kappel, Michael Schafer, Ulrike Faltings, Hector A. Gonzalez, Chen Liu, Christian Mayr, Wolfgang Maa{ss}
As humans advance toward a higher level of artificial intelligence, it is always at the cost of escalating computational resource consumption, which requires developing novel solutions to meet the exponential growth of AI computing demand. Neuromorphic hardware takes inspiration from how the brain processes information and promises energy-efficient computing of AI workloads. Despite its potential, neuromorphic hardware has not found its way into commercial AI data centers. In this article, we try to analyze the underlying reasons for this and derive requirements and guidelines to promote neuromorphic systems for efficient and sustainable cloud computing: We first review currently available neuromorphic hardware systems and collect examples where neuromorphic solutions excel conventional AI processing on CPUs and GPUs. Next, we identify applications, models and algorithms which are commonly deployed in AI data centers as further directions for neuromorphic algorithms research. Last, we derive requirements and best practices for the hardware and software integration of neuromorphic systems into data centers. With this article, we hope to increase awareness of the challenges of integrating neuromorphic hardware into data centers and to guide the community to enable sustainable and energy-efficient AI at scale.
Read more6/28/2024

0
Characterizing Soft-Error Resiliency in Arm's Ethos-U55 Embedded Machine Learning Accelerator
Abhishek Tyagi, Reiley Jeyapaul, Chuteng Zhu, Paul Whatmough, Yuhao Zhu
As Neural Processing Units (NPU) or accelerators are increasingly deployed in a variety of applications including safety critical applications such as autonomous vehicle, and medical imaging, it is critical to understand the fault-tolerance nature of the NPUs. We present a reliability study of Arm's Ethos-U55, an important industrial-scale NPU being utilised in embedded and IoT applications. We perform large scale RTL-level fault injections to characterize Ethos-U55 against the Automotive Safety Integrity Level D (ASIL-D) resiliency standard commonly used for safety-critical applications such as autonomous vehicles. We show that, under soft errors, all four configurations of the NPU fall short of the required level of resiliency for a variety of neural networks running on the NPU. We show that it is possible to meet the ASIL-D level resiliency without resorting to conventional strategies like Dual Core Lock Step (DCLS) that has an area overhead of 100%. We achieve so through selective protection, where hardware structures are selectively protected (e.g., duplicated, hardened) based on their sensitivity to soft errors and their silicon areas. To identify the optimal configuration that minimizes the area overhead while meeting the ASIL-D standard, the main challenge is the large search space associated with the time-consuming RTL simulation. To address this challenge, we present a statistical analysis tool that is validated against Arm silicon and that allows us to quickly navigate hundreds of billions of fault sites without exhaustive RTL fault injections. We show that by carefully duplicating a small fraction of the functional blocks and hardening the Flops in other blocks meets the ASIL-D safety standard while introducing an area overhead of only 38%.
Read more4/16/2024

0
Insight Gained from Migrating a Machine Learning Model to Intelligence Processing Units
Hieu Le, Zhenhua He, Mai Le, Dhruva K. Chakravorty, Lisa M. Perez, Akhil Chilumuru, Yan Yao, Jiefu Chen
The discoveries in this paper show that Intelligence Processing Units (IPUs) offer a viable accelerator alternative to GPUs for machine learning (ML) applications within the fields of materials science and battery research. We investigate the process of migrating a model from GPU to IPU and explore several optimization techniques, including pipelining and gradient accumulation, aimed at enhancing the performance of IPU-based models. Furthermore, we have effectively migrated a specialized model to the IPU platform. This model is employed for predicting effective conductivity, a parameter crucial in ion transport processes, which govern the performance of multiple charge and discharge cycles of batteries. The model utilizes a Convolutional Neural Network (CNN) architecture to perform prediction tasks for effective conductivity. The performance of this model on the IPU is found to be comparable to its execution on GPUs. We also analyze the utilization and performance of Graphcore's Bow IPU. Through benchmark tests, we observe significantly improved performance with the Bow IPU when compared to its predecessor, the Colossus IPU.
Read more4/17/2024