HarmonyBatch: Batching multi-SLO DNN Inference with Heterogeneous Serverless Functions

0
🤯
Sign in to get full access
Overview
- Deep Neural Network (DNN) inference on serverless functions is gaining popularity due to potential cost savings
- Existing work focuses on optimizing batching requests from a single application with a single Service Level Objective (SLO) on CPU functions
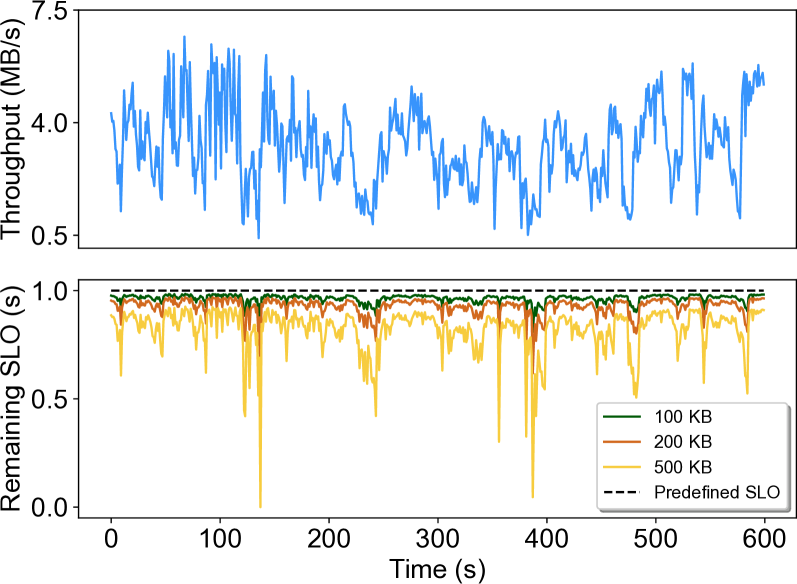
- However, production traces show low request arrival rates, leading to long batching times and SLO violations
- There is a need for batching multiple DNN inference requests with diverse SLOs (multi-SLO DNN inference) on serverless platforms
- The potential benefits of deploying heterogeneous (CPU and GPU) functions for DNN inference have not been thoroughly explored
Plain English Explanation
In the world of cloud computing, Deep Neural Network (DNN) inference on serverless functions is becoming increasingly important. Serverless functions allow businesses to run their applications without having to manage the underlying infrastructure, which can lead to substantial cost savings.
Existing research has focused on optimizing the process of batching multiple requests for DNN inference from a single application, with a specific Service Level Objective (SLO) for the CPU functions. However, real-world data shows that the rate at which these requests arrive is often surprisingly low. This can lead to long wait times and SLO violations, where the application's performance doesn't meet the promised standards.
To address this issue, the researchers propose the need for a system that can batch multiple DNN inference requests with diverse SLOs (i.e., different performance targets) on serverless platforms. Additionally, they suggest that the potential benefits of using heterogeneous functions (both CPU and GPU) for DNN inference have not been thoroughly explored.
Technical Explanation
The researchers present HarmonyBatch, a cost-efficient resource provisioning framework designed to provide predictable performance for multi-SLO DNN inference with heterogeneous serverless functions.
First, they construct an analytical performance and cost model of DNN inference on both CPU and GPU functions, taking into account the GPU time-slicing scheduling mechanism and request arrival rate distribution.
Based on this model, they devise a two-stage merging strategy in HarmonyBatch to batch the multi-SLO DNN inference requests into application groups. The goal is to minimize the budget for function provisioning while guaranteeing diverse performance SLOs for the inference applications.
The researchers have implemented a prototype of HarmonyBatch on Alibaba Cloud Function Compute. Extensive experiments with representative DNN inference workloads demonstrate that HarmonyBatch can provide predictable performance to serverless DNN inference workloads while reducing the monetary cost by up to 82.9% compared to state-of-the-art methods.
Critical Analysis
The researchers have identified an important problem in the realm of serverless DNN inference, where low request arrival rates can lead to SLO violations. Their proposed solution, HarmonyBatch, aims to address this issue by batching multiple DNN inference requests with diverse SLOs and leveraging heterogeneous serverless functions.
While the analytical modeling and experimental results presented in the paper are promising, there are a few potential limitations and areas for further research:
-
Scalability: The paper does not explicitly discuss the scalability of HarmonyBatch as the number of applications or the complexity of DNN models increases. Further investigation into the system's performance under larger-scale deployments would be valuable.
-
Real-world Deployment: The evaluation was conducted on a prototype running on Alibaba Cloud. Applying HarmonyBatch to other serverless platforms and real-world production environments could reveal additional challenges or considerations.
-
Heterogeneous Function Utilization: The paper focuses on the potential benefits of using heterogeneous functions (CPU and GPU) for DNN inference, but it would be helpful to understand the trade-offs and optimal utilization strategies for these different function types.
-
Multi-tenant Scenarios: The current work assumes a single-tenant environment. Exploring the multi-tenant case, where multiple applications share the same serverless resources, could uncover additional complexities and optimization opportunities.
Conclusion
The researchers have presented HarmonyBatch, a cost-efficient resource provisioning framework for multi-SLO DNN inference on serverless platforms. By batching requests with diverse SLOs and leveraging heterogeneous functions, HarmonyBatch can provide predictable performance while significantly reducing monetary costs compared to existing methods.
This research highlights the importance of addressing the challenges posed by low request arrival rates in serverless DNN inference, and the potential benefits of exploring heterogeneous function deployments. As the adoption of serverless computing and DNN-powered applications continues to grow, solutions like HarmonyBatch could play a crucial role in optimizing the performance and cost-efficiency of these systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤯
0
HarmonyBatch: Batching multi-SLO DNN Inference with Heterogeneous Serverless Functions
Jiabin Chen, Fei Xu, Yikun Gu, Li Chen, Fangming Liu, Zhi Zhou
Deep Neural Network (DNN) inference on serverless functions is gaining prominence due to its potential for substantial budget savings. Existing works on serverless DNN inference solely optimize batching requests from one application with a single Service Level Objective (SLO) on CPU functions. However, production serverless DNN inference traces indicate that the request arrival rate of applications is surprisingly low, which inevitably causes a long batching time and SLO violations. Hence, there is an urgent need for batching multiple DNN inference requests with diverse SLOs (i.e., multi-SLO DNN inference) in serverless platforms. Moreover, the potential performance and cost benefits of deploying heterogeneous (i.e., CPU and GPU) functions for DNN inference have received scant attention. In this paper, we present HarmonyBatch, a cost-efficient resource provisioning framework designed to achieve predictable performance for multi-SLO DNN inference with heterogeneous serverless functions. Specifically, we construct an analytical performance and cost model of DNN inference on both CPU and GPU functions, by explicitly considering the GPU time-slicing scheduling mechanism and request arrival rate distribution. Based on such a model, we devise a two-stage merging strategy in HarmonyBatch to judiciously batch the multi-SLO DNN inference requests into application groups. It aims to minimize the budget of function provisioning for each application group while guaranteeing diverse performance SLOs of inference applications. We have implemented a prototype of HarmonyBatch on Alibaba Cloud Function Compute. Extensive prototype experiments with representative DNN inference workloads demonstrate that HarmonyBatch can provide predictable performance to serverless DNN inference workloads while reducing the monetary cost by up to 82.9% compared to the state-of-the-art methods.
Read more5/10/2024
0
Sponge: Inference Serving with Dynamic SLOs Using In-Place Vertical Scaling
Kamran Razavi, Saeid Ghafouri, Max Muhlhauser, Pooyan Jamshidi, Lin Wang
Mobile and IoT applications increasingly adopt deep learning inference to provide intelligence. Inference requests are typically sent to a cloud infrastructure over a wireless network that is highly variable, leading to the challenge of dynamic Service Level Objectives (SLOs) at the request level. This paper presents Sponge, a novel deep learning inference serving system that maximizes resource efficiency while guaranteeing dynamic SLOs. Sponge achieves its goal by applying in-place vertical scaling, dynamic batching, and request reordering. Specifically, we introduce an Integer Programming formulation to capture the resource allocation problem, providing a mathematical model of the relationship between latency, batch size, and resources. We demonstrate the potential of Sponge through a prototype implementation and preliminary experiments and discuss future works.
Read more4/24/2024

0
Tangram: High-resolution Video Analytics on Serverless Platform with SLO-aware Batching
Haosong Peng, Yufeng Zhan, Peng Li, Yuanqing Xia
Cloud-edge collaborative computing paradigm is a promising solution to high-resolution video analytics systems. The key lies in reducing redundant data and managing fluctuating inference workloads effectively. Previous work has focused on extracting regions of interest (RoIs) from videos and transmitting them to the cloud for processing. However, a naive Infrastructure as a Service (IaaS) resource configuration falls short in handling highly fluctuating workloads, leading to violations of Service Level Objectives (SLOs) and inefficient resource utilization. Besides, these methods neglect the potential benefits of RoIs batching to leverage parallel processing. In this work, we introduce Tangram, an efficient serverless cloud-edge video analytics system fully optimized for both communication and computation. Tangram adaptively aligns the RoIs into patches and transmits them to the scheduler in the cloud. The system employs a unique ``stitching'' method to batch the patches with various sizes from the edge cameras. Additionally, we develop an online SLO-aware batching algorithm that judiciously determines the optimal invoking time of the serverless function. Experiments on our prototype reveal that Tangram can reduce bandwidth consumption and computation cost up to 74.30% and 66.35%, respectively, while maintaining SLO violations within 5% and the accuracy loss negligible.
Read more4/16/2024
🤿
0
Deep Learning Inference on Heterogeneous Mobile Processors: Potentials and Pitfalls
Sicong Liu, Wentao Zhou, Zimu Zhou, Bin Guo, Minfan Wang, Cheng Fang, Zheng Lin, Zhiwen Yu
There is a growing demand to deploy computation-intensive deep learning (DL) models on resource-constrained mobile devices for real-time intelligent applications. Equipped with a variety of processing units such as CPUs, GPUs, and NPUs, the mobile devices hold potential to accelerate DL inference via parallel execution across heterogeneous processors. Various efficient parallel methods have been explored to optimize computation distribution, achieve load balance, and minimize communication cost across processors. Yet their practical effectiveness in the dynamic and diverse real-world mobile environment is less explored. This paper presents a holistic empirical study to assess the capabilities and challenges associated with parallel DL inference on heterogeneous mobile processors. Through carefully designed experiments covering various DL models, mobile software/hardware environments, workload patterns, and resource availability, we identify limitations of existing techniques and highlight opportunities for cross-level optimization.
Read more5/6/2024