Harnessing Earnings Reports for Stock Predictions: A QLoRA-Enhanced LLM Approach

0

Sign in to get full access
Overview
- Researchers propose a novel approach to stock prediction using a large language model (LLM) enhanced with Quantized Low-Rank Adaptation (QLoRA).
- The model is trained on corporate earnings reports to extract relevant signals for predicting stock prices.
- The technique aims to improve upon existing LLM-based approaches for financial analysis and forecasting.
Plain English Explanation
The paper explores a new way to forecast stock prices using a powerful large language model (LLM). The researchers take this LLM and apply a technique called Quantized Low-Rank Adaptation (QLoRA) to enhance its performance.
The key idea is to train this enhanced LLM on a large dataset of corporate earnings reports. These reports contain valuable information about a company's financial health and future outlook, which the model can then use to make predictions about the company's stock price.
By harnessing the natural language processing capabilities of the LLM, along with the QLoRA optimization, the researchers believe they can create a more accurate and reliable stock prediction system compared to existing approaches. The goal is to provide investors and traders with better insights to inform their investment decisions.
Technical Explanation
The paper presents a novel framework for stock price prediction that leverages a large language model (LLM) enhanced with Quantized Low-Rank Adaptation (QLoRA). The researchers train this QLoRA-enhanced LLM on a large corpus of corporate earnings reports, enabling the model to extract relevant signals for predicting future stock prices.
The QLoRA technique allows for efficient fine-tuning of the LLM, enabling it to specialize in the financial domain without significantly increasing the model size or computational requirements. The researchers leverage this to create a more targeted and effective stock prediction system compared to previous LLM-based approaches.
Through extensive experiments, the team demonstrates the effectiveness of their approach in forecasting stock prices, outperforming several benchmark models. The insights gained from the model's predictions can provide valuable information to investors, traders, and financial analysts.
Critical Analysis
The paper presents a compelling approach to leveraging LLMs for stock price prediction, with the integration of QLoRA optimization serving as a key innovation. However, the authors acknowledge several limitations and areas for further research:
-
The model's performance may be influenced by the quality and breadth of the earnings report data used for training. Ensuring the dataset is comprehensive and representative of the broader market is crucial.
-
The paper does not explore the model's ability to generalize to different market conditions or its robustness to external shocks, such as macroeconomic events. Further testing in varied market environments would be beneficial.
-
The authors mention the potential for incorporating additional data sources, such as news articles or social media sentiment, to enhance the model's predictive capabilities. Exploring these avenues could yield further improvements.
-
The interpretability of the model's decision-making process is not extensively discussed. Providing more insights into the specific factors and patterns the model uses to make predictions would enhance the model's transparency and trustworthiness.
Despite these limitations, the paper presents a valuable contribution to the field of financial forecasting using advanced language models. The QLoRA-enhanced LLM approach offers a promising direction for improving stock price prediction and supporting informed investment decisions.
Conclusion
The researchers have developed a novel framework that combines a large language model with Quantized Low-Rank Adaptation to harness the power of corporate earnings reports for stock price prediction. By leveraging the natural language processing capabilities of the LLM and the efficient fine-tuning provided by QLoRA, the model can extract relevant signals from earnings reports to make more accurate stock forecasts.
This work represents a significant advancement in the use of LLMs for financial analysis and decision-making. The insights gained from the model's predictions can assist investors, traders, and analysts in making informed investment decisions, potentially leading to improved portfolio performance and more efficient capital allocation in the financial markets.
As the field of AI-driven financial forecasting continues to evolve, the QLoRA-enhanced LLM approach presented in this paper offers a promising direction for further research and real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Harnessing Earnings Reports for Stock Predictions: A QLoRA-Enhanced LLM Approach
Haowei Ni, Shuchen Meng, Xupeng Chen, Ziqing Zhao, Andi Chen, Panfeng Li, Shiyao Zhang, Qifu Yin, Yuanqing Wang, Yuxi Chan
Accurate stock market predictions following earnings reports are crucial for investors. Traditional methods, particularly classical machine learning models, struggle with these predictions because they cannot effectively process and interpret extensive textual data contained in earnings reports and often overlook nuances that influence market movements. This paper introduces an advanced approach by employing Large Language Models (LLMs) instruction fine-tuned with a novel combination of instruction-based techniques and quantized low-rank adaptation (QLoRA) compression. Our methodology integrates 'base factors', such as financial metric growth and earnings transcripts, with 'external factors', including recent market indices performances and analyst grades, to create a rich, supervised dataset. This comprehensive dataset enables our models to achieve superior predictive performance in terms of accuracy, weighted F1, and Matthews correlation coefficient (MCC), especially evident in the comparison with benchmarks such as GPT-4. We specifically highlight the efficacy of the llama-3-8b-Instruct-4bit model, which showcases significant improvements over baseline models. The paper also discusses the potential of expanding the output capabilities to include a 'Hold' option and extending the prediction horizon, aiming to accommodate various investment styles and time frames. This study not only demonstrates the power of integrating cutting-edge AI with fine-tuned financial data but also paves the way for future research in enhancing AI-driven financial analysis tools.
Read more9/17/2024

0
ECC Analyzer: Extract Trading Signal from Earnings Conference Calls using Large Language Model for Stock Performance Prediction
Yupeng Cao, Zhi Chen, Qingyun Pei, Nathan Jinseok Lee, K. P. Subbalakshmi, Papa Momar Ndiaye
In the realm of financial analytics, leveraging unstructured data, such as earnings conference calls (ECCs), to forecast stock volatility is a critical challenge that has attracted both academics and investors. While previous studies have used multimodal deep learning-based models to obtain a general view of ECCs for volatility predicting, they often fail to capture detailed, complex information. Our research introduces a novel framework: textbf{ECC Analyzer}, which utilizes large language models (LLMs) to extract richer, more predictive content from ECCs to aid the model's prediction performance. We use the pre-trained large models to extract textual and audio features from ECCs and implement a hierarchical information extraction strategy to extract more fine-grained information. This strategy first extracts paragraph-level general information by summarizing the text and then extracts fine-grained focus sentences using Retrieval-Augmented Generation (RAG). These features are then fused through multimodal feature fusion to perform volatility prediction. Experimental results demonstrate that our model outperforms traditional analytical benchmarks, confirming the effectiveness of advanced LLM techniques in financial analysis.
Read more9/2/2024

0
Financial Statement Analysis with Large Language Models
Alex Kim, Maximilian Muhn, Valeri Nikolaev
We investigate whether an LLM can successfully perform financial statement analysis in a way similar to a professional human analyst. We provide standardized and anonymous financial statements to GPT4 and instruct the model to analyze them to determine the direction of future earnings. Even without any narrative or industry-specific information, the LLM outperforms financial analysts in its ability to predict earnings changes. The LLM exhibits a relative advantage over human analysts in situations when the analysts tend to struggle. Furthermore, we find that the prediction accuracy of the LLM is on par with the performance of a narrowly trained state-of-the-art ML model. LLM prediction does not stem from its training memory. Instead, we find that the LLM generates useful narrative insights about a company's future performance. Lastly, our trading strategies based on GPT's predictions yield a higher Sharpe ratio and alphas than strategies based on other models. Taken together, our results suggest that LLMs may take a central role in decision-making.
Read more7/26/2024
0
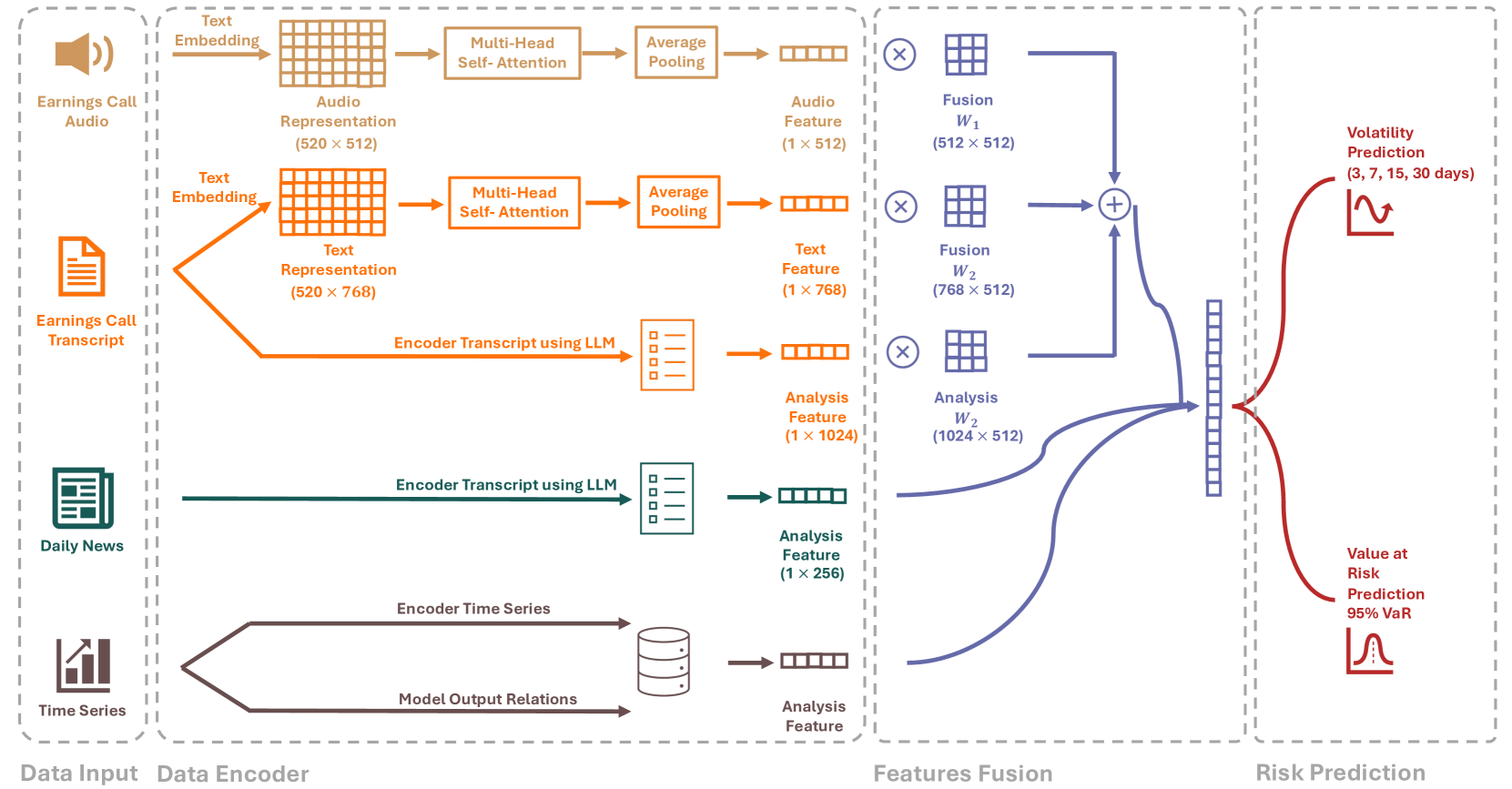
RiskLabs: Predicting Financial Risk Using Large Language Model Based on Multi-Sources Data
Yupeng Cao, Zhi Chen, Qingyun Pei, Fabrizio Dimino, Lorenzo Ausiello, Prashant Kumar, K. P. Subbalakshmi, Papa Momar Ndiaye
The integration of Artificial Intelligence (AI) techniques, particularly large language models (LLMs), in finance has garnered increasing academic attention. Despite progress, existing studies predominantly focus on tasks like financial text summarization, question-answering (Q$&$A), and stock movement prediction (binary classification), with a notable gap in the application of LLMs for financial risk prediction. Addressing this gap, in this paper, we introduce textbf{RiskLabs}, a novel framework that leverages LLMs to analyze and predict financial risks. RiskLabs uniquely combines different types of financial data, including textual and vocal information from Earnings Conference Calls (ECCs), market-related time series data, and contextual news data surrounding ECC release dates. Our approach involves a multi-stage process: initially extracting and analyzing ECC data using LLMs, followed by gathering and processing time-series data before the ECC dates to model and understand risk over different timeframes. Using multimodal fusion techniques, RiskLabs amalgamates these varied data features for comprehensive multi-task financial risk prediction. Empirical experiment results demonstrate RiskLab's effectiveness in forecasting both volatility and variance in financial markets. Through comparative experiments, we demonstrate how different data sources contribute to financial risk assessment and discuss the critical role of LLMs in this context. Our findings not only contribute to the AI in finance application but also open new avenues for applying LLMs in financial risk assessment.
Read more4/12/2024