Heterogeneous Federated Learning with Splited Language Model
2403.16050
0
0

Abstract
Federated Split Learning (FSL) is a promising distributed learning paradigm in practice, which gathers the strengths of both Federated Learning (FL) and Split Learning (SL) paradigms, to ensure model privacy while diminishing the resource overhead of each client, especially on large transformer models in a resource-constrained environment, e.g., Internet of Things (IoT). However, almost all works merely investigate the performance with simple neural network models in FSL. Despite the minor efforts focusing on incorporating Vision Transformers (ViT) as model architectures, they train ViT from scratch, thereby leading to enormous training overhead in each device with limited resources. Therefore, in this paper, we harness Pre-trained Image Transformers (PITs) as the initial model, coined FedV, to accelerate the training process and improve model robustness. Furthermore, we propose FedVZ to hinder the gradient inversion attack, especially having the capability compatible with black-box scenarios, where the gradient information is unavailable. Concretely, FedVZ approximates the server gradient by utilizing a zeroth-order (ZO) optimization, which replaces the backward propagation with just one forward process. Empirically, we are the first to provide a systematic evaluation of FSL methods with PITs in real-world datasets, different partial device participations, and heterogeneous data splits. Our experiments verify the effectiveness of our algorithms.
Create account to get full access
Overview
- This paper proposes a federated split learning approach with pre-trained image transformers to address the challenge of heterogeneous data in federated learning.
- The approach aims to leverage the power of pre-trained vision transformers while maintaining the privacy and efficiency benefits of federated learning.
- It introduces a novel technique called "make split, not hijack" to prevent feature space hijacking, a common issue in federated learning.
Plain English Explanation
Federated learning is a way for multiple devices or organizations to train a machine learning model together without sharing their private data. However, when the data across devices is very different (heterogeneous), it can be challenging to train an effective model.
This paper presents a solution that combines the strengths of federated learning and pre-trained vision transformers. Vision transformers are powerful deep learning models that can extract useful features from images. By using a pre-trained vision transformer as the backbone of the federated learning model, the approach can leverage these powerful features even when the image data on different devices is quite different.
To further improve the effectiveness of this approach, the researchers introduce a new technique called "make split, not hijack." This helps prevent a common issue in federated learning where the model ends up focusing too much on features that are specific to one device's data, rather than learning general features that work well across all the devices. The "make split, not hijack" method ensures the model learns more robust and generalizable features.
Technical Explanation
The key technical contributions of this paper are:
-
Incorporating pre-trained vision transformers into a federated split learning framework to handle heterogeneous image data across devices. This allows the model to leverage powerful feature extraction capabilities even when the local data distributions differ greatly.
-
Introducing a "make split, not hijack" technique to prevent feature space hijacking. This involves dynamically adjusting the model architecture and training procedure to encourage the local models to learn more generalizable features, rather than overfitting to device-specific characteristics.
-
Extensive experiments on benchmark federated learning datasets, demonstrating significant performance improvements over prior federated learning approaches, especially in scenarios with high data heterogeneity.
The paper provides a detailed technical description of the federated split learning algorithm, the "make split, not hijack" method, and the experimental setup and results.
Critical Analysis
The paper makes a strong contribution by addressing a key challenge in federated learning - handling heterogeneous data across devices. The proposed approach of leveraging pre-trained vision transformers is a clever way to inject powerful feature extraction capabilities into the federated learning framework.
However, the paper does not discuss potential limitations or caveats of the approach. For example, it's unclear how the method would scale to very large numbers of participating devices, or how sensitive the performance is to the quality and relevance of the pre-trained vision transformer model.
Additionally, the paper does not provide much insight into the computational and communication efficiency of the federated split learning approach compared to alternatives. This is an important practical consideration for real-world federated learning deployments.
Further research could explore the robustness of the "make split, not hijack" technique, its generalizability to other model architectures and data modalities, and more comprehensive benchmarking against state-of-the-art federated learning methods.
Conclusion
This paper presents an innovative federated split learning approach that leverages pre-trained vision transformers to address the challenge of heterogeneous data in federated learning. By combining the strengths of federated learning and powerful pre-trained models, the approach can achieve significant performance improvements, especially in scenarios with high data diversity across devices.
The introduction of the "make split, not hijack" technique is a notable contribution that helps prevent a common issue in federated learning, enabling the model to learn more generalizable features. Overall, this research represents an important step forward in developing effective federated learning solutions for real-world applications with heterogeneous data.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Non-Federated Multi-Task Split Learning for Heterogeneous Sources
Yilin Zheng, Atilla Eryilmaz
0
0
With the development of edge networks and mobile computing, the need to serve heterogeneous data sources at the network edge requires the design of new distributed machine learning mechanisms. As a prevalent approach, Federated Learning (FL) employs parameter-sharing and gradient-averaging between clients and a server. Despite its many favorable qualities, such as convergence and data-privacy guarantees, it is well-known that classic FL fails to address the challenge of data heterogeneity and computation heterogeneity across clients. Most existing works that aim to accommodate such sources of heterogeneity stay within the FL operation paradigm, with modifications to overcome the negative effect of heterogeneous data. In this work, as an alternative paradigm, we propose a Multi-Task Split Learning (MTSL) framework, which combines the advantages of Split Learning (SL) with the flexibility of distributed network architectures. In contrast to the FL counterpart, in this paradigm, heterogeneity is not an obstacle to overcome, but a useful property to take advantage of. As such, this work aims to introduce a new architecture and methodology to perform multi-task learning for heterogeneous data sources efficiently, with the hope of encouraging the community to further explore the potential advantages we reveal. To support this promise, we first show through theoretical analysis that MTSL can achieve fast convergence by tuning the learning rate of the server and clients. Then, we compare the performance of MTSL with existing multi-task FL methods numerically on several image classification datasets to show that MTSL has advantages over FL in training speed, communication cost, and robustness to heterogeneous data.
6/4/2024
🔎
Have Your Cake and Eat It Too: Toward Efficient and Accurate Split Federated Learning
Dengke Yan, Ming Hu, Zeke Xia, Yanxin Yang, Jun Xia, Xiaofei Xie, Mingsong Chen
0
0
Due to its advantages in resource constraint scenarios, Split Federated Learning (SFL) is promising in AIoT systems. However, due to data heterogeneity and stragglers, SFL suffers from the challenges of low inference accuracy and low efficiency. To address these issues, this paper presents a novel SFL approach, named Sliding Split Federated Learning (S$^2$FL), which adopts an adaptive sliding model split strategy and a data balance-based training mechanism. By dynamically dispatching different model portions to AIoT devices according to their computing capability, S$^2$FL can alleviate the low training efficiency caused by stragglers. By combining features uploaded by devices with different data distributions to generate multiple larger batches with a uniform distribution for back-propagation, S$^2$FL can alleviate the performance degradation caused by data heterogeneity. Experimental results demonstrate that, compared to conventional SFL, S$^2$FL can achieve up to 16.5% inference accuracy improvement and 3.54X training acceleration.
4/9/2024
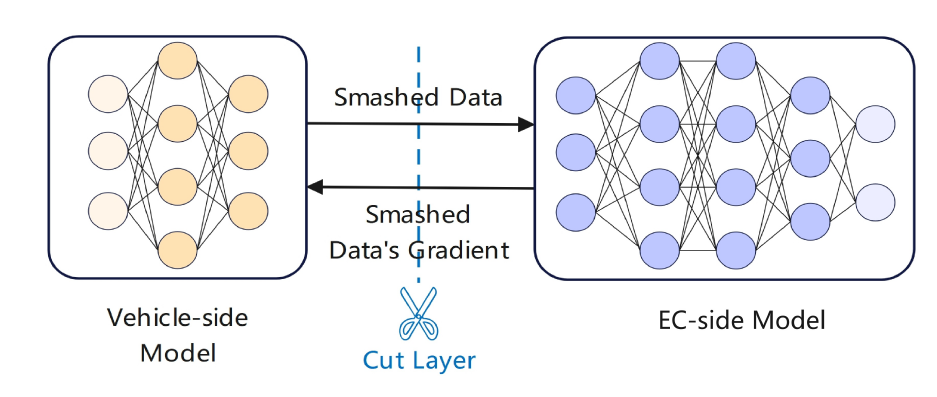
Adaptive and Parallel Split Federated Learning in Vehicular Edge Computing
Xianke Qiang, Zheng Chang, Yun Hu, Lei Liu, Timo Hamalainen
0
0
Vehicular edge intelligence (VEI) is a promising paradigm for enabling future intelligent transportation systems by accommodating artificial intelligence (AI) at the vehicular edge computing (VEC) system. Federated learning (FL) stands as one of the fundamental technologies facilitating collaborative model training locally and aggregation, while safeguarding the privacy of vehicle data in VEI. However, traditional FL faces challenges in adapting to vehicle heterogeneity, training large models on resource-constrained vehicles, and remaining susceptible to model weight privacy leakage. Meanwhile, split learning (SL) is proposed as a promising collaborative learning framework which can mitigate the risk of model wights leakage, and release the training workload on vehicles. SL sequentially trains a model between a vehicle and an edge cloud (EC) by dividing the entire model into a vehicle-side model and an EC-side model at a given cut layer. In this work, we combine the advantages of SL and FL to develop an Adaptive Split Federated Learning scheme for Vehicular Edge Computing (ASFV). The ASFV scheme adaptively splits the model and parallelizes the training process, taking into account mobile vehicle selection and resource allocation. Our extensive simulations, conducted on non-independent and identically distributed data, demonstrate that the proposed ASFV solution significantly reduces training latency compared to existing benchmarks, while adapting to network dynamics and vehicles' mobility.
5/30/2024

Optimizing Split Points for Error-Resilient SplitFed Learning
Chamani Shiranthika, Parvaneh Saeedi, Ivan V. Baji'c
0
0
Recent advancements in decentralized learning, such as Federated Learning (FL), Split Learning (SL), and Split Federated Learning (SplitFed), have expanded the potentials of machine learning. SplitFed aims to minimize the computational burden on individual clients in FL and parallelize SL while maintaining privacy. This study investigates the resilience of SplitFed to packet loss at model split points. It explores various parameter aggregation strategies of SplitFed by examining the impact of splitting the model at different points-either shallow split or deep split-on the final global model performance. The experiments, conducted on a human embryo image segmentation task, reveal a statistically significant advantage of a deeper split point.
5/31/2024