HGT: Leveraging Heterogeneous Graph-enhanced Large Language Models for Few-shot Complex Table Understanding
2403.19723
0
0

Abstract
Table understanding (TU) has achieved promising advancements, but it faces the challenges of the scarcity of manually labeled tables and the presence of complex table structures.To address these challenges, we propose HGT, a framework with a heterogeneous graph (HG)-enhanced large language model (LLM) to tackle few-shot TU tasks.It leverages the LLM by aligning the table semantics with the LLM's parametric knowledge through soft prompts and instruction turning and deals with complex tables by a multi-task pre-training scheme involving three novel multi-granularity self-supervised HG pre-training objectives.We empirically demonstrate the effectiveness of HGT, showing that it outperforms the SOTA for few-shot complex TU on several benchmarks.
Create account to get full access
Introduction
The paper discusses the challenges of Table Understanding (TU), which aims to learn informative embeddings of tables with inherent tabular semantics. TU faces two main challenges: lack of sufficient human annotations and the presence of complex table structures. Existing frameworks require considerable amounts of labeled data for task-specific fine-tuning, even when using pre-training with encoder-only architectures. Additionally, current methods that attempt to capture structural information in tables through position embeddings or modeling tables as graphs are effective for simple tables but struggle with complex tables due to the intricate cell-to-cell relationships.
The paper introduces HGT, a heterogeneous graph-enhanced large language model framework for few-shot complex table understanding. HGT addresses challenges in complex table understanding by integrating multimodal large language models and self-supervised heterogeneous graph pre-training techniques. The framework models tabular data as a heterogeneous graph, processes it through a tabular graph encoder to generate vectors with structural information, and aligns the representation spaces of the encoder and the language model via instruction tuning. Three multi-granularity self-supervised tasks are designed for pre-training HGT, enabling it to adapt to downstream tasks with minimal data samples. Comparative experiments on eight datasets demonstrate HGT's superior performance compared to state-of-the-art methods for few-shot complex table understanding across multiple benchmark datasets.
Related Work
The paper discusses various approaches to table understanding and question answering. Graph-based methods convert tables into graphs to capture topological information but struggle with complex table structures. LLM-based approaches leverage the generalization capacity of large language models but lose intrinsic topological information when converting tables into row-by-row natural language format. Query statement-based techniques transform tables into formats interpretable by query languages like SQL and use Codex to generate query statements for retrieving answers, representing the current state-of-the-art in Table QA. However, this approach has limited applicability to other table-related tasks. BERT-like encoder-only models have been designed with specialized encoding methods and pre-training objectives for tabular data. Despite using self-supervised training, these methods still require substantial labeled data for fine-tuning and do not effectively capture topological information.
Task Definition
The paper introduces a table T with N rows and M columns, where each cell is denoted as c_{i,j}. Merged cells, which span multiple rows or columns, are common in complex tables. The coordinates of merged cells are based on the top-left cell before merging.
The paper discusses two sub-tasks for table understanding: Cell Type Classification (CTC) and Table Type Classification (TTC). CTC involves identifying the type y_c of each cell c_{i,j} within a table T, where y_c can belong to a basic taxonomy Y_c = {header cell, data cell} or a more complex one. TTC is a table-level categorization task that requires models to classify the table T according to a specific taxonomy Y_t.
The paper also mentions the Table QA task, which requires the model to produce an answer y_a in response to a natural language question q, using table T as the reference for deriving the answer.
METHODOLOGY

The paper describes a three-phase process for training a model called HGT to understand and process complex tables:
-
Tabular Heterogeneous Graph (HG) Construction: Tables are converted into HGs, which capture diverse relationships more effectively than homogeneous graphs. The conversion process involves creating nodes for tables, rows, header cells, and data cells, initializing node embeddings, and adding edges based on heuristic rules.
-
Stage 1 - Self-supervised Instruction Tuning: An RGNN encoder generates vector representations for the tabular nodes, which serve as soft prompts for the language model (LLM) input. The weights of both modules are tuned through self-supervised tasks to align their vector representation spaces. Three tasks of increasing complexity are used: Table Row Classification, Table Cell Matching, and Table Context Generation.
-
Stage 2 - Task-specific Instruction Tuning: After aligning the representation spaces in Stage 1, HGT can effectively understand the topological nuances of complex tables. For specific downstream tasks, HGT requires only a small number of training samples to grasp the expected answer format and reorganize its pre-existing knowledge. During fine-tuning, only the HG Encoder parameters are tuned, while the rest remain frozen.
Experiments
The paper validates the effectiveness of the proposed HGT model on various datasets relevant to Column Type Classification (CTC), Table Type Classification (TTC), and Table Question Answering (Table QA). The datasets include TURL, WCC, IM-TQA, HiTab, WTQ (Flatten), and WTQ (Raw). Statistics for these datasets are provided, highlighting differences in annotations, domains, and the proportion of complex tables.
HGT is compared with eight baselines categorized into four groups based on their frameworks: ForTap and GetPt, TabularNet and TabPrompt, Binder and Aug-Codex, and TableLlama and GPT-3.5. Implementation details for HGT are provided, including the use of Vicuna-7B-v1.5 as the base model, a 2-layer RGAT as the tabular HG encoder, and Sentence-BERT for initial node vectors. The model is trained on a comprehensive dataset of 100k tables.
Experimental results show that HGT achieves the best performance on 7 out of 8 datasets, with Binder outperforming HGT only on the WTQ (Raw) dataset. The analysis highlights the effectiveness of HGT in processing complex table structures and mitigating the drawbacks of linearized table representations.
Ablation studies on the IM-TQA dataset validate the effectiveness of each component and self-supervised objective in HGT. The three pre-training tasks (TRC, TCM, and TCG) prove beneficial across all table evaluation tasks, with TCM offering the most substantial enhancement. The method of converting tables into heterogeneous graphs and using a heuristic linking strategy also contributes to HGT's performance.
Conclusion
The paper introduces HGT, a new framework designed for few-shot complex table understanding (TU). HGT's effectiveness is demonstrated through evaluations on various datasets for cell type classification (CTC), table type classification (TTC), and table question answering (Table QA). The paper also includes a comprehensive ablation study to analyze the contribution of each component within HGT. Future research directions involve extending HGT to handle tables with more diverse layouts and improving its performance in Table QA tasks by incorporating techniques that boost the model's inference abilities.
tations
The paper highlights three main limitations of the HGT (Hierarchical Graph Transformer) model when processing tables:
-
Performance decline: HGT's performance significantly decreases when handling tables with irregular layouts, including tables containing sub-titles, images, or forms filled with personalized information.
-
High GPU memory consumption: HGT tends to use excessive GPU memory when processing larger tables, which can be a constraint.
-
Excel-type form compatibility: When dealing with Excel-type forms, an additional step is required to convert them to html-format tables using an API before HGT can process them effectively.
Appendix A Datasets and Pre-processing
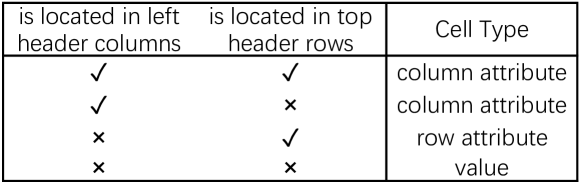
The paper describes several datasets used for table understanding tasks:
-
IM-TQA: A Chinese dataset with tables from encyclopedias and reports, translated into English. The tables are annotated for Cell Type Classification (CTC), Table Type Classification (TTC), and Table Question Answering (QA). Vertical tables are pre-processed and converted into horizontal tables using feature engineering, with 98% accuracy.
-
HiTab: Contains hierarchical matrix tables from statistical reports and Wikipedia articles, annotated for row and column granularity and Table QA. The annotations are transformed into cell-level annotations.
-
WTQ (Flatten) and WTQ (Raw): Originate from the same work and consist of Wikipedia tables with questions involving basic arithmetic operations and compositional reasoning. In WTQ (Flatten), the hierarchical structure of header rows is converted into a single row to simplify the Table QA task.
-
WCC: A subset of the July 2015 Common Crawl, annotated for TTC using a web table taxonomy. The dataset is not explicitly divided into training and test sets, so 353 tables are used as the test set. Tables with more than 150 cells are excluded due to GPU memory limitations.
Appendix B Top Header Row Number
Algorithm 1 determines the top header row number in a table using a heuristic rule. Algorithm 2 classifies the type of each row in a table.
Appendix C Setup of Baselines
The section discusses the setup of baselines for the study. GetPt and Aug-Codex have not released their source code publicly, requiring the authors to replicate their framework based on the details in their respective papers. TableLlama, which was not trained using the Cell Type Classification (CTC) and Table Type Classification (TTC) datasets, performs suboptimally when inputs are presented with in-context prompts during testing. To improve its performance, the authors fine-tuned TableLlama's parameters using few-shot training data before testing. However, since TableLlama was trained on a large amount of data from the HiTab dataset, its test results do not represent few-shot performance. For testing GPT-3.5, API calls were used, and the training data was included as in-context prompts during the test phase.
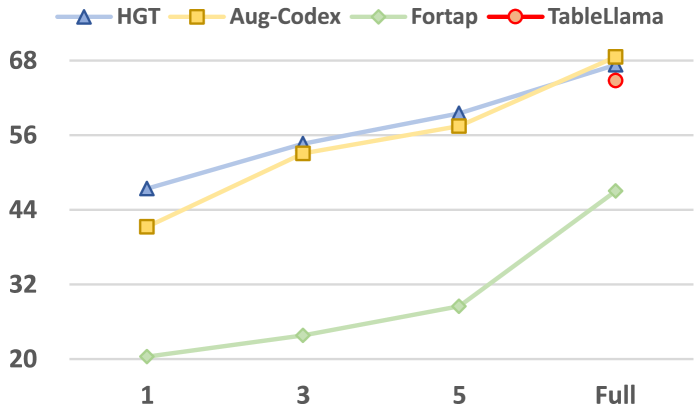
Appendix D Results of varied training shots on HiTab
The performance of HGT is compared with Aug-codex, Fortap, and Tablellama baselines under different numbers of training samples. The accuracy is plotted against the number of training samples, which include 1, 3, 5, and full settings. Full settings refer to using any amount of data from the training set until optimal results are achieved. Tablellama's accuracy is only reported in full settings as it uses HiTab training data during training. HGT performs best with a limited number of samples and remains competitive with the state-of-the-art Aug-Codex even in full settings.


Appendix E Downstream Table-related Task Examples
The image referenced in the text, Fig. 9, shows example inputs for three different tasks: CTC, TTC, and Table QA. However, the actual image is not provided in the text snippet, so no details can be gleaned about the specific example inputs shown for each task.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
HeLM: Highlighted Evidence augmented Language Model for Enhanced Table-to-Text Generation
Junyi Bian, Xiaolei Qin, Wuhe Zou, Mengzuo Huang, Congyi Luo, Ke Zhang, Weidong Zhang
0
0
Large models have demonstrated significant progress across various domains, particularly in tasks related to text generation. In the domain of Table to Text, many Large Language Model (LLM)-based methods currently resort to modifying prompts to invoke public APIs, incurring potential costs and information leaks. With the advent of open-source large models, fine-tuning LLMs has become feasible. In this study, we conducted parameter-efficient fine-tuning on the LLaMA2 model. Distinguishing itself from previous fine-tuning-based table-to-text methods, our approach involves injecting reasoning information into the input by emphasizing table-specific row data. Our model consists of two modules: 1) a table reasoner that identifies relevant row evidence, and 2) a table summarizer that generates sentences based on the highlighted table. To facilitate this, we propose a search strategy to construct reasoning labels for training the table reasoner. On both the FetaQA and QTSumm datasets, our approach achieved state-of-the-art results. Additionally, we observed that highlighting input tables significantly enhances the model's performance and provides valuable interpretability.
4/30/2024

Multimodal Table Understanding
Mingyu Zheng, Xinwei Feng, Qingyi Si, Qiaoqiao She, Zheng Lin, Wenbin Jiang, Weiping Wang
0
0
Although great progress has been made by previous table understanding methods including recent approaches based on large language models (LLMs), they rely heavily on the premise that given tables must be converted into a certain text sequence (such as Markdown or HTML) to serve as model input. However, it is difficult to access such high-quality textual table representations in some real-world scenarios, and table images are much more accessible. Therefore, how to directly understand tables using intuitive visual information is a crucial and urgent challenge for developing more practical applications. In this paper, we propose a new problem, multimodal table understanding, where the model needs to generate correct responses to various table-related requests based on the given table image. To facilitate both the model training and evaluation, we construct a large-scale dataset named MMTab, which covers a wide spectrum of table images, instructions and tasks. On this basis, we develop Table-LLaVA, a generalist tabular multimodal large language model (MLLM), which significantly outperforms recent open-source MLLM baselines on 23 benchmarks under held-in and held-out settings. The code and data is available at this https://github.com/SpursGoZmy/Table-LLaVA
6/13/2024

HiGPT: Heterogeneous Graph Language Model
Jiabin Tang, Yuhao Yang, Wei Wei, Lei Shi, Long Xia, Dawei Yin, Chao Huang
0
0
Heterogeneous graph learning aims to capture complex relationships and diverse relational semantics among entities in a heterogeneous graph to obtain meaningful representations for nodes and edges. Recent advancements in heterogeneous graph neural networks (HGNNs) have achieved state-of-the-art performance by considering relation heterogeneity and using specialized message functions and aggregation rules. However, existing frameworks for heterogeneous graph learning have limitations in generalizing across diverse heterogeneous graph datasets. Most of these frameworks follow the pre-train and fine-tune paradigm on the same dataset, which restricts their capacity to adapt to new and unseen data. This raises the question: Can we generalize heterogeneous graph models to be well-adapted to diverse downstream learning tasks with distribution shifts in both node token sets and relation type heterogeneity?'' To tackle those challenges, we propose HiGPT, a general large graph model with Heterogeneous graph instruction-tuning paradigm. Our framework enables learning from arbitrary heterogeneous graphs without the need for any fine-tuning process from downstream datasets. To handle distribution shifts in heterogeneity, we introduce an in-context heterogeneous graph tokenizer that captures semantic relationships in different heterogeneous graphs, facilitating model adaptation. We incorporate a large corpus of heterogeneity-aware graph instructions into our HiGPT, enabling the model to effectively comprehend complex relation heterogeneity and distinguish between various types of graph tokens. Furthermore, we introduce the Mixture-of-Thought (MoT) instruction augmentation paradigm to mitigate data scarcity by generating diverse and informative instructions. Through comprehensive evaluations, our proposed framework demonstrates exceptional performance in terms of generalization performance.
5/21/2024

Large Scale Transfer Learning for Tabular Data via Language Modeling
Josh Gardner, Juan C. Perdomo, Ludwig Schmidt
0
0
Tabular data -- structured, heterogeneous, spreadsheet-style data with rows and columns -- is widely used in practice across many domains. However, while recent foundation models have reduced the need for developing task-specific datasets and predictors in domains such as language modeling and computer vision, this transfer learning paradigm has not had similar impact in the tabular domain. In this work, we seek to narrow this gap and present TabuLa-8B, a language model for tabular prediction. We define a process for extracting a large, high-quality training dataset from the TabLib corpus, proposing methods for tabular data filtering and quality control. Using the resulting dataset, which comprises over 1.6B rows from 3.1M unique tables, we fine-tune a Llama 3-8B large language model (LLM) for tabular data prediction (classification and binned regression) using a novel packing and attention scheme for tabular prediction. Through evaluation across a test suite of 329 datasets, we find that TabuLa-8B has zero-shot accuracy on unseen tables that is over 15 percentage points (pp) higher than random guessing, a feat that is not possible with existing state-of-the-art tabular prediction models (e.g. XGBoost, TabPFN). In the few-shot setting (1-32 shots), without any fine-tuning on the target datasets, TabuLa-8B is 5-15 pp more accurate than XGBoost and TabPFN models that are explicitly trained on equal, or even up to 16x more data. We release our model, code, and data along with the publication of this paper.
6/19/2024