HeLM: Highlighted Evidence augmented Language Model for Enhanced Table-to-Text Generation

0
💬
Sign in to get full access
Overview
- Large language models (LLMs) have shown significant progress in text generation tasks.
- In the domain of Table to Text, many LLM-based methods rely on modifying prompts to invoke public APIs, which can incur costs and potential information leaks.
- With the advent of open-source large models, fine-tuning LLMs has become more feasible.
- This study conducted parameter-efficient fine-tuning on the LLaMA2 model, focusing on injecting reasoning information into the input by emphasizing table-specific row data.
Plain English Explanation
Large language models (LLMs) are powerful AI systems that can generate human-like text. Researchers have found that these models can be particularly useful for transforming data in tables into readable text. However, many current methods for this "Table to Text" task rely on modifying the model's instructions (called "prompts") to use public APIs, which can be costly and raise privacy concerns.
The researchers in this study took a different approach. They fine-tuned an open-source LLM called LLaMA2, which means they trained it specifically on the Table to Text task. Crucially, they also taught the model to focus on the relevant rows of data in the tables, rather than just generating text based on the entire table. This allows the model to better understand the meaning and context of the data and produce more coherent and informative summaries.
The researchers' model consists of two parts: a "table reasoner" that identifies the key rows, and a "table summarizer" that generates the final text based on those highlighted rows. This approach led to state-of-the-art performance on two common Table to Text benchmark datasets.
Technical Explanation
The researchers in this study explored a parameter-efficient fine-tuning approach to train the LLaMA2 model for the Table to Text task. Rather than relying on prompting public APIs, as many previous methods have done, they focused on injecting reasoning information into the model's input.
Specifically, the researchers' model consists of two key components:
-
Table Reasoner: This module is responsible for identifying the relevant rows of data in the input table that should be emphasized when generating the final text summary.
-
Table Summarizer: This component takes the table data, along with the highlighted rows identified by the Table Reasoner, and generates the final text summary.
To train the Table Reasoner, the researchers developed a novel search strategy to construct "reasoning labels" that indicate which rows are most important. This allows the model to learn to focus on the relevant parts of the table during the summarization process.
The researchers evaluated their approach on two popular Table to Text datasets, FetaQA and QTSumm, and achieved state-of-the-art results. They also found that explicitly highlighting the relevant table rows significantly improved the model's performance and provided valuable interpretability, allowing users to better understand the model's reasoning.
Critical Analysis
The researchers' approach of fine-tuning the LLaMA2 model with a focus on table reasoning is a promising step forward in the field of Table to Text generation. By teaching the model to identify the most relevant rows of data, they were able to improve the coherence and informativeness of the generated summaries.
However, the paper does not address some potential limitations of this approach. For example, the researchers do not discuss how the model's performance might scale to larger or more complex tables, or how it might handle tables with missing or inconsistent data. Additionally, the study only evaluated the model on two specific datasets, and it's unclear how well the approach would generalize to other Table to Text tasks.
Furthermore, the researchers mention that their method involves "parameter-efficient fine-tuning," but they do not provide detailed comparisons to other fine-tuning approaches or discuss the specific efficiency improvements achieved. [Readers may be interested in exploring how this work relates to other efforts to advance large language models for tabular data.]
Overall, the researchers have made a valuable contribution to the field of Table to Text generation, but there is still room for further exploration and refinement of their approach.
Conclusion
This study presents a novel fine-tuning approach for training large language models on the Table to Text task. By incorporating table-specific reasoning into the model's input, the researchers were able to achieve state-of-the-art results on two benchmark datasets.
The key innovation of this work is the emphasis on identifying and highlighting the most relevant rows of data in the input tables. This allows the model to better understand the context and meaning of the information, leading to more coherent and informative text summaries.
While the study has some limitations, the researchers' approach represents a promising step forward in the field of data-to-text generation. As large language models continue to evolve, techniques like this that leverage domain-specific reasoning could become increasingly valuable for a wide range of real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
0
HeLM: Highlighted Evidence augmented Language Model for Enhanced Table-to-Text Generation
Junyi Bian, Xiaolei Qin, Wuhe Zou, Mengzuo Huang, Congyi Luo, Ke Zhang, Weidong Zhang
Large models have demonstrated significant progress across various domains, particularly in tasks related to text generation. In the domain of Table to Text, many Large Language Model (LLM)-based methods currently resort to modifying prompts to invoke public APIs, incurring potential costs and information leaks. With the advent of open-source large models, fine-tuning LLMs has become feasible. In this study, we conducted parameter-efficient fine-tuning on the LLaMA2 model. Distinguishing itself from previous fine-tuning-based table-to-text methods, our approach involves injecting reasoning information into the input by emphasizing table-specific row data. Our model consists of two modules: 1) a table reasoner that identifies relevant row evidence, and 2) a table summarizer that generates sentences based on the highlighted table. To facilitate this, we propose a search strategy to construct reasoning labels for training the table reasoner. On both the FetaQA and QTSumm datasets, our approach achieved state-of-the-art results. Additionally, we observed that highlighting input tables significantly enhances the model's performance and provides valuable interpretability.
Read more4/30/2024
💬
0
Table Meets LLM: Can Large Language Models Understand Structured Table Data? A Benchmark and Empirical Study
Yuan Sui, Mengyu Zhou, Mingjie Zhou, Shi Han, Dongmei Zhang
Large language models (LLMs) are becoming attractive as few-shot reasoners to solve Natural Language (NL)-related tasks. However, the understanding of their capability to process structured data like tables remains an under-explored area. While tables can be serialized as input for LLMs, there is a lack of comprehensive studies on whether LLMs genuinely comprehend this data. In this paper, we try to understand this by designing a benchmark to evaluate the structural understanding capabilities of LLMs through seven distinct tasks, e.g., cell lookup, row retrieval and size detection. Specially, we perform a series of evaluations on the recent most advanced LLM models, GPT-3.5 and GPT-4 and observe that performance varied with different input choices, including table input format, content order, role prompting, and partition marks. Drawing from the insights gained through the benchmark evaluations, we propose $textit{self-augmentation}$ for effective structural prompting, such as critical value / range identification using internal knowledge of LLMs. When combined with carefully chosen input choices, these structural prompting methods lead to promising improvements in LLM performance on a variety of tabular tasks, e.g., TabFact($uparrow2.31%$), HybridQA($uparrow2.13%$), SQA($uparrow2.72%$), Feverous($uparrow0.84%$), and ToTTo($uparrow5.68%$). We believe that our open source benchmark and proposed prompting methods can serve as a simple yet generic selection for future research. The code and data of this paper will be temporality released at https://anonymous.4open.science/r/StructuredLLM-76F3/README.md and will be replaced with an official one at https://github.com/microsoft/TableProvider later.
Read more7/18/2024
0
On the Robustness of Language Models for Tabular Question Answering
Kushal Raj Bhandari, Sixue Xing, Soham Dan, Jianxi Gao
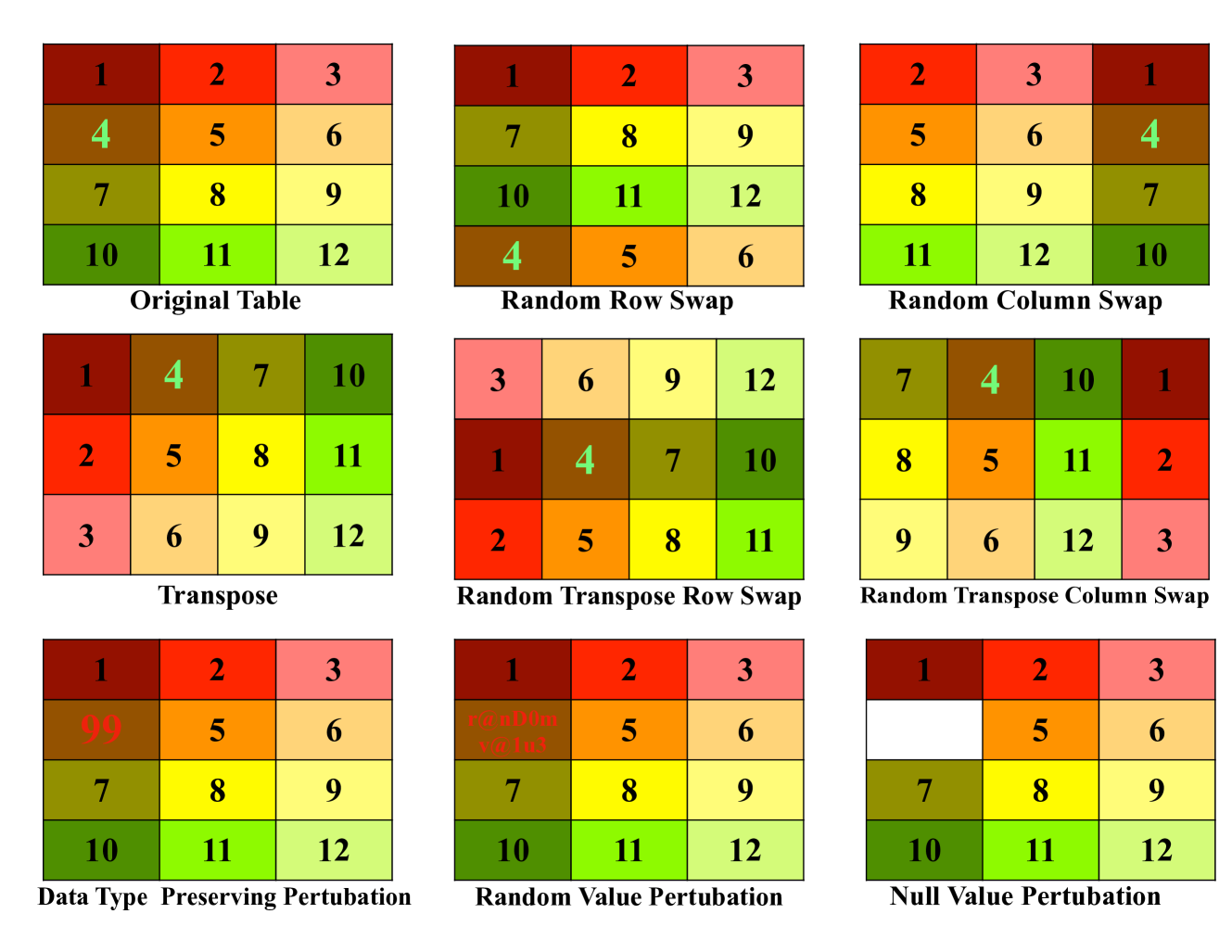
Large Language Models (LLMs), originally shown to ace various text comprehension tasks have also remarkably been shown to tackle table comprehension tasks without specific training. While previous research has explored LLM capabilities with tabular dataset tasks, our study assesses the influence of $textit{in-context learning}$,$ textit{model scale}$, $textit{instruction tuning}$, and $textit{domain biases}$ on Tabular Question Answering (TQA). We evaluate the robustness of LLMs on Wikipedia-based $textbf{WTQ}$ and financial report-based $textbf{TAT-QA}$ TQA datasets, focusing on their ability to robustly interpret tabular data under various augmentations and perturbations. Our findings indicate that instructions significantly enhance performance, with recent models like Llama3 exhibiting greater robustness over earlier versions. However, data contamination and practical reliability issues persist, especially with WTQ. We highlight the need for improved methodologies, including structure-aware self-attention mechanisms and better handling of domain-specific tabular data, to develop more reliable LLMs for table comprehension.
Read more6/19/2024
💬
0
Unleashing the Potential of Large Language Models for Predictive Tabular Tasks in Data Science
Yazheng Yang, Yuqi Wang, Sankalok Sen, Lei Li, Qi Liu
In the domain of data science, the predictive tasks of classification, regression, and imputation of missing values are commonly encountered challenges associated with tabular data. This research endeavors to apply Large Language Models (LLMs) towards addressing these predictive tasks. Despite their proficiency in comprehending natural language, LLMs fall short in dealing with structured tabular data. This limitation stems from their lacking exposure to the intricacies of tabular data during their foundational training. Our research aims to mitigate this gap by compiling a comprehensive corpus of tables annotated with instructions and executing large-scale training of Llama-2 on this enriched dataset. Furthermore, we investigate the practical application of applying the trained model to zero-shot prediction, few-shot prediction, and in-context learning scenarios. Through extensive experiments, our methodology has shown significant improvements over existing benchmarks. These advancements highlight the efficacy of tailoring LLM training to solve table-related problems in data science, thereby establishing a new benchmark in the utilization of LLMs for enhancing tabular intelligence.
Read more4/9/2024