Hierarchical Invariance for Robust and Interpretable Vision Tasks at Larger Scales
2402.15430
0
0
Abstract
Developing robust and interpretable vision systems is a crucial step towards trustworthy artificial intelligence. In this regard, a promising paradigm considers embedding task-required invariant structures, e.g., geometric invariance, in the fundamental image representation. However, such invariant representations typically exhibit limited discriminability, limiting their applications in larger-scale trustworthy vision tasks. For this open problem, we conduct a systematic investigation of hierarchical invariance, exploring this topic from theoretical, practical, and application perspectives. At the theoretical level, we show how to construct over-complete invariants with a Convolutional Neural Networks (CNN)-like hierarchical architecture yet in a fully interpretable manner. The general blueprint, specific definitions, invariant properties, and numerical implementations are provided. At the practical level, we discuss how to customize this theoretical framework into a given task. With the over-completeness, discriminative features w.r.t. the task can be adaptively formed in a Neural Architecture Search (NAS)-like manner. We demonstrate the above arguments with accuracy, invariance, and efficiency results on texture, digit, and parasite classification experiments. Furthermore, at the application level, our representations are explored in real-world forensics tasks on adversarial perturbations and Artificial Intelligence Generated Content (AIGC). Such applications reveal that the proposed strategy not only realizes the theoretically promised invariance, but also exhibits competitive discriminability even in the era of deep learning. For robust and interpretable vision tasks at larger scales, hierarchical invariant representation can be considered as an effective alternative to traditional CNN and invariants.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- Proposes a novel image representation approach called Hierarchical Invariance (HI) that aims to achieve robust and interpretable computer vision models at larger scales.
- HI leverages structural similarities in images to learn hierarchical, scale-invariant representations that are both discriminative and interpretable.
- The research explores the potential of HI to address key challenges in large-scale vision tasks, such as robustness to distribution shifts and the lack of model interpretability.
Plain English Explanation
The provided paper presents a new way of representing images, called Hierarchical Invariance (HI), that aims to make computer vision models more robust and easier to understand, even when dealing with large-scale datasets and tasks.
The core idea behind HI is to take advantage of the natural hierarchical structure and repeating patterns found in many types of images. By learning to recognize these structural similarities at different scales, the model can develop a more robust and interpretable understanding of the visual world.
This is particularly important as computer vision systems are increasingly being deployed in high-stakes applications, where it's crucial that the models can reliably handle a wide range of situations (robustness) and that their decision-making process can be easily explained (interpretability).
The researchers explore how HI can address these challenges, potentially leading to more trustworthy and transparent computer vision systems that can be deployed at larger scales.
Technical Explanation
The paper proposes a novel image representation approach called Hierarchical Invariance (HI) that leverages the structural similarities inherent in many types of images to learn hierarchical, scale-invariant representations.
The key insight is that the visual world often exhibits repeating patterns and hierarchical structure, such as the nested arrangement of parts within larger objects. By explicitly modeling these structural similarities at different scales, the HI approach aims to learn representations that are both discriminative (able to differentiate between different visual concepts) and interpretable (the model's reasoning can be more easily understood).
The HI framework consists of a series of learnable modules that progressively extract and combine features at multiple scales, capturing the hierarchical organization of visual information. This allows the model to build up a rich, structured understanding of the input images that is robust to distribution shifts and other perturbations.
The paper presents experiments demonstrating the effectiveness of HI on a range of computer vision tasks, including image classification, object detection, and 3D reconstruction. The results indicate that HI-based models can achieve strong performance while also providing increased robustness and interpretability compared to standard deep learning approaches.
Critical Analysis
The paper presents a compelling approach to addressing the challenges of robustness and interpretability in large-scale computer vision tasks. By explicitly modeling the hierarchical structure and repeating patterns in images, the HI framework offers a promising direction for developing more trustworthy and transparent vision systems.
One potential limitation of the HI approach is that it may be more computationally intensive than some standard deep learning models, as the hierarchical processing and feature aggregation can add complexity to the architecture. The authors acknowledge this trade-off and suggest avenues for further research to improve the efficiency of HI-based models.
Additionally, while the paper demonstrates the effectiveness of HI on a range of vision tasks, it would be valuable to see further exploration of its generalizability to even more diverse and challenging datasets, as well as its robustness to a wider range of distribution shifts and adversarial attacks.
Overall, the Hierarchical Invariance approach represents an important step forward in the quest for more robust and interpretable computer vision systems. The insights and techniques presented in this paper could have significant implications for the development of reliable and trustworthy AI applications at larger scales.
Conclusion
The paper introduces a novel image representation approach called Hierarchical Invariance (HI) that aims to address key challenges in large-scale computer vision tasks, such as robustness to distribution shifts and the lack of model interpretability.
By explicitly modeling the hierarchical structure and repeating patterns inherent in many types of images, HI-based models can learn representations that are both discriminative and interpretable. The experimental results suggest that this approach can lead to more robust and transparent vision systems, with potential applications in a wide range of high-stakes domains.
While the paper highlights promising directions for further research, the Hierarchical Invariance framework represents an important step forward in the pursuit of trustworthy and reliable AI-powered computer vision solutions.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
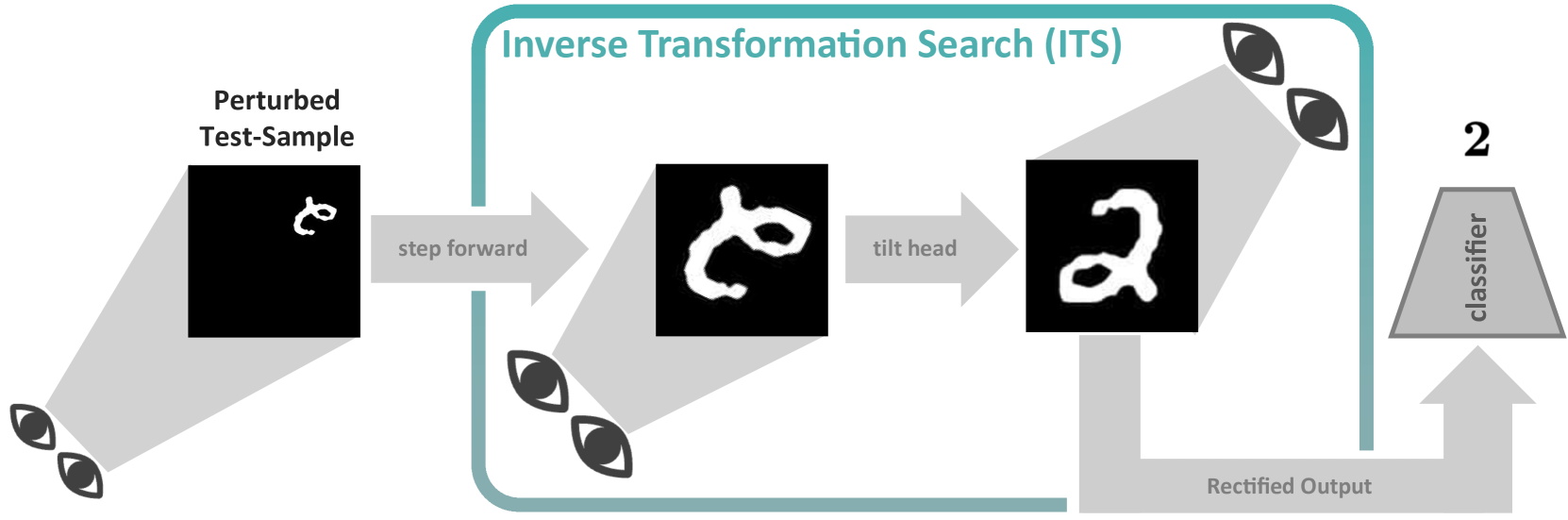
Tilt your Head: Activating the Hidden Spatial-Invariance of Classifiers
Johann Schmidt, Sebastian Stober
0
0
Deep neural networks are applied in more and more areas of everyday life. However, they still lack essential abilities, such as robustly dealing with spatially transformed input signals. Approaches to mitigate this severe robustness issue are limited to two pathways: Either models are implicitly regularised by increased sample variability (data augmentation) or explicitly constrained by hard-coded inductive biases. The limiting factor of the former is the size of the data space, which renders sufficient sample coverage intractable. The latter is limited by the engineering effort required to develop such inductive biases for every possible scenario. Instead, we take inspiration from human behaviour, where percepts are modified by mental or physical actions during inference. We propose a novel technique to emulate such an inference process for neural nets. This is achieved by traversing a sparsified inverse transformation tree during inference using parallel energy-based evaluations. Our proposed inference algorithm, called Inverse Transformation Search (ITS), is model-agnostic and equips the model with zero-shot pseudo-invariance to spatially transformed inputs. We evaluated our method on several benchmark datasets, including a synthesised ImageNet test set. ITS outperforms the utilised baselines on all zero-shot test scenarios.
5/8/2024
🤷
Unsupervised Learning of Group Invariant and Equivariant Representations
Robin Winter, Marco Bertolini, Tuan Le, Frank No'e, Djork-Arn'e Clevert
0
0
Equivariant neural networks, whose hidden features transform according to representations of a group G acting on the data, exhibit training efficiency and an improved generalisation performance. In this work, we extend group invariant and equivariant representation learning to the field of unsupervised deep learning. We propose a general learning strategy based on an encoder-decoder framework in which the latent representation is separated in an invariant term and an equivariant group action component. The key idea is that the network learns to encode and decode data to and from a group-invariant representation by additionally learning to predict the appropriate group action to align input and output pose to solve the reconstruction task. We derive the necessary conditions on the equivariant encoder, and we present a construction valid for any G, both discrete and continuous. We describe explicitly our construction for rotations, translations and permutations. We test the validity and the robustness of our approach in a variety of experiments with diverse data types employing different network architectures.
4/15/2024

Hierarchical Insights: Exploiting Structural Similarities for Reliable 3D Semantic Segmentation
Mariella Dreissig, Florian Piewak, Joschka Boedecker
0
0
Safety-critical applications like autonomous driving call for robust 3D environment perception algorithms which can withstand highly diverse and ambiguous surroundings. The predictive performance of any classification model strongly depends on the underlying dataset and the prior knowledge conveyed by the annotated labels. While the labels provide a basis for the learning process, they usually fail to represent inherent relations between the classes - representations, which are a natural element of the human perception system. We propose a training strategy which enables a 3D LiDAR semantic segmentation model to learn structural relationships between the different classes through abstraction. We achieve this by implicitly modeling those relationships through a learning rule for hierarchical multi-label classification (HMC). With a detailed analysis we show, how this training strategy not only improves the model's confidence calibration, but also preserves additional information for downstream tasks like fusion, prediction and planning.
4/10/2024
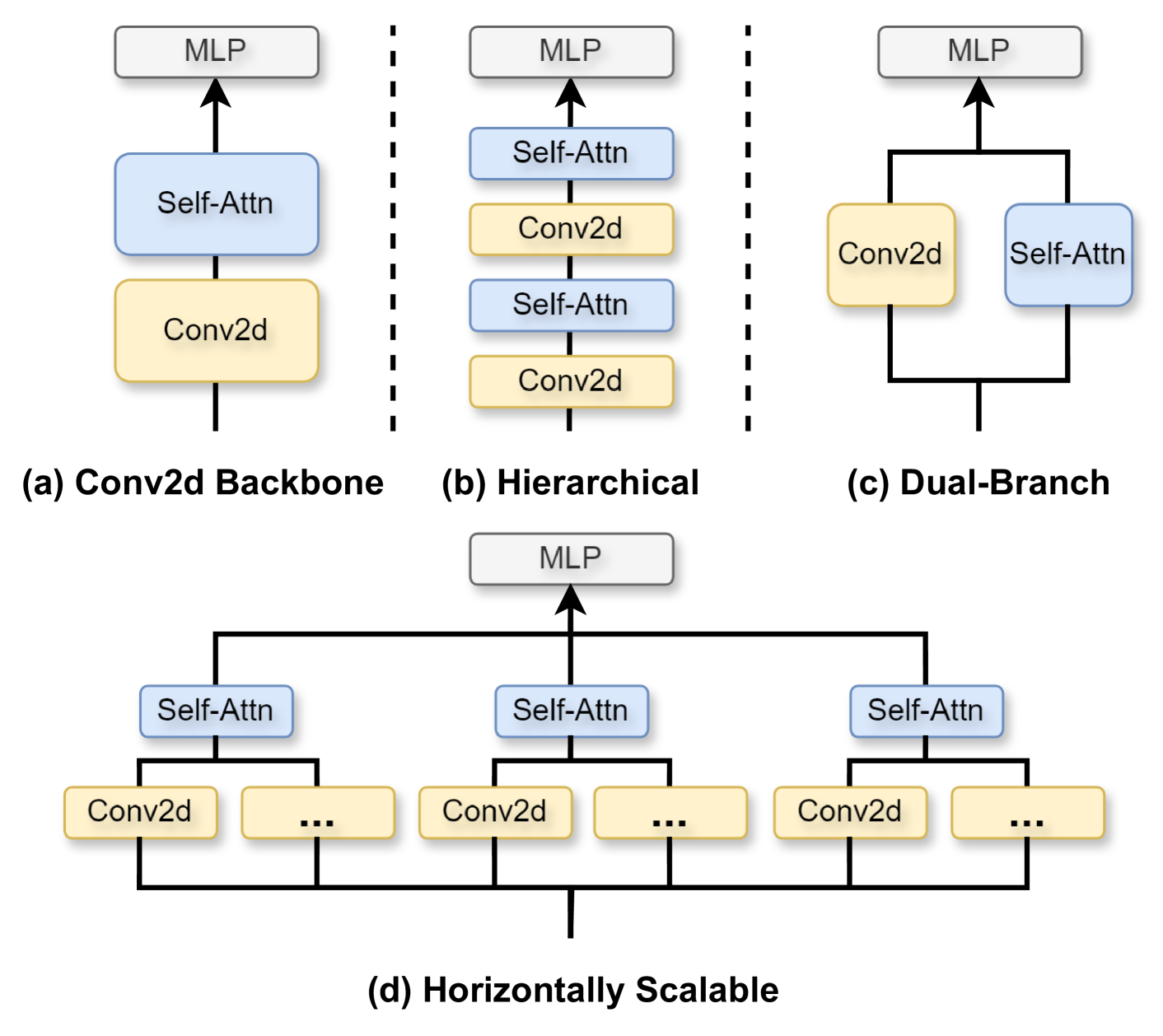
HSViT: Horizontally Scalable Vision Transformer
Chenhao Xu, Chang-Tsun Li, Chee Peng Lim, Douglas Creighton
0
0
While the Vision Transformer (ViT) architecture gains prominence in computer vision and attracts significant attention from multimedia communities, its deficiency in prior knowledge (inductive bias) regarding shift, scale, and rotational invariance necessitates pre-training on large-scale datasets. Furthermore, the growing layers and parameters in both ViT and convolutional neural networks (CNNs) impede their applicability to mobile multimedia services, primarily owing to the constrained computational resources on edge devices. To mitigate the aforementioned challenges, this paper introduces a novel horizontally scalable vision transformer (HSViT). Specifically, a novel image-level feature embedding allows ViT to better leverage the inductive bias inherent in the convolutional layers. Based on this, an innovative horizontally scalable architecture is designed, which reduces the number of layers and parameters of the models while facilitating collaborative training and inference of ViT models across multiple nodes. The experimental results depict that, without pre-training on large-scale datasets, HSViT achieves up to 10% higher top-1 accuracy than state-of-the-art schemes, ascertaining its superior preservation of inductive bias. The code is available at https://github.com/xuchenhao001/HSViT.
4/9/2024