Incremental Joint Learning of Depth, Pose and Implicit Scene Representation on Monocular Camera in Large-scale Scenes
2404.06050
0
0

Abstract
Dense scene reconstruction for photo-realistic view synthesis has various applications, such as VR/AR, autonomous vehicles. However, most existing methods have difficulties in large-scale scenes due to three core challenges: textit{(a) inaccurate depth input.} Accurate depth input is impossible to get in real-world large-scale scenes. textit{(b) inaccurate pose estimation.} Most existing approaches rely on accurate pre-estimated camera poses. textit{(c) insufficient scene representation capability.} A single global radiance field lacks the capacity to effectively scale to large-scale scenes. To this end, we propose an incremental joint learning framework, which can achieve accurate depth, pose estimation, and large-scale scene reconstruction. A vision transformer-based network is adopted as the backbone to enhance performance in scale information estimation. For pose estimation, a feature-metric bundle adjustment (FBA) method is designed for accurate and robust camera tracking in large-scale scenes. In terms of implicit scene representation, we propose an incremental scene representation method to construct the entire large-scale scene as multiple local radiance fields to enhance the scalability of 3D scene representation. Extended experiments have been conducted to demonstrate the effectiveness and accuracy of our method in depth estimation, pose estimation, and large-scale scene reconstruction.
Create account to get full access
Overview
- This paper introduces an incremental learning approach for jointly estimating depth, pose, and an implicit scene representation from monocular camera images in large-scale scenes.
- The proposed method can continuously update the scene representation as the camera moves, without the need for a full scene reconstruction at each step.
- The system leverages an end-to-end neural network architecture to perform these tasks in an integrated manner, enabling efficient and scalable reconstruction of complex environments.
Plain English Explanation
This research presents a new way to help cameras and robots understand their surroundings as they move through large spaces. Rather than trying to create a complete 3D model of the entire scene all at once, the system learns about the environment gradually, building up an internal representation over time.
As the camera moves, it continuously updates its understanding of the depth (how far away objects are), the camera's own position and orientation, and an implicit model of the scene. This implicit model doesn't store a detailed 3D map, but rather learns a compressed representation that captures the key spatial structure.
The key innovation is that all of these capabilities - depth estimation, pose tracking, and scene modeling - are handled by a single neural network that can learn in an integrated, end-to-end fashion. This allows the system to efficiently reconstruct complex environments without having to start from scratch every time the camera moves to a new location. The PLGSLAM paper explores a related approach for progressive scene reconstruction.
Technical Explanation
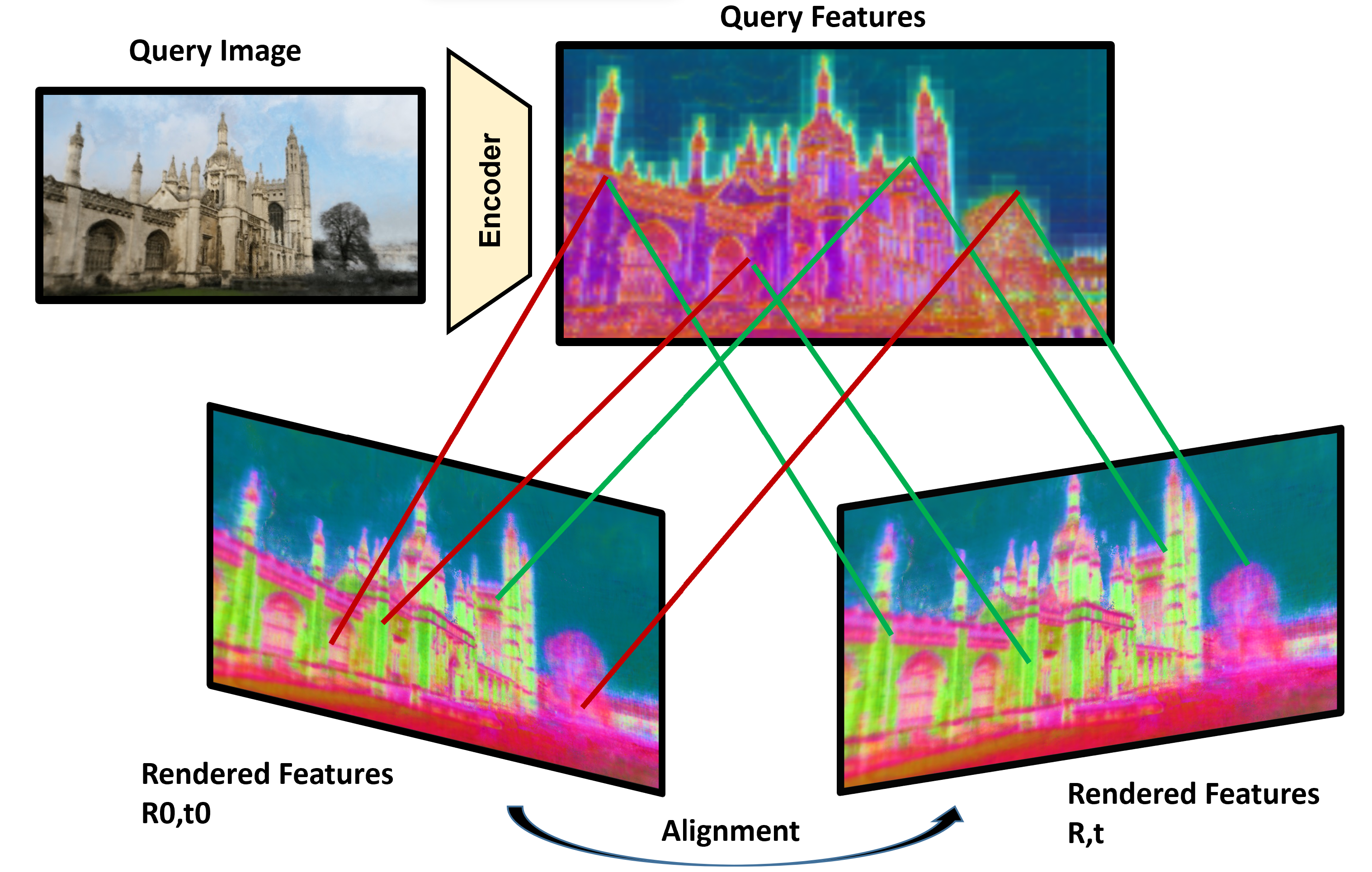
The paper proposes an incremental, joint learning framework for estimating depth, camera pose, and an implicit scene representation from monocular camera inputs. The key components are:
-
Depth Estimation: A depth prediction network takes a single RGB image and outputs a dense depth map. This provides the 3D structure of the observed scene.
-
Pose Estimation: A pose estimation network takes the current RGB image and the previous depth map as input, and predicts the camera's 6D pose (position and orientation) relative to the previous frame. This tracks the camera's motion through the environment.
-
Implicit Scene Representation: An implicit neural scene representation module maintains a continuous, compressed model of the 3D scene. As the camera moves, this representation is incrementally updated to incorporate new observations, without needing to rebuild the entire scene. Techniques like NeRF and PhotoSLAM explore related implicit scene representations.
These three components are jointly trained end-to-end, allowing them to efficiently learn to cooperate and leverage shared information. This avoids the need for complex multi-stage pipelines or separate training of individual modules.
The system is evaluated on large-scale indoor and outdoor scenes, demonstrating its ability to incrementally build accurate 3D models and track camera motion over extended trajectories. Compared to prior work, the proposed approach shows improved performance on depth estimation, pose tracking, and scene representation quality.
Critical Analysis
The paper makes a compelling case for the benefits of an integrated, end-to-end approach to monocular 3D scene understanding. By jointly optimizing depth, pose, and the implicit scene representation, the system can learn efficient and complementary models that outperform more traditional, modular pipelines.
However, the authors acknowledge several limitations and areas for future work. The implicit scene representation, while compact, may struggle to capture fine-grained detail or handle dynamic elements in the environment. Additionally, the system currently assumes a static scene, and would need to be extended to handle moving objects and people, as explored in the You Only Scan Once paper.
Another potential concern is the reliance on monocular input. While this has the advantage of being widely applicable, it also means the system lacks the depth and multi-view advantages of stereo or RGBD cameras. Integrating additional sensor modalities could further improve the accuracy and robustness of the 3D reconstruction.
Overall, this work represents an important step towards more efficient and scalable 3D scene understanding from simple camera inputs. By rethinking the problem in an end-to-end, incremental fashion, the authors have demonstrated a promising direction for future research in this area.
Conclusion
This paper introduces an innovative approach for jointly learning depth estimation, camera pose tracking, and an implicit 3D scene representation from monocular camera inputs. By integrating these capabilities into a single, end-to-end neural network, the system can efficiently build accurate models of large-scale environments as the camera moves, without the need for complete scene reconstruction at each step.
The proposed method shows promising results, outperforming prior work on key metrics. While there are some limitations to be addressed, this research represents an important advancement in the field of 3D scene understanding, with potential applications in areas like robotics, augmented reality, and autonomous navigation. By rethinking the problem from an incremental, jointly-optimized perspective, the authors have opened up new avenues for further exploration and innovation.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🖼️
Scene Coordinate Reconstruction: Posing of Image Collections via Incremental Learning of a Relocalizer
Eric Brachmann, Jamie Wynn, Shuai Chen, Tommaso Cavallari, 'Aron Monszpart, Daniyar Turmukhambetov, Victor Adrian Prisacariu
0
0
We address the task of estimating camera parameters from a set of images depicting a scene. Popular feature-based structure-from-motion (SfM) tools solve this task by incremental reconstruction: they repeat triangulation of sparse 3D points and registration of more camera views to the sparse point cloud. We re-interpret incremental structure-from-motion as an iterated application and refinement of a visual relocalizer, that is, of a method that registers new views to the current state of the reconstruction. This perspective allows us to investigate alternative visual relocalizers that are not rooted in local feature matching. We show that scene coordinate regression, a learning-based relocalization approach, allows us to build implicit, neural scene representations from unposed images. Different from other learning-based reconstruction methods, we do not require pose priors nor sequential inputs, and we optimize efficiently over thousands of images. Our method, ACE0 (ACE Zero), estimates camera poses to an accuracy comparable to feature-based SfM, as demonstrated by novel view synthesis. Project page: https://nianticlabs.github.io/acezero/
4/23/2024
Self-supervised Learning of Neural Implicit Feature Fields for Camera Pose Refinement
Maxime Pietrantoni, Gabriela Csurka, Martin Humenberger, Torsten Sattler
0
0
Visual localization techniques rely upon some underlying scene representation to localize against. These representations can be explicit such as 3D SFM map or implicit, such as a neural network that learns to encode the scene. The former requires sparse feature extractors and matchers to build the scene representation. The latter might lack geometric grounding not capturing the 3D structure of the scene well enough. This paper proposes to jointly learn the scene representation along with a 3D dense feature field and a 2D feature extractor whose outputs are embedded in the same metric space. Through a contrastive framework we align this volumetric field with the image-based extractor and regularize the latter with a ranking loss from learned surface information. We learn the underlying geometry of the scene with an implicit field through volumetric rendering and design our feature field to leverage intermediate geometric information encoded in the implicit field. The resulting features are discriminative and robust to viewpoint change while maintaining rich encoded information. Visual localization is then achieved by aligning the image-based features and the rendered volumetric features. We show the effectiveness of our approach on real-world scenes, demonstrating that our approach outperforms prior and concurrent work on leveraging implicit scene representations for localization.
6/13/2024
🤿
Self-Aligning Depth-regularized Radiance Fields for Asynchronous RGB-D Sequences
Yuxin Huang, Andong Yang, Zirui Wu, Yuantao Chen, Runyi Yang, Zhenxin Zhu, Chao Hou, Hao Zhao, Guyue Zhou
0
0
It has been shown that learning radiance fields with depth rendering and depth supervision can effectively promote the quality and convergence of view synthesis. However, this paradigm requires input RGB-D sequences to be synchronized, hindering its usage in the UAV city modeling scenario. As there exists asynchrony between RGB images and depth images due to high-speed flight, we propose a novel time-pose function, which is an implicit network that maps timestamps to $rm SE(3)$ elements. To simplify the training process, we also design a joint optimization scheme to jointly learn the large-scale depth-regularized radiance fields and the time-pose function. Our algorithm consists of three steps: (1) time-pose function fitting, (2) radiance field bootstrapping, (3) joint pose error compensation and radiance field refinement. In addition, we propose a large synthetic dataset with diverse controlled mismatches and ground truth to evaluate this new problem setting systematically. Through extensive experiments, we demonstrate that our method outperforms baselines without regularization. We also show qualitatively improved results on a real-world asynchronous RGB-D sequence captured by drone. Codes, data, and models will be made publicly available.
4/5/2024

Simultaneous Map and Object Reconstruction
Nathaniel Chodosh, Anish Madan, Deva Ramanan, Simon Lucey
0
0
In this paper, we present a method for dynamic surface reconstruction of large-scale urban scenes from LiDAR. Depth-based reconstructions tend to focus on small-scale objects or large-scale SLAM reconstructions that treat moving objects as outliers. We take a holistic perspective and optimize a compositional model of a dynamic scene that decomposes the world into rigidly moving objects and the background. To achieve this, we take inspiration from recent novel view synthesis methods and pose the reconstruction problem as a global optimization, minimizing the distance between our predicted surface and the input LiDAR scans. We show how this global optimization can be decomposed into registration and surface reconstruction steps, which are handled well by off-the-shelf methods without any re-training. By careful modeling of continuous-time motion, our reconstructions can compensate for the rolling shutter effects of rotating LiDAR sensors. This allows for the first system (to our knowledge) that properly motion compensates LiDAR scans for rigidly-moving objects, complementing widely-used techniques for motion compensation of static scenes. Beyond pursuing dynamic reconstruction as a goal in and of itself, we also show that such a system can be used to auto-label partially annotated sequences and produce ground truth annotation for hard-to-label problems such as depth completion and scene flow.
6/21/2024