Hierarchical Reinforcement Learning for Temporal Abstraction of Listwise Recommendation

0
Sign in to get full access
Overview
- Hierarchical reinforcement learning (HRL) is used to improve listwise recommendation tasks
- The method involves learning higher-level abstract actions that represent sequences of lower-level actions
- This allows the model to take more strategic actions over longer time horizons
Plain English Explanation
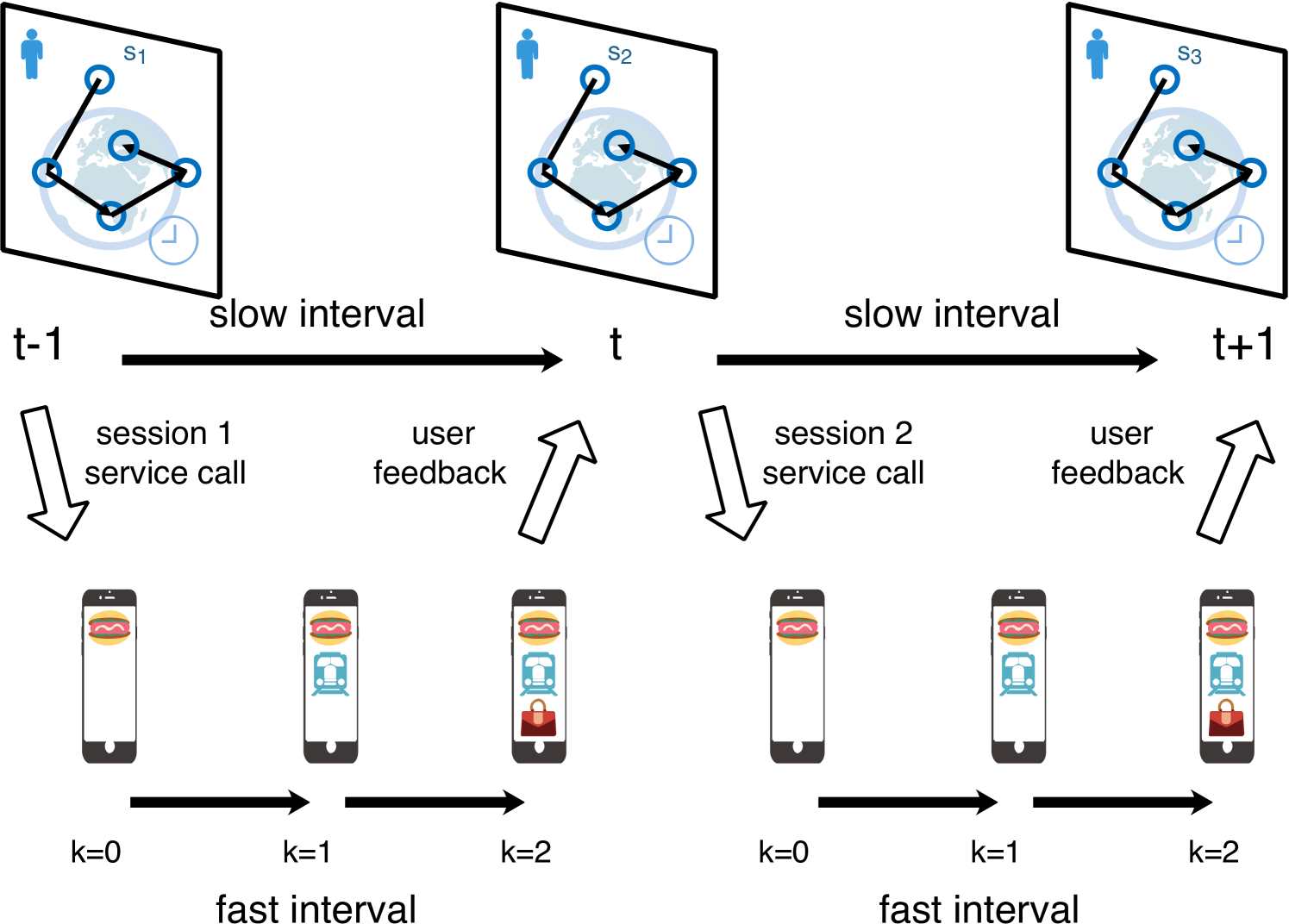
The paper presents a hierarchical reinforcement learning approach for improving listwise recommendation systems. Listwise recommendation aims to rank a set of items (e.g. products, movies) in an optimal order for a user.
The key idea is to learn higher-level "abstract actions" that represent sequences of lower-level actions the model can take. For example, instead of just choosing the next item to recommend, the model can learn to take a high-level action like "recommend a set of complementary products." This allows the model to reason about longer-term strategies rather than just optimizing for the immediate next recommendation.
The hierarchical structure enables the model to operate at different levels of abstraction, making more strategic decisions over longer time horizons. This can lead to better overall recommendations for the user compared to non-hierarchical approaches.
Technical Explanation
The paper proposes a hierarchical reinforcement learning (HRL) framework for listwise recommendation. The key components are:
- Options: Higher-level "abstract actions" that represent sequences of lower-level actions.
- Option Critic: A neural network that learns to select the best option given the current state.
- Intra-Option Policy: A neural network that learns the sequence of lower-level actions to execute a given option.
The model is trained end-to-end using policy gradients. The higher-level Option Critic learns to select the best option, while the lower-level Intra-Option Policy learns to execute that option. This hierarchical structure allows the model to reason about longer-term strategies for recommendation.
The authors evaluate their approach on benchmark datasets for listwise recommendation, showing improved performance compared to non-hierarchical baselines. The hierarchical structure enables the model to uncover more abstract, high-level patterns in user preferences and item relationships.
Critical Analysis
The paper presents a novel application of hierarchical reinforcement learning to the problem of listwise recommendation. The authors demonstrate the benefits of this approach, but also acknowledge some limitations:
- The method requires careful design of the option space and reward function to ensure the model learns meaningful high-level behaviors.
- The training process can be computationally intensive, as the model must learn both the Option Critic and Intra-Option policies.
- The evaluation is limited to standard benchmark datasets, and further research is needed to understand how the approach would generalize to real-world recommendation scenarios.
Additionally, while the paper provides a thorough technical explanation, it would be valuable to see more discussion of potential societal implications, such as how this technology could impact user experience and privacy in recommendation systems.
Conclusion
This paper introduces a hierarchical reinforcement learning approach to improve listwise recommendation systems. By learning higher-level "abstract actions" that represent sequences of lower-level recommendations, the model can reason about longer-term strategies and make more strategic recommendations.
The demonstrated performance improvements over non-hierarchical baselines suggest that this framework could lead to meaningful advancements in recommendation systems, with potential benefits for both users and businesses. However, further research is needed to address the technical and practical limitations identified in the paper.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Hierarchical Reinforcement Learning for Temporal Abstraction of Listwise Recommendation
Luo Ji, Gao Liu, Mingyang Yin, Hongxia Yang, Jingren Zhou
Modern listwise recommendation systems need to consider both long-term user perceptions and short-term interest shifts. Reinforcement learning can be applied on recommendation to study such a problem but is also subject to large search space, sparse user feedback and long interactive latency. Motivated by recent progress in hierarchical reinforcement learning, we propose a novel framework called mccHRL to provide different levels of temporal abstraction on listwise recommendation. Within the hierarchical framework, the high-level agent studies the evolution of user perception, while the low-level agent produces the item selection policy by modeling the process as a sequential decision-making problem. We argue that such framework has a well-defined decomposition of the outra-session context and the intra-session context, which are encoded by the high-level and low-level agents, respectively. To verify this argument, we implement both a simulator-based environment and an industrial dataset-based experiment. Results observe significant performance improvement by our method, compared with several well-known baselines. Data and codes have been made public.
Read more9/12/2024
🛠️
0
A Model-based Multi-Agent Personalized Short-Video Recommender System
Peilun Zhou, Xiaoxiao Xu, Lantao Hu, Han Li, Peng Jiang
Recommender selects and presents top-K items to the user at each online request, and a recommendation session consists of several sequential requests. Formulating a recommendation session as a Markov decision process and solving it by reinforcement learning (RL) framework has attracted increasing attention from both academic and industry communities. In this paper, we propose a RL-based industrial short-video recommender ranking framework, which models and maximizes user watch-time in an environment of user multi-aspect preferences by a collaborative multi-agent formulization. Moreover, our proposed framework adopts a model-based learning approach to alleviate the sample selection bias which is a crucial but intractable problem in industrial recommender system. Extensive offline evaluations and live experiments confirm the effectiveness of our proposed method over alternatives. Our proposed approach has been deployed in our real large-scale short-video sharing platform, successfully serving over hundreds of millions users.
Read more5/6/2024

1
An LLM-based Recommender System Environment
Nathan Corecco, Giorgio Piatti, Luca A. Lanzendorfer, Flint Xiaofeng Fan, Roger Wattenhofer
Reinforcement learning (RL) has gained popularity in the realm of recommender systems due to its ability to optimize long-term rewards and guide users in discovering relevant content. However, the successful implementation of RL in recommender systems is challenging because of several factors, including the limited availability of online data for training on-policy methods. This scarcity requires expensive human interaction for online model training. Furthermore, the development of effective evaluation frameworks that accurately reflect the quality of models remains a fundamental challenge in recommender systems. To address these challenges, we propose a comprehensive framework for synthetic environments that simulate human behavior by harnessing the capabilities of large language models (LLMs). We complement our framework with in-depth ablation studies and demonstrate its effectiveness with experiments on movie and book recommendations. Using LLMs as synthetic users, this work introduces a modular and novel framework to train RL-based recommender systems. The software, including the RL environment, is publicly available on GitHub.
Read more8/21/2024

0
Subgoal-based Hierarchical Reinforcement Learning for Multi-Agent Collaboration
Cheng Xu, Changtian Zhang, Yuchen Shi, Ran Wang, Shihong Duan, Yadong Wan, Xiaotong Zhang
Recent advancements in reinforcement learning have made significant impacts across various domains, yet they often struggle in complex multi-agent environments due to issues like algorithm instability, low sampling efficiency, and the challenges of exploration and dimensionality explosion. Hierarchical reinforcement learning (HRL) offers a structured approach to decompose complex tasks into simpler sub-tasks, which is promising for multi-agent settings. This paper advances the field by introducing a hierarchical architecture that autonomously generates effective subgoals without explicit constraints, enhancing both flexibility and stability in training. We propose a dynamic goal generation strategy that adapts based on environmental changes. This method significantly improves the adaptability and sample efficiency of the learning process. Furthermore, we address the critical issue of credit assignment in multi-agent systems by synergizing our hierarchical architecture with a modified QMIX network, thus improving overall strategy coordination and efficiency. Comparative experiments with mainstream reinforcement learning algorithms demonstrate the superior convergence speed and performance of our approach in both single-agent and multi-agent environments, confirming its effectiveness and flexibility in complex scenarios. Our code is open-sourced at: url{https://github.com/SICC-Group/GMAH}.
Read more8/22/2024