HIERVAR: A Hierarchical Feature Selection Method for Time Series Analysis

0

Sign in to get full access
Overview
- Introduces a new hierarchical feature selection method called HIERVAR for time series analysis
- Aims to identify the most important features at different levels of abstraction
- Utilizes a multi-stage process to efficiently select relevant features
Plain English Explanation
HIERVAR: A Hierarchical Feature Selection Method for Time Series Analysis presents a new approach to identifying the most important features for time series forecasting and analysis. The key idea is to look at features at different levels of abstraction, rather than just considering all features equally.
The method works by first grouping related features into hierarchical clusters. It then evaluates the importance of each cluster, and selects the most relevant ones. This allows the model to focus on the high-level drivers of the time series, while still considering more granular details where appropriate.
By using this hierarchical approach, HIERVAR is able to efficiently identify the critical features for time series tasks, without getting bogged down in irrelevant or redundant information. This can lead to more accurate and interpretable models, which is especially important in applications like finance, healthcare, and other high-stakes domains.
Technical Explanation
The paper frames the feature selection problem for time series as identifying a subset of the most important features that can accurately predict the target variable. HIERVAR approaches this in a multi-stage process:
-
Clustering: The method first groups related features into hierarchical clusters using a similarity measure like correlation. This allows it to capture relationships between features at different levels of abstraction.
-
Importance Evaluation: HIERVAR then evaluates the importance of each cluster by measuring how much it contributes to predicting the target variable. This is done using a variance decomposition technique.
-
Selection: Finally, the most relevant clusters are selected based on their importance scores. Features within these clusters are included in the final feature set.
The key innovation of HIERVAR is this hierarchical approach, which enables it to efficiently identify the critical drivers of the time series while still considering more granular details. The authors demonstrate the effectiveness of their method through experiments on real-world datasets, showing improved performance compared to existing feature selection techniques.
Critical Analysis
The paper provides a thoughtful and well-designed approach to feature selection for time series analysis. The hierarchical structure allows HIERVAR to capture complex relationships between features, which is a key strength compared to simpler feature selection methods.
However, the authors acknowledge some limitations of their work. For example, the clustering and importance evaluation steps can be computationally expensive for very high-dimensional datasets. Additionally, the method may not perform as well when there are nonlinear dependencies between features and the target variable.
It would be interesting to see how HIERVAR compares to more advanced techniques like neural architecture search or other automated feature engineering methods. The authors could also explore ways to further improve the efficiency and scalability of their approach.
Overall, HIERVAR represents a valuable contribution to the field of time series analysis, and the ideas presented in this paper could inspire future research in hierarchical feature selection and representation learning.
Conclusion
HIERVAR introduces a new hierarchical feature selection method that can effectively identify the most important drivers of time series data. By considering features at different levels of abstraction, the technique is able to capture complex relationships while maintaining computational efficiency.
The authors demonstrate the benefits of this approach through experiments on real-world datasets, showing improved performance compared to existing feature selection methods. While the technique has some limitations, it represents an important step forward in the field of time series analysis, with potential applications in finance, healthcare, and beyond.
As the volume and complexity of time series data continue to grow, methods like HIERVAR will become increasingly crucial for extracting meaningful insights and building reliable predictive models. This research highlights the value of hierarchical thinking and the importance of feature engineering in the age of big data.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
HIERVAR: A Hierarchical Feature Selection Method for Time Series Analysis
Alireza Keshavarzian, Shahrokh Valaee
Time series classification stands as a pivotal and intricate challenge across various domains, including finance, healthcare, and industrial systems. In contemporary research, there has been a notable upsurge in exploring feature extraction through random sampling. Unlike deep convolutional networks, these methods sidestep elaborate training procedures, yet they often necessitate generating a surplus of features to comprehensively encapsulate time series nuances. Consequently, some features may lack relevance to labels or exhibit multi-collinearity with others. In this paper, we propose a novel hierarchical feature selection method aided by ANOVA variance analysis to address this challenge. Through meticulous experimentation, we demonstrate that our method substantially reduces features by over 94% while preserving accuracy -- a significant advancement in the field of time series analysis and feature selection.
Read more7/24/2024
0
Hierarchical Classification Auxiliary Network for Time Series Forecasting
Yanru Sun, Zongxia Xie, Dongyue Chen, Emadeldeen Eldele, Qinghua Hu
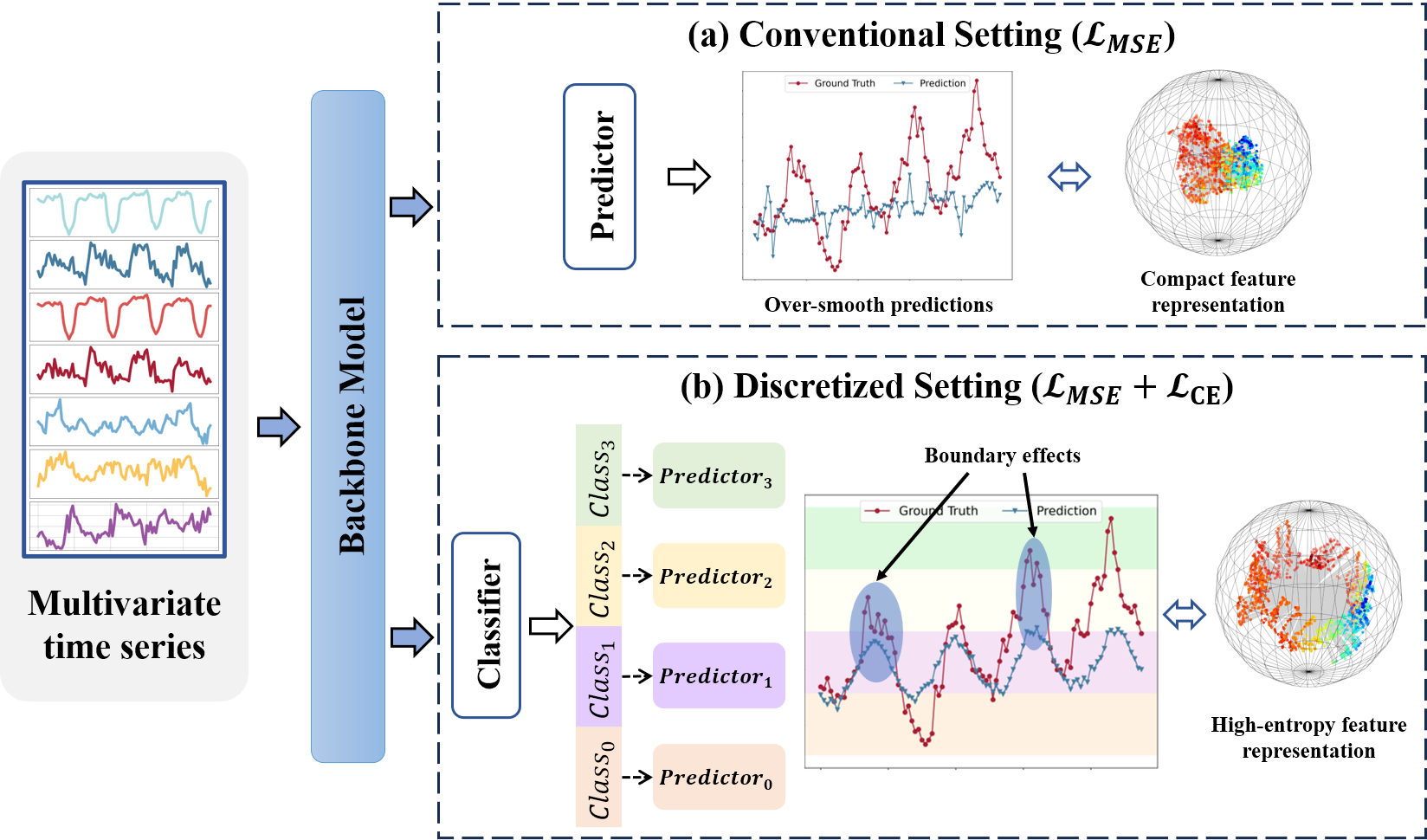
Deep learning has significantly advanced time series forecasting through its powerful capacity to capture sequence relationships. However, training these models with the Mean Square Error (MSE) loss often results in over-smooth predictions, making it challenging to handle the complexity and learn high-entropy features from time series data with high variability and unpredictability. In this work, we introduce a novel approach by tokenizing time series values to train forecasting models via cross-entropy loss, while considering the continuous nature of time series data. Specifically, we propose Hierarchical Classification Auxiliary Network, HCAN, a general model-agnostic component that can be integrated with any forecasting model. HCAN is based on a Hierarchy-Aware Attention module that integrates multi-granularity high-entropy features at different hierarchy levels. At each level, we assign a class label for timesteps to train an Uncertainty-Aware Classifier. This classifier mitigates the over-confidence in softmax loss via evidence theory. We also implement a Hierarchical Consistency Loss to maintain prediction consistency across hierarchy levels. Extensive experiments integrating HCAN with state-of-the-art forecasting models demonstrate substantial improvements over baselines on several real-world datasets. Code is available at:https://github.com/syrGitHub/HCAN.
Read more5/30/2024
👀
0
ANOVA-boosting for Random Fourier Features
Daniel Potts, Laura Weidensager
We propose two algorithms for boosting random Fourier feature models for approximating high-dimensional functions. These methods utilize the classical and generalized analysis of variance (ANOVA) decomposition to learn low-order functions, where there are few interactions between the variables. Our algorithms are able to find an index set of important input variables and variable interactions reliably. Furthermore, we generalize already existing random Fourier feature models to an ANOVA setting, where terms of different order can be used. Our algorithms have the advantage of interpretability, meaning that the influence of every input variable is known in the learned model, even for dependent input variables. We give theoretical as well as numerical results that our algorithms perform well for sensitivity analysis. The ANOVA-boosting step reduces the approximation error of existing methods significantly.
Read more4/5/2024
🏷️
0
Fast and interpretable Support Vector Classification based on the truncated ANOVA decomposition
Kseniya Akhalaya, Franziska Nestler, Daniel Potts
Support Vector Machines (SVMs) are an important tool for performing classification on scattered data, where one usually has to deal with many data points in high-dimensional spaces. We propose solving SVMs in primal form using feature maps based on trigonometric functions or wavelets. In small dimensional settings the Fast Fourier Transform (FFT) and related methods are a powerful tool in order to deal with the considered basis functions. For growing dimensions the classical FFT-based methods become inefficient due to the curse of dimensionality. Therefore, we restrict ourselves to multivariate basis functions, each of which only depends on a small number of dimensions. This is motivated by the well-known sparsity of effects and recent results regarding the reconstruction of functions from scattered data in terms of truncated analysis of variance (ANOVA) decompositions, which makes the resulting model even interpretable in terms of importance of the features as well as their couplings. The usage of small superposition dimensions has the consequence that the computational effort no longer grows exponentially but only polynomially with respect to the dimension. In order to enforce sparsity regarding the basis coefficients, we use the frequently applied $ell_2$-norm and, in addition, $ell_1$-norm regularization. The found classifying function, which is the linear combination of basis functions, and its variance can then be analyzed in terms of the classical ANOVA decomposition of functions. Based on numerical examples we show that we are able to recover the signum of a function that perfectly fits our model assumptions. Furthermore, we perform classification on different artificial and real-world data sets. We obtain better results with $ell_1$-norm regularization, both in terms of accuracy and clarity of interpretability.
Read more9/5/2024