HINT: Learning Complete Human Neural Representations from Limited Viewpoints
2405.19712
0
0

Abstract
No augmented application is possible without animated humanoid avatars. At the same time, generating human replicas from real-world monocular hand-held or robotic sensor setups is challenging due to the limited availability of views. Previous work showed the feasibility of virtual avatars but required the presence of 360 degree views of the targeted subject. To address this issue, we propose HINT, a NeRF-based algorithm able to learn a detailed and complete human model from limited viewing angles. We achieve this by introducing a symmetry prior, regularization constraints, and training cues from large human datasets. In particular, we introduce a sagittal plane symmetry prior to the appearance of the human, directly supervise the density function of the human model using explicit 3D body modeling, and leverage a co-learned human digitization network as additional supervision for the unseen angles. As a result, our method can reconstruct complete humans even from a few viewing angles, increasing performance by more than 15% PSNR compared to previous state-of-the-art algorithms.
Create account to get full access
Overview
- This paper proposes a novel approach called HINT (Holistic INference of human Transports) for learning complete 3D neural representations of humans from limited viewpoints.
- The method aims to infer full 3D human body and appearance from partial observations, enabling applications like 3D avatar creation and manipulation.
- HINT utilizes a transformer-based architecture to efficiently capture the complex correlations between different body parts and appearance attributes.
- The model is trained on a large-scale 3D human dataset and shown to outperform previous state-of-the-art approaches on various benchmarks.
Plain English Explanation
The paper introduces a new technique called HINT that can create detailed 3D digital models of people using only limited information. Typically, creating realistic 3D human avatars requires capturing the person from many angles with specialized equipment. HINT instead can infer the complete 3D shape, pose, and appearance of a person from just a few views.
The key innovation is a deep learning model with a transformer architecture. Transformers are a powerful type of neural network that can efficiently capture the complex relationships between different parts of the human body and appearance attributes. By training this model on a large dataset of 3D human scans, it learns to predict the full 3D representation of a person from partial observations.
This has exciting applications in areas like virtual reality, video games, and animation, where it could enable easier creation of photorealistic digital avatars. It could also aid in 3D human reconstruction from images or videos, which has many use cases in computer vision and robotics.
Technical Explanation
The core of the HINT approach is a transformer-based neural network architecture that can efficiently infer the complete 3D human body shape, pose, and appearance from partial observations. The model takes in a set of 2D images or depth maps showing different views of a person and outputs a full 3D mesh representation.
The transformer component is key, as it allows the model to effectively capture the complex, non-linear relationships between different body parts and visual attributes. This is in contrast to more traditional approaches that often struggle to model these intricate correlations.
The authors train and evaluate HINT on a large dataset of high-quality 3D human scans. Experiments show that it outperforms prior state-of-the-art methods on a range of benchmarks, including 3D reconstruction accuracy and novel view synthesis. The model demonstrates impressive generalization, able to handle a variety of body shapes, clothing styles, and viewing conditions.
Critical Analysis
One notable limitation of the HINT approach is that it relies on having a large, diverse dataset of 3D human scans for training. Acquiring such high-quality 3D data can be challenging and expensive, which could restrict the widespread adoption of the technique.
Additionally, while the transformer architecture enables rich feature representations, it also introduces more model complexity and parameters compared to simpler approaches. This could impact inference speed and memory requirements, potentially limiting real-time applications.
The paper does not explore the model's robustness to occlusions, partial observations, or noisy input data, which would be an important consideration for real-world deployment. Further research is needed to understand the limits of the technique and identify ways to improve its reliability and efficiency.
Conclusion
The HINT method represents a significant advance in the field of 3D human modeling, enabling the creation of highly detailed digital avatars from limited viewpoints. By leveraging transformer-based deep learning, the approach can capture the intricate correlations between human body parts and appearance in a way that outperforms previous state-of-the-art techniques.
This has promising applications in areas like virtual reality, video games, and 3D human reconstruction from images or videos. However, practical deployment will require addressing challenges around dataset acquisition, model complexity, and robustness to real-world conditions.
Overall, the HINT paper demonstrates the power of advanced deep learning architectures in tackling longstanding computer vision and graphics problems. As the field continues to progress, we can expect to see increasingly sophisticated and versatile tools for creating photorealistic 3D human representations.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🧠
Mirror-Aware Neural Humans
Daniel Ajisafe, James Tang, Shih-Yang Su, Bastian Wandt, Helge Rhodin
0
0
Human motion capture either requires multi-camera systems or is unreliable when using single-view input due to depth ambiguities. Meanwhile, mirrors are readily available in urban environments and form an affordable alternative by recording two views with only a single camera. However, the mirror setting poses the additional challenge of handling occlusions of real and mirror image. Going beyond existing mirror approaches for 3D human pose estimation, we utilize mirrors for learning a complete body model, including shape and dense appearance. Our main contributions are extending articulated neural radiance fields to include a notion of a mirror, making it sample-efficient over potential occlusion regions. Together, our contributions realize a consumer-level 3D motion capture system that starts from off-the-shelf 2D poses by automatically calibrating the camera, estimating mirror orientation, and subsequently lifting 2D keypoint detections to 3D skeleton pose that is used to condition the mirror-aware NeRF. We empirically demonstrate the benefit of learning a body model and accounting for occlusion in challenging mirror scenes.
5/17/2024
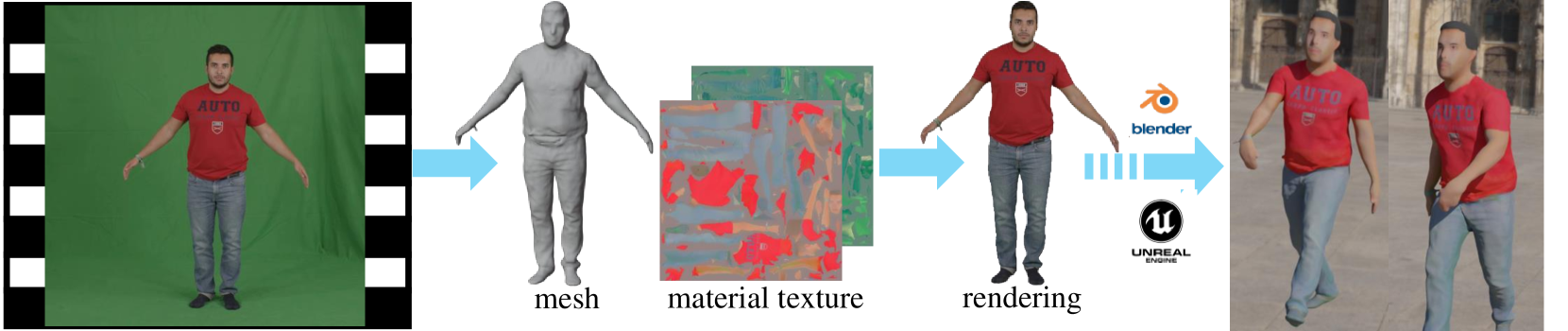
HR Human: Modeling Human Avatars with Triangular Mesh and High-Resolution Textures from Videos
Qifeng Chen, Rengan Xie, Kai Huang, Qi Wang, Wenting Zheng, Rong Li, Yuchi Huo
0
0
Recently, implicit neural representation has been widely used to generate animatable human avatars. However, the materials and geometry of those representations are coupled in the neural network and hard to edit, which hinders their application in traditional graphics engines. We present a framework for acquiring human avatars that are attached with high-resolution physically-based material textures and triangular mesh from monocular video. Our method introduces a novel information fusion strategy to combine the information from the monocular video and synthesize virtual multi-view images to tackle the sparsity of the input view. We reconstruct humans as deformable neural implicit surfaces and extract triangle mesh in a well-behaved pose as the initial mesh of the next stage. In addition, we introduce an approach to correct the bias for the boundary and size of the coarse mesh extracted. Finally, we adapt prior knowledge of the latent diffusion model at super-resolution in multi-view to distill the decomposed texture. Experiments show that our approach outperforms previous representations in terms of high fidelity, and this explicit result supports deployment on common renderers.
5/21/2024
Generalizable Neural Human Renderer
Mana Masuda, Jinhyung Park, Shun Iwase, Rawal Khirodkar, Kris Kitani
0
0
While recent advancements in animatable human rendering have achieved remarkable results, they require test-time optimization for each subject which can be a significant limitation for real-world applications. To address this, we tackle the challenging task of learning a Generalizable Neural Human Renderer (GNH), a novel method for rendering animatable humans from monocular video without any test-time optimization. Our core method focuses on transferring appearance information from the input video to the output image plane by utilizing explicit body priors and multi-view geometry. To render the subject in the intended pose, we utilize a straightforward CNN-based image renderer, foregoing the more common ray-sampling or rasterizing-based rendering modules. Our GNH achieves remarkable generalizable, photorealistic rendering with unseen subjects with a three-stage process. We quantitatively and qualitatively demonstrate that GNH significantly surpasses current state-of-the-art methods, notably achieving a 31.3% improvement in LPIPS.
4/23/2024

Head Pose Estimation and 3D Neural Surface Reconstruction via Monocular Camera in situ for Navigation and Safe Insertion into Natural Openings
Ruijie Tang, Beilei Cui, Hongliang Ren
0
0
As the significance of simulation in medical care and intervention continues to grow, it is anticipated that a simplified and low-cost platform can be set up to execute personalized diagnoses and treatments. 3D Slicer can not only perform medical image analysis and visualization but can also provide surgical navigation and surgical planning functions. In this paper, we have chosen 3D Slicer as our base platform and monocular cameras are used as sensors. Then, We used the neural radiance fields (NeRF) algorithm to complete the 3D model reconstruction of the human head. We compared the accuracy of the NeRF algorithm in generating 3D human head scenes and utilized the MarchingCube algorithm to generate corresponding 3D mesh models. The individual's head pose, obtained through single-camera vision, is transmitted in real-time to the scene created within 3D Slicer. The demonstrations presented in this paper include real-time synchronization of transformations between the human head model in the 3D Slicer scene and the detected head posture. Additionally, we tested a scene where a tool, marked with an ArUco Maker tracked by a single camera, synchronously points to the real-time transformation of the head posture. These demos indicate that our methodology can provide a feasible real-time simulation platform for nasopharyngeal swab collection or intubation.
6/21/2024