Generalizable Neural Human Renderer
2404.14199
0
0
Abstract
While recent advancements in animatable human rendering have achieved remarkable results, they require test-time optimization for each subject which can be a significant limitation for real-world applications. To address this, we tackle the challenging task of learning a Generalizable Neural Human Renderer (GNH), a novel method for rendering animatable humans from monocular video without any test-time optimization. Our core method focuses on transferring appearance information from the input video to the output image plane by utilizing explicit body priors and multi-view geometry. To render the subject in the intended pose, we utilize a straightforward CNN-based image renderer, foregoing the more common ray-sampling or rasterizing-based rendering modules. Our GNH achieves remarkable generalizable, photorealistic rendering with unseen subjects with a three-stage process. We quantitatively and qualitatively demonstrate that GNH significantly surpasses current state-of-the-art methods, notably achieving a 31.3% improvement in LPIPS.
Create account to get full access
Overview
- This paper presents a novel method for rendering realistic and generalizable human models using neural networks.
- The proposed approach, called the Generalizable Neural Human Renderer (GNHR), can generate high-quality human images from diverse input data, including 2D images, 3D scans, and even textual descriptions.
- GNHR leverages large-scale datasets and advances in deep learning to create a flexible and robust system for human rendering, with potential applications in areas like virtual reality, gaming, and digital entertainment.
Plain English Explanation
The Generalizable Neural Human Renderer (GNHR) is a new way to create realistic digital human models using artificial intelligence (AI) and machine learning. Traditional methods for creating digital humans often require specialized equipment, detailed 3D scans, or complex manual modeling. In contrast, GNHR can generate high-quality human images from a variety of input data, including 2D photos, 3D scans, and even text descriptions.
The key innovation of GNHR is its ability to learn "generalizable" features of human appearance and shape, allowing it to create diverse and realistic human models without being limited to a specific individual or data source. This is achieved by training the GNHR system on large-scale datasets of human images and 3D scans, enabling it to capture the essential characteristics of human form and appearance.
By leveraging the power of deep learning, GNHR can produce compelling and lifelike human renderings that can be used in a wide range of applications, such as virtual reality experiences, video games, and digital entertainment productions. This technology has the potential to significantly streamline and democratize the process of creating realistic digital humans, making it more accessible to a broader range of creators and developers.
Technical Explanation
The Generalizable Neural Human Renderer (GNHR) builds upon recent advances in neural rendering and novel view synthesis to create a flexible and efficient system for generating high-quality human images from diverse input data.
At the core of GNHR is a deep neural network architecture that can learn to represent the essential features of human appearance and shape. This is achieved through a multi-stage training process that leverages large-scale datasets of 2D images and 3D scans of humans, as well as textual descriptions of human attributes.
The first stage of the GNHR pipeline involves training a neural network to encode human features in a compact and generalizable latent representation. This latent representation can then be used to condition the generation of realistic human images using a novel neural rendering approach, similar to the GOMA-VAE and PGAHUM models.
To further improve the realism and quality of the generated human images, the GNHR system also incorporates techniques for learning a generative model of human geometry and appearance, as well as methods for handling occlusions and partial information in the input data, inspired by work on 3D human reconstruction from synthetic data.
The authors demonstrate the effectiveness of GNHR through extensive experiments and comparisons with state-of-the-art methods, showing that it can generate high-fidelity human renderings from a variety of input modalities, including 2D images, 3D scans, and textual descriptions. Furthermore, the authors introduce a novel evaluation metric, the Gaussian Generalizable Pixel-wise 3D Gaussian (GPS-G3D), to assess the generalization capabilities of the system.
Critical Analysis
The Generalizable Neural Human Renderer (GNHR) represents a significant advancement in the field of neural rendering and human modeling. By leveraging large-scale datasets and state-of-the-art deep learning techniques, the authors have developed a flexible and robust system that can generate highly realistic human images from diverse input modalities.
One of the key strengths of GNHR is its ability to learn "generalizable" human features, which allows it to create diverse and realistic human models without being limited to a specific individual or dataset. This is a crucial capability for many real-world applications, where the need for diverse and inclusive human representations is becoming increasingly important.
However, the paper also acknowledges several limitations and areas for further research. For example, the authors note that the current GNHR system may struggle with capturing subtle details and nuances of human appearance, particularly in the case of highly expressive or emotive faces. Additionally, the system's performance on more challenging input data, such as low-resolution or occluded images, could be further improved.
Furthermore, while the authors introduce the novel GPS-G3D evaluation metric to assess the generalization capabilities of GNHR, there is room for further research and validation of this metric, as well as the exploration of alternative evaluation approaches that could provide a more comprehensive assessment of the system's performance.
Overall, the Generalizable Neural Human Renderer (GNHR) represents a significant step forward in the field of neural rendering and human modeling, with the potential to unlock new possibilities in virtual reality, gaming, and digital entertainment. As the research in this area continues to evolve, it will be important to address the remaining challenges and limitations in order to further enhance the realism, flexibility, and inclusiveness of digital human representations.
Conclusion
The Generalizable Neural Human Renderer (GNHR) is a novel deep learning-based system that can generate high-quality and diverse human images from a variety of input modalities, including 2D images, 3D scans, and textual descriptions.
By leveraging large-scale datasets and state-of-the-art neural rendering techniques, GNHR is able to learn "generalizable" human features, allowing it to create realistic and inclusive digital human representations that can be used in a wide range of applications, such as virtual reality, gaming, and digital entertainment.
The technical innovations of GNHR, including its multi-stage training process, novel neural rendering approach, and Gaussian Generalizable Pixel-wise 3D Gaussian (GPS-G3D) evaluation metric, demonstrate the potential of this technology to significantly streamline and democratize the creation of realistic digital humans.
While the paper acknowledges several limitations and areas for further research, the Generalizable Neural Human Renderer (GNHR) represents a significant advancement in the field of neural rendering and human modeling, with promising implications for the future of virtual and digital human experiences.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
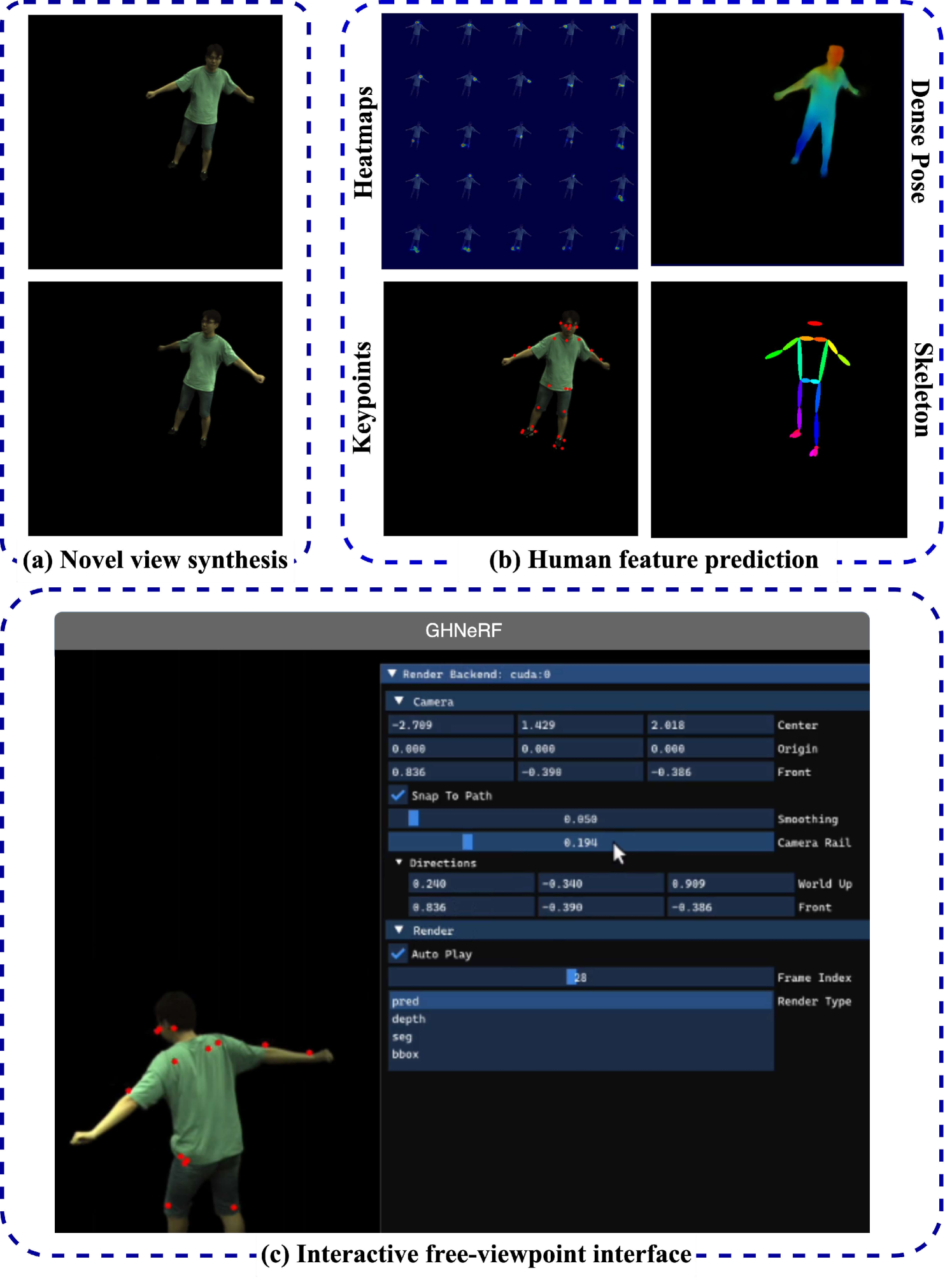
GHNeRF: Learning Generalizable Human Features with Efficient Neural Radiance Fields
Arnab Dey, Di Yang, Rohith Agaram, Antitza Dantcheva, Andrew I. Comport, Srinath Sridhar, Jean Martinet
0
0
Recent advances in Neural Radiance Fields (NeRF) have demonstrated promising results in 3D scene representations, including 3D human representations. However, these representations often lack crucial information on the underlying human pose and structure, which is crucial for AR/VR applications and games. In this paper, we introduce a novel approach, termed GHNeRF, designed to address these limitations by learning 2D/3D joint locations of human subjects with NeRF representation. GHNeRF uses a pre-trained 2D encoder streamlined to extract essential human features from 2D images, which are then incorporated into the NeRF framework in order to encode human biomechanic features. This allows our network to simultaneously learn biomechanic features, such as joint locations, along with human geometry and texture. To assess the effectiveness of our method, we conduct a comprehensive comparison with state-of-the-art human NeRF techniques and joint estimation algorithms. Our results show that GHNeRF can achieve state-of-the-art results in near real-time.
4/10/2024

Animatable and Relightable Gaussians for High-fidelity Human Avatar Modeling
Zhe Li, Yipengjing Sun, Zerong Zheng, Lizhen Wang, Shengping Zhang, Yebin Liu
0
0
Modeling animatable human avatars from RGB videos is a long-standing and challenging problem. Recent works usually adopt MLP-based neural radiance fields (NeRF) to represent 3D humans, but it remains difficult for pure MLPs to regress pose-dependent garment details. To this end, we introduce Animatable Gaussians, a new avatar representation that leverages powerful 2D CNNs and 3D Gaussian splatting to create high-fidelity avatars. To associate 3D Gaussians with the animatable avatar, we learn a parametric template from the input videos, and then parameterize the template on two front & back canonical Gaussian maps where each pixel represents a 3D Gaussian. The learned template is adaptive to the wearing garments for modeling looser clothes like dresses. Such template-guided 2D parameterization enables us to employ a powerful StyleGAN-based CNN to learn the pose-dependent Gaussian maps for modeling detailed dynamic appearances. Furthermore, we introduce a pose projection strategy for better generalization given novel poses. To tackle the realistic relighting of animatable avatars, we introduce physically-based rendering into the avatar representation for decomposing avatar materials and environment illumination. Overall, our method can create lifelike avatars with dynamic, realistic, generalized and relightable appearances. Experiments show that our method outperforms other state-of-the-art approaches.
5/28/2024

HINT: Learning Complete Human Neural Representations from Limited Viewpoints
Alessandro Sanvito, Andrea Ramazzina, Stefanie Walz, Mario Bijelic, Felix Heide
0
0
No augmented application is possible without animated humanoid avatars. At the same time, generating human replicas from real-world monocular hand-held or robotic sensor setups is challenging due to the limited availability of views. Previous work showed the feasibility of virtual avatars but required the presence of 360 degree views of the targeted subject. To address this issue, we propose HINT, a NeRF-based algorithm able to learn a detailed and complete human model from limited viewing angles. We achieve this by introducing a symmetry prior, regularization constraints, and training cues from large human datasets. In particular, we introduce a sagittal plane symmetry prior to the appearance of the human, directly supervise the density function of the human model using explicit 3D body modeling, and leverage a co-learned human digitization network as additional supervision for the unseen angles. As a result, our method can reconstruct complete humans even from a few viewing angles, increasing performance by more than 15% PSNR compared to previous state-of-the-art algorithms.
5/31/2024
🧠
Representing Animatable Avatar via Factorized Neural Fields
Chunjin Song, Zhijie Wu, Bastian Wandt, Leonid Sigal, Helge Rhodin
0
0
For reconstructing high-fidelity human 3D models from monocular videos, it is crucial to maintain consistent large-scale body shapes along with finely matched subtle wrinkles. This paper explores the observation that the per-frame rendering results can be factorized into a pose-independent component and a corresponding pose-dependent equivalent to facilitate frame consistency. Pose adaptive textures can be further improved by restricting frequency bands of these two components. In detail, pose-independent outputs are expected to be low-frequency, while highfrequency information is linked to pose-dependent factors. We achieve a coherent preservation of both coarse body contours across the entire input video and finegrained texture features that are time variant with a dual-branch network with distinct frequency components. The first branch takes coordinates in canonical space as input, while the second branch additionally considers features outputted by the first branch and pose information of each frame. Our network integrates the information predicted by both branches and utilizes volume rendering to generate photo-realistic 3D human images. Through experiments, we demonstrate that our network surpasses the neural radiance fields (NeRF) based state-of-the-art methods in preserving high-frequency details and ensuring consistent body contours.
6/4/2024