HLSFactory: A Framework Empowering High-Level Synthesis Datasets for Machine Learning and Beyond
2405.00820
0
0
Abstract
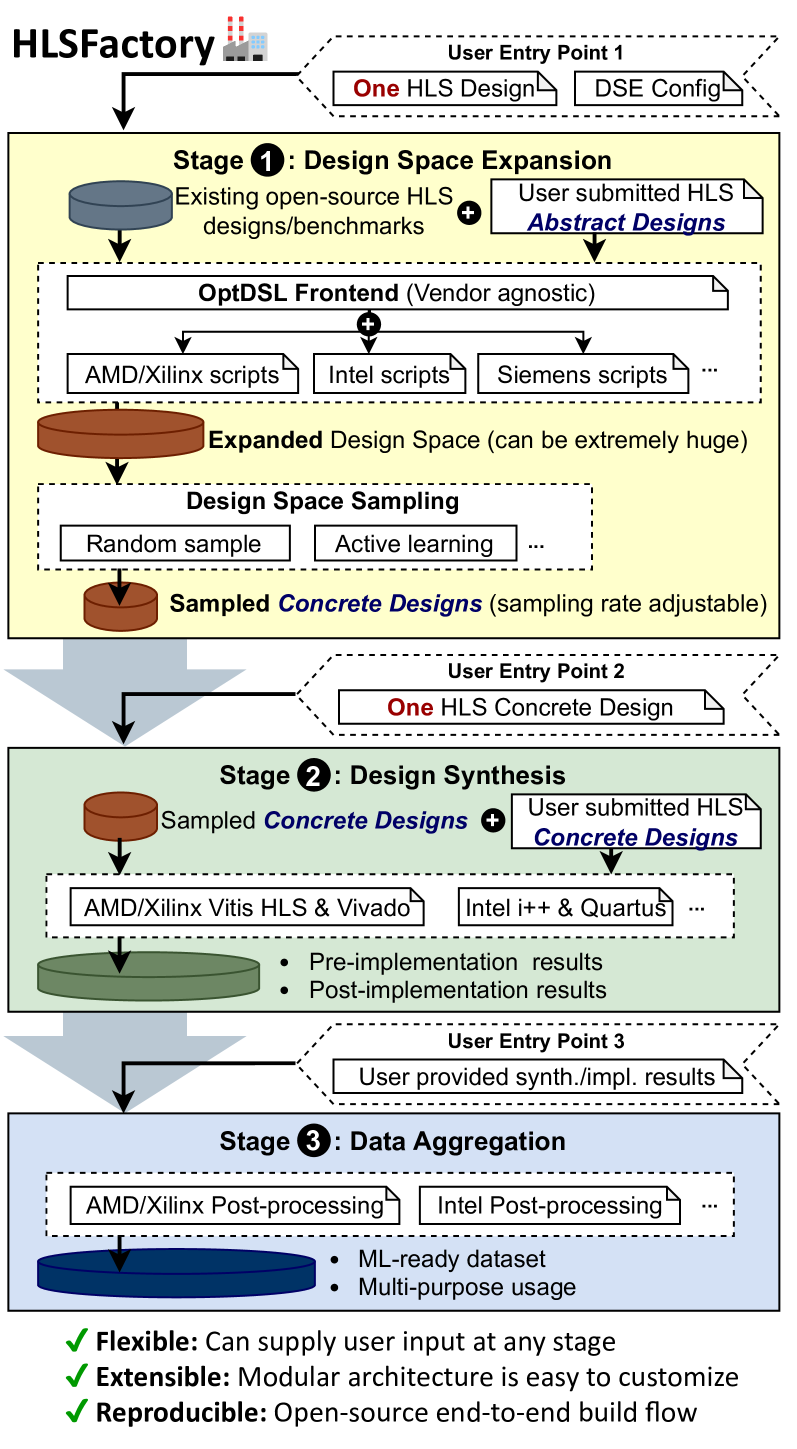
Machine learning (ML) techniques have been applied to high-level synthesis (HLS) flows for quality-of-result (QoR) prediction and design space exploration (DSE). Nevertheless, the scarcity of accessible high-quality HLS datasets and the complexity of building such datasets present challenges. Existing datasets have limitations in terms of benchmark coverage, design space enumeration, vendor extensibility, or lack of reproducible and extensible software for dataset construction. Many works also lack user-friendly ways to add more designs, limiting wider adoption of such datasets. In response to these challenges, we introduce HLSFactory, a comprehensive framework designed to facilitate the curation and generation of high-quality HLS design datasets. HLSFactory has three main stages: 1) a design space expansion stage to elaborate single HLS designs into large design spaces using various optimization directives across multiple vendor tools, 2) a design synthesis stage to execute HLS and FPGA tool flows concurrently across designs, and 3) a data aggregation stage for extracting standardized data into packaged datasets for ML usage. This tripartite architecture ensures broad design space coverage via design space expansion and supports multiple vendor tools. Users can contribute to each stage with their own HLS designs and synthesis results and extend the framework itself with custom frontends and tool flows. We also include an initial set of built-in designs from common HLS benchmarks curated open-source HLS designs. We showcase the versatility and multi-functionality of our framework through six case studies: I) Design space sampling; II) Fine-grained parallelism backend speedup; III) Targeting Intel's HLS flow; IV) Adding new auxiliary designs; V) Integrating published HLS data; VI) HLS tool version regression benchmarking. Code at https://github.com/sharc-lab/HLSFactory.
Create account to get full access
Overview
- The paper presents a framework called HLSFactory that aims to facilitate the creation of high-level synthesis (HLS) datasets for machine learning and other applications.
- HLS is a process that enables the automatic generation of hardware descriptions from high-level programming languages, and HLS datasets are crucial for training machine learning models to perform various tasks related to HLS.
- The HLSFactory framework provides tools and workflows to streamline the generation of diverse and representative HLS datasets, addressing the challenge of data scarcity in this domain.
Plain English Explanation
HLSFactory is a tool that helps create datasets for a process called high-level synthesis (HLS). [Link: https://aimodels.fyi/papers/arxiv/hlstransform-energy-efficient-llama-2-inference-fpgas] HLS allows engineers to automatically generate hardware descriptions from high-level programming languages, like C or C++. These hardware descriptions can then be used to build specialized computer chips called FPGAs or ASICs.
Creating high-quality datasets for training machine learning models to work with HLS is challenging because there isn't a lot of existing data available. HLSFactory aims to make it easier to generate diverse and representative HLS datasets that can be used to train these models. [Link: https://aimodels.fyi/papers/arxiv/evaluation-framework-synthetic-data-generation-models] This is important because as more industries and applications start to use HLS, having good datasets will be crucial for building effective machine learning tools to assist with the HLS process.
Technical Explanation
The HLSFactory framework provides a set of tools and workflows to streamline the generation of HLS datasets. [Link: https://aimodels.fyi/papers/arxiv/skip-benchmark-generating-system-level-high-level] It includes components for automatically synthesizing HLS designs from high-level specifications, varying the design parameters to create diverse samples, and extracting relevant features and metrics from the generated designs.
The framework also incorporates techniques for ensuring the generated datasets are representative of real-world HLS use cases, such as incorporating domain-specific constraints and leveraging transfer learning from existing HLS datasets. [Link: https://aimodels.fyi/papers/arxiv/allo-programming-model-composable-accelerator-design] This helps to produce HLS datasets that are more useful for training machine learning models to assist with various HLS-related tasks, like design space exploration, performance optimization, and hardware-software co-design.
Critical Analysis
The HLSFactory framework addresses an important challenge in the HLS domain by providing a systematic approach to dataset generation. [Link: https://aimodels.fyi/papers/arxiv/design-implementation-analysis-pipeline-heterogeneous-data] However, the paper does not provide a comprehensive evaluation of the quality and diversity of the datasets generated by the framework, nor does it compare the performance of machine learning models trained on HLSFactory datasets versus other HLS datasets.
Additionally, the framework's ability to generate datasets that are truly representative of real-world HLS use cases may be limited by the extent to which the domain-specific constraints and transfer learning techniques can capture the full complexity and variability of HLS design problems. Further research and validation may be needed to address these potential limitations.
Conclusion
The HLSFactory framework represents a significant step forward in addressing the data scarcity challenge for HLS-related machine learning applications. By providing a systematic approach to dataset generation, the framework has the potential to enable the development of more effective and widely applicable machine learning tools for HLS design, optimization, and automation. As the use of HLS continues to grow, the availability of high-quality HLS datasets will become increasingly important, making the HLSFactory framework a valuable contribution to the field.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📊
Skip the Benchmark: Generating System-Level High-Level Synthesis Data using Generative Machine Learning
Yuchao Liao, Tosiron Adegbija, Roman Lysecky, Ravi Tandon
0
0
High-Level Synthesis (HLS) Design Space Exploration (DSE) is a widely accepted approach for efficiently exploring Pareto-optimal and optimal hardware solutions during the HLS process. Several HLS benchmarks and datasets are available for the research community to evaluate their methodologies. Unfortunately, these resources are limited and may not be sufficient for complex, multi-component system-level explorations. Generating new data using existing HLS benchmarks can be cumbersome, given the expertise and time required to effectively generate data for different HLS designs and directives. As a result, synthetic data has been used in prior work to evaluate system-level HLS DSE. However, the fidelity of the synthetic data to real data is often unclear, leading to uncertainty about the quality of system-level HLS DSE. This paper proposes a novel approach, called Vaegan, that employs generative machine learning to generate synthetic data that is robust enough to support complex system-level HLS DSE experiments that would be unattainable with only the currently available data. We explore and adapt a Variational Autoencoder (VAE) and Generative Adversarial Network (GAN) for this task and evaluate our approach using state-of-the-art datasets and metrics. We compare our approach to prior works and show that Vaegan effectively generates synthetic HLS data that closely mirrors the ground truth's distribution.
4/24/2024

Cross-Modality Program Representation Learning for Electronic Design Automation with High-Level Synthesis
Zongyue Qin, Yunsheng Bai, Atefeh Sograbizadeh, Zijian Ding, Ziniu Hu, Yizhou Sun, Jason Cong
0
0
In recent years, domain-specific accelerators (DSAs) have gained popularity for applications such as deep learning and autonomous driving. To facilitate DSA designs, programmers use high-level synthesis (HLS) to compile a high-level description written in C/C++ into a design with low-level hardware description languages that eventually synthesize DSAs on circuits. However, creating a high-quality HLS design still demands significant domain knowledge, particularly in microarchitecture decisions expressed as textit{pragmas}. Thus, it is desirable to automate such decisions with the help of machine learning for predicting the quality of HLS designs, requiring a deeper understanding of the program that consists of original code and pragmas. Naturally, these programs can be considered as sequence data. In addition, these programs can be compiled and converted into a control data flow graph (CDFG). But existing works either fail to leverage both modalities or combine the two in shallow or coarse ways. We propose ProgSG, a model that allows interaction between the source code sequence modality and the graph modality in a deep and fine-grained way. To alleviate the scarcity of labeled designs, a pre-training method is proposed based on a suite of compiler's data flow analysis tasks. Experimental results show that ProgSG reduces the RMSE of design performance predictions by up to $22%$, and identifies designs with an average of $1.10times$ and $1.26times$ (up to $8.17times$ and $13.31times$) performance improvement in design space exploration (DSE) task compared to HARP and AutoDSE, respectively.
6/17/2024

SynthAI: A Multi Agent Generative AI Framework for Automated Modular HLS Design Generation
Seyed Arash Sheikholeslam, Andre Ivanov
0
0
In this paper, we introduce SynthAI, a new method for the automated creation of High-Level Synthesis (HLS) designs. SynthAI integrates ReAct agents, Chain-of-Thought (CoT) prompting, web search technologies, and the Retrieval-Augmented Generation (RAG) framework within a structured decision graph. This innovative approach enables the systematic decomposition of complex hardware design tasks into multiple stages and smaller, manageable modules. As a result, SynthAI produces synthesizable designs that closely adhere to user-specified design objectives and functional requirements. We further validate the capabilities of SynthAI through several case studies, highlighting its proficiency in generating complex, multi-module logic designs from a single initial prompt. The SynthAI code is provided via the following repo: url{https://github.com/sarashs/FPGA_AGI}
6/11/2024

Generative Design through Quality-Diversity Data Synthesis and Language Models
Adam Gaier, James Stoddart, Lorenzo Villaggi, Shyam Sudhakaran
0
0
Two fundamental challenges face generative models in engineering applications: the acquisition of high-performing, diverse datasets, and the adherence to precise constraints in generated designs. We propose a novel approach combining optimization, constraint satisfaction, and language models to tackle these challenges in architectural design. Our method uses Quality-Diversity (QD) to generate a diverse, high-performing dataset. We then fine-tune a language model with this dataset to generate high-level designs. These designs are then refined into detailed, constraint-compliant layouts using the Wave Function Collapse algorithm. Our system demonstrates reliable adherence to textual guidance, enabling the generation of layouts with targeted architectural and performance features. Crucially, our results indicate that data synthesized through the evolutionary search of QD not only improves overall model performance but is essential for the model's ability to closely adhere to textual guidance. This improvement underscores the pivotal role evolutionary computation can play in creating the datasets key to training generative models for design. Web article at https://tilegpt.github.io
5/17/2024