Skip the Benchmark: Generating System-Level High-Level Synthesis Data using Generative Machine Learning
2404.14754
0
0
📊
Abstract
High-Level Synthesis (HLS) Design Space Exploration (DSE) is a widely accepted approach for efficiently exploring Pareto-optimal and optimal hardware solutions during the HLS process. Several HLS benchmarks and datasets are available for the research community to evaluate their methodologies. Unfortunately, these resources are limited and may not be sufficient for complex, multi-component system-level explorations. Generating new data using existing HLS benchmarks can be cumbersome, given the expertise and time required to effectively generate data for different HLS designs and directives. As a result, synthetic data has been used in prior work to evaluate system-level HLS DSE. However, the fidelity of the synthetic data to real data is often unclear, leading to uncertainty about the quality of system-level HLS DSE. This paper proposes a novel approach, called Vaegan, that employs generative machine learning to generate synthetic data that is robust enough to support complex system-level HLS DSE experiments that would be unattainable with only the currently available data. We explore and adapt a Variational Autoencoder (VAE) and Generative Adversarial Network (GAN) for this task and evaluate our approach using state-of-the-art datasets and metrics. We compare our approach to prior works and show that Vaegan effectively generates synthetic HLS data that closely mirrors the ground truth's distribution.
Create account to get full access
Overview
- This paper proposes a novel approach called Vaegan to generate synthetic data that can support complex system-level High-Level Synthesis (HLS) Design Space Exploration (DSE) experiments.
- The authors explore and adapt a Variational Autoencoder (VAE) and Generative Adversarial Network (GAN) to generate synthetic HLS data that closely matches the distribution of real data.
- The goal is to address the limitations of existing HLS benchmarks and datasets, which may not be sufficient for evaluating advanced system-level HLS DSE methodologies.
Plain English Explanation
The paper focuses on a challenge faced by researchers working on High-Level Synthesis (HLS) Design Space Exploration (DSE). HLS DSE is a widely used approach to efficiently explore different hardware solutions during the HLS process. To evaluate their HLS DSE methodologies, researchers often use standardized HLS benchmarks and datasets.
However, these existing resources may not be sufficient for more complex, multi-component system-level explorations. Generating new data using the available HLS benchmarks can be time-consuming and require significant expertise. As a result, prior studies have used synthetic data to evaluate system-level HLS DSE, but the quality and fidelity of this synthetic data to real-world data has been unclear.
To address this issue, the researchers propose a novel approach called Vaegan. Vaegan uses generative machine learning techniques, specifically a combination of Variational Autoencoders (VAEs) and Generative Adversarial Networks (GANs), to generate synthetic HLS data that closely matches the distribution of real-world HLS data. This synthetic data can then be used to support more advanced system-level HLS DSE experiments that would not be feasible with the limited existing data.
The key idea is to leverage the strengths of VAEs and GANs to create a robust synthetic data generation pipeline that can produce high-quality, realistic HLS data. This can benefit researchers working on system-level HLS DSE and evaluating synthetic data generation models.
Technical Explanation
The paper proposes a novel approach called Vaegan, which combines Variational Autoencoders (VAEs) and Generative Adversarial Networks (GANs) to generate synthetic HLS data that closely matches the distribution of real-world HLS data.
The authors first explore the use of VAEs for this task, as VAEs are known for their ability to learn compact latent representations of data and generate new samples that closely resemble the original data. They then adapt the VAE architecture to better capture the unique characteristics of HLS data.
Next, the authors investigate the use of GANs, which are known for their ability to generate high-quality synthetic data that is indistinguishable from real data. They design a GAN-based model specifically for HLS data generation and explore techniques to improve the stability and quality of the generated samples.
Finally, the researchers combine the VAE and GAN approaches into a unified Vaegan framework, which leverages the strengths of both models to generate synthetic HLS data that closely matches the ground truth distribution. They evaluate their approach using state-of-the-art datasets and metrics, and compare the performance to prior works, demonstrating the effectiveness of Vaegan in generating high-fidelity synthetic HLS data.
Critical Analysis
The paper presents a novel and promising approach to addressing the limitations of existing HLS benchmarks and datasets for system-level HLS DSE. The use of generative machine learning techniques, specifically VAEs and GANs, is a well-justified and well-executed approach to generating high-quality synthetic HLS data.
One potential limitation of the study is the reliance on state-of-the-art datasets, which may still not fully capture the complexity of real-world HLS design problems. The authors acknowledge this and suggest that further research is needed to evaluate the Vaegan approach on more diverse and challenging HLS datasets.
Additionally, while the paper demonstrates the effectiveness of Vaegan in generating synthetic HLS data that closely matches the ground truth distribution, it does not provide a comprehensive evaluation of the impact of this synthetic data on the performance of system-level HLS DSE methodologies. Further research is needed to fully understand the practical implications and benefits of using Vaegan-generated data for advanced HLS DSE experiments.
Overall, the Vaegan approach presented in this paper is a significant contribution to the field of HLS DSE and has the potential to enable more robust and comprehensive system-level explorations. The critical analysis highlights the need for continued research and evaluation to fully understand the capabilities and limitations of this approach.
Conclusion
This paper proposes a novel Vaegan approach that leverages generative machine learning techniques, specifically VAEs and GANs, to generate high-quality synthetic HLS data that can support complex system-level HLS Design Space Exploration (DSE) experiments.
The key innovation of Vaegan is its ability to generate synthetic HLS data that closely matches the distribution of real-world HLS data, addressing the limitations of existing HLS benchmarks and datasets. This synthetic data can be used to evaluate advanced HLS DSE methodologies that would otherwise be infeasible with the currently available resources.
The paper presents a thorough technical evaluation of the Vaegan approach, demonstrating its effectiveness in generating synthetic HLS data that closely mirrors the ground truth. This research has the potential to significantly impact the field of HLS DSE, enabling more comprehensive and robust system-level explorations that can lead to the development of more efficient and innovative hardware solutions.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Cross-Modality Program Representation Learning for Electronic Design Automation with High-Level Synthesis
Zongyue Qin, Yunsheng Bai, Atefeh Sohrabizadeh, Zijian Ding, Ziniu Hu, Yizhou Sun, Jason Cong
0
0
In recent years, domain-specific accelerators (DSAs) have gained popularity for applications such as deep learning and autonomous driving. To facilitate DSA designs, programmers use high-level synthesis (HLS) to compile a high-level description written in C/C++ into a design with low-level hardware description languages that eventually synthesize DSAs on circuits. However, creating a high-quality HLS design still demands significant domain knowledge, particularly in microarchitecture decisions expressed as textit{pragmas}. Thus, it is desirable to automate such decisions with the help of machine learning for predicting the quality of HLS designs, requiring a deeper understanding of the program that consists of original code and pragmas. Naturally, these programs can be considered as sequence data. In addition, these programs can be compiled and converted into a control data flow graph (CDFG). But existing works either fail to leverage both modalities or combine the two in shallow or coarse ways. We propose ProgSG, a model that allows interaction between the source code sequence modality and the graph modality in a deep and fine-grained way. To alleviate the scarcity of labeled designs, a pre-training method is proposed based on a suite of compiler's data flow analysis tasks. Experimental results show that ProgSG reduces the RMSE of design performance predictions by up to $22%$, and identifies designs with an average of $1.10times$ and $1.26times$ (up to $8.17times$ and $13.31times$) performance improvement in design space exploration (DSE) task compared to HARP and AutoDSE, respectively.
7/1/2024
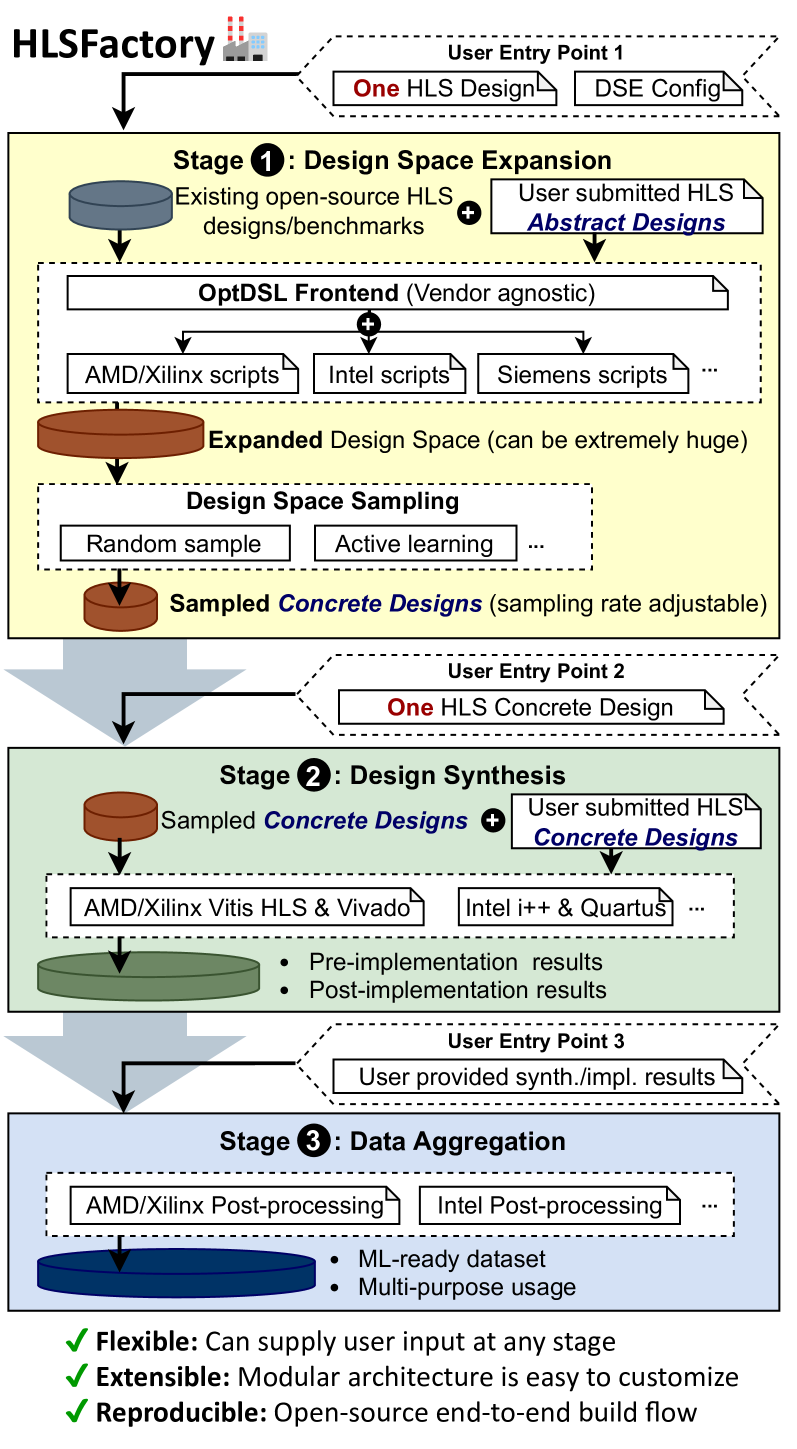
HLSFactory: A Framework Empowering High-Level Synthesis Datasets for Machine Learning and Beyond
Stefan Abi-Karam, Rishov Sarkar, Allison Seigler, Sean Lowe, Zhigang Wei, Hanqiu Chen, Nanditha Rao, Lizy John, Aman Arora, Cong Hao
0
0
Machine learning (ML) techniques have been applied to high-level synthesis (HLS) flows for quality-of-result (QoR) prediction and design space exploration (DSE). Nevertheless, the scarcity of accessible high-quality HLS datasets and the complexity of building such datasets present challenges. Existing datasets have limitations in terms of benchmark coverage, design space enumeration, vendor extensibility, or lack of reproducible and extensible software for dataset construction. Many works also lack user-friendly ways to add more designs, limiting wider adoption of such datasets. In response to these challenges, we introduce HLSFactory, a comprehensive framework designed to facilitate the curation and generation of high-quality HLS design datasets. HLSFactory has three main stages: 1) a design space expansion stage to elaborate single HLS designs into large design spaces using various optimization directives across multiple vendor tools, 2) a design synthesis stage to execute HLS and FPGA tool flows concurrently across designs, and 3) a data aggregation stage for extracting standardized data into packaged datasets for ML usage. This tripartite architecture ensures broad design space coverage via design space expansion and supports multiple vendor tools. Users can contribute to each stage with their own HLS designs and synthesis results and extend the framework itself with custom frontends and tool flows. We also include an initial set of built-in designs from common HLS benchmarks curated open-source HLS designs. We showcase the versatility and multi-functionality of our framework through six case studies: I) Design space sampling; II) Fine-grained parallelism backend speedup; III) Targeting Intel's HLS flow; IV) Adding new auxiliary designs; V) Integrating published HLS data; VI) HLS tool version regression benchmarking. Code at https://github.com/sharc-lab/HLSFactory.
5/20/2024

Expansive Synthesis: Generating Large-Scale Datasets from Minimal Samples
Vahid Jebraeeli, Bo Jiang, Hamid Krim, Derya Cansever
0
0
The challenge of limited availability of data for training in machine learning arises in many applications and the impact on performance and generalization is serious. Traditional data augmentation methods aim to enhance training with a moderately sufficient data set. Generative models like Generative Adversarial Networks (GANs) often face problematic convergence when generating significant and diverse data samples. Diffusion models, though effective, still struggle with high computational cost and long training times. This paper introduces an innovative Expansive Synthesis model that generates large-scale, high-fidelity datasets from minimal samples. The proposed approach exploits expander graph mappings and feature interpolation to synthesize expanded datasets while preserving the intrinsic data distribution and feature structural relationships. The rationale of the model is rooted in the non-linear property of neural networks' latent space and in its capture by a Koopman operator to yield a linear space of features to facilitate the construction of larger and enriched consistent datasets starting with a much smaller dataset. This process is optimized by an autoencoder architecture enhanced with self-attention layers and further refined for distributional consistency by optimal transport. We validate our Expansive Synthesis by training classifiers on the generated datasets and comparing their performance to classifiers trained on larger, original datasets. Experimental results demonstrate that classifiers trained on synthesized data achieve performance metrics on par with those trained on full-scale datasets, showcasing the model's potential to effectively augment training data. This work represents a significant advancement in data generation, offering a robust solution to data scarcity and paving the way for enhanced data availability in machine learning applications.
6/26/2024
👨🏫
A supervised generative optimization approach for tabular data
Shinpei Nakamura-Sakai, Fadi Hamad, Saheed Obitayo, Vamsi K. Potluru
0
0
Synthetic data generation has emerged as a crucial topic for financial institutions, driven by multiple factors, such as privacy protection and data augmentation. Many algorithms have been proposed for synthetic data generation but reaching the consensus on which method we should use for the specific data sets and use cases remains challenging. Moreover, the majority of existing approaches are ``unsupervised'' in the sense that they do not take into account the downstream task. To address these issues, this work presents a novel synthetic data generation framework. The framework integrates a supervised component tailored to the specific downstream task and employs a meta-learning approach to learn the optimal mixture distribution of existing synthetic distributions.
5/13/2024