How JEPA Avoids Noisy Features: The Implicit Bias of Deep Linear Self Distillation Networks

0

Sign in to get full access
Overview
- The paper explores how a machine learning technique called "JEPA" (Joint Embedding Predictive Architecture) can avoid using noisy or irrelevant features when making predictions.
- JEPA is a type of deep learning model that learns representations of data in an unsupervised way, and then uses those representations to make predictions on new data.
- The key insight is that JEPA has an "implicit bias" that causes it to ignore noisy or irrelevant features, leading to better prediction performance.
Plain English Explanation
JEPA is a type of machine learning model that works in two steps. First, it learns a compressed representation of the input data in an unsupervised way, without knowing what the data will be used for. Then, it uses that learned representation to make predictions on new data.
The key insight in this paper is that JEPA has a built-in tendency, or "implicit bias", to ignore noisy or irrelevant features in the data. This is because JEPA is trying to learn a compressed representation that captures the most important information, and irrelevant features just add noise that gets filtered out.
This implicit bias of JEPA is important because in many real-world datasets, there can be a lot of irrelevant or noisy information that can mislead traditional machine learning models. By automatically ignoring this noise, JEPA is able to make more accurate predictions.
Technical Explanation
The paper focuses on a specific type of JEPA model called "Deep Linear Self Distillation" (DLSD), which uses a deep neural network with linear layers to learn the data representation. The authors show that DLSD has an implicit bias towards learning representations that are insensitive to noisy features.
Mathematically, this implicit bias arises from the fact that the objective function of DLSD encourages the model to learn a low-rank representation of the data. This means the model will focus on the most important, low-dimensional patterns in the data and ignore high-dimensional noise.
The authors validate this theoretical insight through experiments on both synthetic and real-world datasets. They show that DLSD outperforms other machine learning models, especially when the input data contains a significant amount of irrelevant features.
Critical Analysis
The paper provides a thorough theoretical and empirical analysis of the implicit bias in JEPA models. However, the authors acknowledge that their analysis is limited to the specific case of deep linear self-distillation networks.
It would be interesting to see if similar implicit biases exist in other variants of JEPA, such as those that use nonlinear transformations or different types of self-supervision. Additionally, the paper does not explore the limitations of this implicit bias - there may be cases where ignoring noisy features is not desirable, and the model's performance could suffer as a result.
Overall, the paper makes an important contribution to understanding the strengths and weaknesses of JEPA models, which could help guide their application in real-world settings.
Conclusion
This paper demonstrates that JEPA models, and specifically Deep Linear Self Distillation networks, have an implicit bias towards learning representations that are insensitive to noisy or irrelevant features in the input data. This bias allows JEPA to make more accurate predictions, especially in the presence of high-dimensional noise.
The theoretical and empirical analyses provided in the paper shed light on an important property of JEPA models, which could inform their use in a variety of applications where robustness to noisy data is crucial. Further research exploring the generalization of this implicit bias to other JEPA architectures could yield additional insights into the strengths and limitations of this promising class of machine learning models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
How JEPA Avoids Noisy Features: The Implicit Bias of Deep Linear Self Distillation Networks
Etai Littwin, Omid Saremi, Madhu Advani, Vimal Thilak, Preetum Nakkiran, Chen Huang, Joshua Susskind
Two competing paradigms exist for self-supervised learning of data representations. Joint Embedding Predictive Architecture (JEPA) is a class of architectures in which semantically similar inputs are encoded into representations that are predictive of each other. A recent successful approach that falls under the JEPA framework is self-distillation, where an online encoder is trained to predict the output of the target encoder, sometimes using a lightweight predictor network. This is contrasted with the Masked AutoEncoder (MAE) paradigm, where an encoder and decoder are trained to reconstruct missing parts of the input in the data space rather, than its latent representation. A common motivation for using the JEPA approach over MAE is that the JEPA objective prioritizes abstract features over fine-grained pixel information (which can be unpredictable and uninformative). In this work, we seek to understand the mechanism behind this empirical observation by analyzing the training dynamics of deep linear models. We uncover a surprising mechanism: in a simplified linear setting where both approaches learn similar representations, JEPAs are biased to learn high-influence features, i.e., features characterized by having high regression coefficients. Our results point to a distinct implicit bias of predicting in latent space that may shed light on its success in practice.
Read more7/8/2024

0
Graph-level Representation Learning with Joint-Embedding Predictive Architectures
Geri Skenderi, Hang Li, Jiliang Tang, Marco Cristani
Joint-Embedding Predictive Architectures (JEPAs) have recently emerged as a novel and powerful technique for self-supervised representation learning. They aim to learn an energy-based model by predicting the latent representation of a target signal y from the latent representation of a context signal x. JEPAs bypass the need for negative and positive samples, traditionally required by contrastive learning while avoiding the overfitting issues associated with generative pretraining. In this paper, we show that graph-level representations can be effectively modeled using this paradigm by proposing a Graph Joint-Embedding Predictive Architecture (Graph-JEPA). In particular, we employ masked modeling and focus on predicting the latent representations of masked subgraphs starting from the latent representation of a context subgraph. To endow the representations with the implicit hierarchy that is often present in graph-level concepts, we devise an alternative prediction objective that consists of predicting the coordinates of the encoded subgraphs on the unit hyperbola in the 2D plane. Through multiple experimental evaluations, we show that Graph-JEPA can learn highly semantic and expressive representations, as shown by the downstream performance in graph classification, regression, and distinguishing non-isomorphic graphs. The code will be made available upon acceptance.
Read more6/26/2024
0
DMT-JEPA: Discriminative Masked Targets for Joint-Embedding Predictive Architecture
Shentong Mo, Sukmin Yun
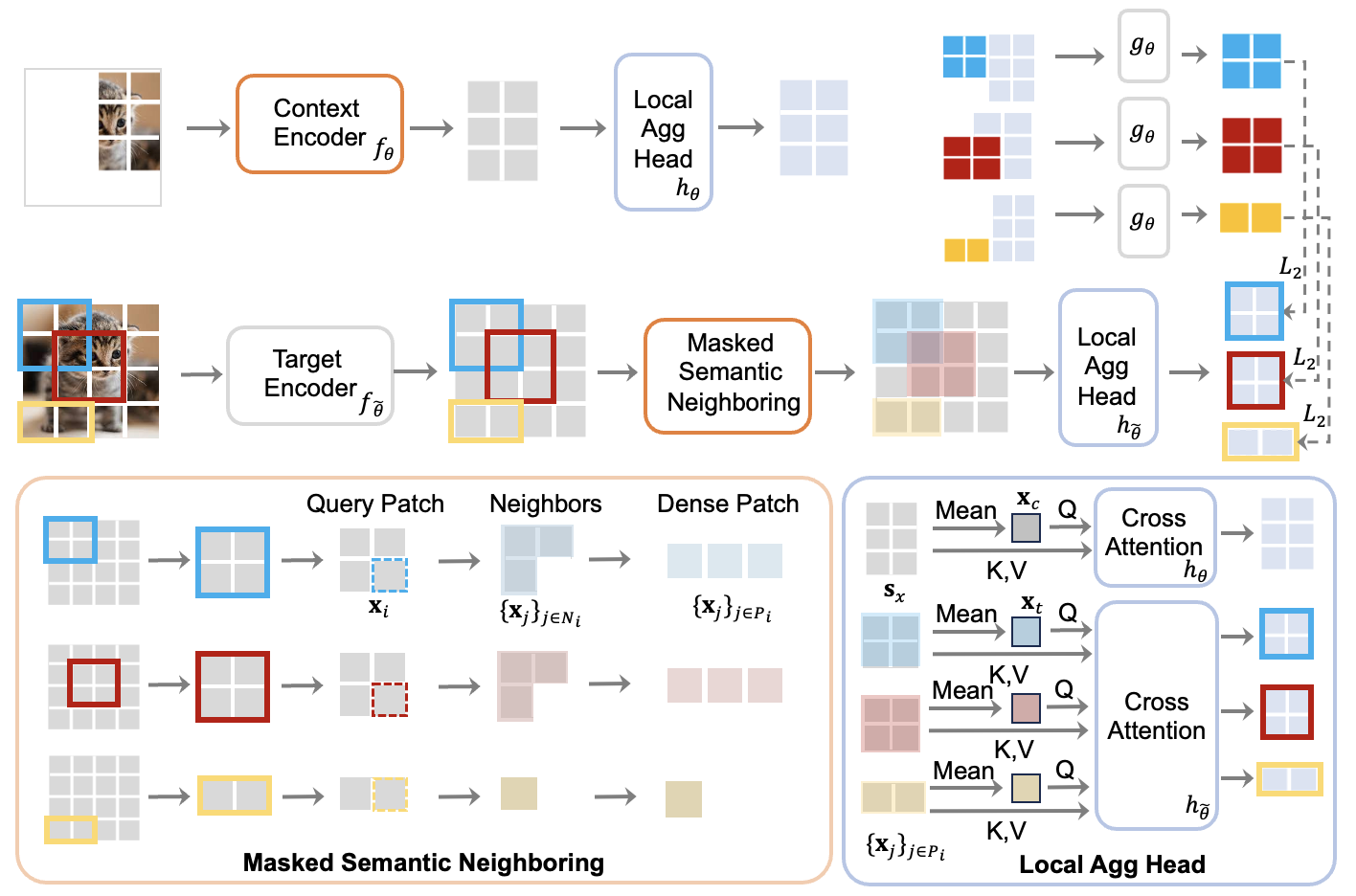
The joint-embedding predictive architecture (JEPA) recently has shown impressive results in extracting visual representations from unlabeled imagery under a masking strategy. However, we reveal its disadvantages, notably its insufficient understanding of local semantics. This deficiency originates from masked modeling in the embedding space, resulting in a reduction of discriminative power and can even lead to the neglect of critical local semantics. To bridge this gap, we introduce DMT-JEPA, a novel masked modeling objective rooted in JEPA, specifically designed to generate discriminative latent targets from neighboring information. Our key idea is simple: we consider a set of semantically similar neighboring patches as a target of a masked patch. To be specific, the proposed DMT-JEPA (a) computes feature similarities between each masked patch and its corresponding neighboring patches to select patches having semantically meaningful relations, and (b) employs lightweight cross-attention heads to aggregate features of neighboring patches as the masked targets. Consequently, DMT-JEPA demonstrates strong discriminative power, offering benefits across a diverse spectrum of downstream tasks. Through extensive experiments, we demonstrate our effectiveness across various visual benchmarks, including ImageNet-1K image classification, ADE20K semantic segmentation, and COCO object detection tasks. Code is available at: url{https://github.com/DMTJEPA/DMTJEPA}.
Read more5/29/2024

0
Investigating Design Choices in Joint-Embedding Predictive Architectures for General Audio Representation Learning
Alain Riou, Stefan Lattner, Gaetan Hadjeres, Geoffroy Peeters
This paper addresses the problem of self-supervised general-purpose audio representation learning. We explore the use of Joint-Embedding Predictive Architectures (JEPA) for this task, which consists of splitting an input mel-spectrogram into two parts (context and target), computing neural representations for each, and training the neural network to predict the target representations from the context representations. We investigate several design choices within this framework and study their influence through extensive experiments by evaluating our models on various audio classification benchmarks, including environmental sounds, speech and music downstream tasks. We focus notably on which part of the input data is used as context or target and show experimentally that it significantly impacts the model's quality. In particular, we notice that some effective design choices in the image domain lead to poor performance on audio, thus highlighting major differences between these two modalities.
Read more5/15/2024