How Transformers Learn Diverse Attention Correlations in Masked Vision Pretraining
2403.02233
0
0
👀
Abstract
Masked reconstruction, which predicts randomly masked patches from unmasked ones, has emerged as an important approach in self-supervised pretraining. However, the theoretical understanding of masked pretraining is rather limited, especially for the foundational architecture of transformers. In this paper, to the best of our knowledge, we provide the first end-to-end theoretical guarantee of learning one-layer transformers in masked reconstruction self-supervised pretraining. On the conceptual side, we posit a mechanism of how transformers trained with masked vision pretraining objectives produce empirically observed local and diverse attention patterns, on data distributions with spatial structures that highlight feature-position correlations. On the technical side, our end-to-end characterization of training dynamics in softmax-attention models simultaneously accounts for input and position embeddings, which is developed based on a careful analysis tracking the interplay between feature-wise and position-wise attention correlations.
Create account to get full access
Overview
- This paper provides the first end-to-end theoretical guarantee of learning one-layer transformers in masked reconstruction self-supervised pretraining.
- The authors posit a mechanism that explains how transformers trained with masked vision pretraining objectives produce empirically observed local and diverse attention patterns on data distributions with spatial structures.
- The paper's technical analysis tracks the interplay between feature-wise and position-wise attention correlations during training.
Plain English Explanation
The paper explores the theoretical foundations of a powerful machine learning technique called masked reconstruction. This approach involves randomly hiding or "masking" parts of the input data and then training a model to predict the missing information.
Masked reconstruction has become an important part of self-supervised pretraining for transformer models, which are a type of neural network architecture widely used in natural language processing and computer vision. However, the theoretical understanding of how masked pretraining works, especially for transformers, has been limited.
In this paper, the authors provide the first rigorous mathematical analysis of how one-layer transformer models learn during masked reconstruction pretraining. They propose an explanation for why these models develop local and diverse attention patterns - that is, how they learn to focus on relevant features in the input data.
The authors' technical analysis tracks how the model's attention mechanism, which determines how it combines different parts of the input, changes during training. This sheds light on the inner workings of transformer-based models and could lead to better interpretability and performance in self-supervised learning.
Technical Explanation
The paper presents an end-to-end theoretical analysis of learning dynamics in one-layer transformer models trained using masked reconstruction self-supervised pretraining. The key contributions are:
-
Conceptual Mechanism: The authors posit a mechanism that explains how transformers trained with masked vision pretraining objectives produce empirically observed local and diverse attention patterns. This is attributed to the model learning to exploit feature-position correlations in the input data.
-
Technical Analysis: The paper provides a detailed mathematical analysis of the training dynamics, tracking the interplay between feature-wise and position-wise attention correlations. This analysis accounts for both the input and position embeddings, which are key components of transformer architectures.
-
Theoretical Guarantees: The work establishes the first end-to-end theoretical guarantee of learning one-layer transformers in the masked reconstruction setting. This provides a rigorous foundation for understanding the behavior of these models during self-supervised pretraining.
The technical analysis involves a careful study of the softmax attention mechanism used in transformers, and how it evolves during the training process. The authors show that the model learns to attend to relevant features and their corresponding positions, leading to the observed local and diverse attention patterns.
Critical Analysis
The paper provides a valuable theoretical contribution to the understanding of transformer-based models, particularly in the context of self-supervised pretraining using masked reconstruction. The authors' analysis sheds light on the inner workings of these models and offers insights that could inform the design of more interpretable and effective self-supervised learning approaches.
That said, the paper focuses solely on one-layer transformer models, which may limit the generalizability of the findings. Extending the analysis to deeper transformer architectures, which are more commonly used in practice, would be an important next step. Additionally, the paper does not explore the implications of the theoretical insights for real-world applications or other types of self-supervised pretraining methods.
Furthermore, the technical nature of the paper may pose a barrier for some readers, and the authors could have provided more intuitive explanations or analogies to make the concepts more accessible to a broader audience. Incorporating such elements could enhance the impact and reach of this research.
Conclusion
This paper presents a significant theoretical advance in understanding the learning dynamics of transformer models during masked reconstruction self-supervised pretraining. By proposing a conceptual mechanism and providing a rigorous mathematical analysis, the authors have laid the groundwork for further research into the interpretability and performance of these powerful models.
While the current analysis is limited to one-layer transformers, the insights gained could inform the development of more advanced self-supervised learning techniques and contribute to the broader goal of making AI systems more transparent and trustworthy. As the field of machine learning continues to evolve, studies like this one will play a crucial role in advancing our understanding of the underlying principles that govern the behavior of these increasingly influential models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
👀
Masked Attention as a Mechanism for Improving Interpretability of Vision Transformers
Cl'ement Grisi, Geert Litjens, Jeroen van der Laak
0
0
Vision Transformers are at the heart of the current surge of interest in foundation models for histopathology. They process images by breaking them into smaller patches following a regular grid, regardless of their content. Yet, not all parts of an image are equally relevant for its understanding. This is particularly true in computational pathology where background is completely non-informative and may introduce artefacts that could mislead predictions. To address this issue, we propose a novel method that explicitly masks background in Vision Transformers' attention mechanism. This ensures tokens corresponding to background patches do not contribute to the final image representation, thereby improving model robustness and interpretability. We validate our approach using prostate cancer grading from whole-slide images as a case study. Our results demonstrate that it achieves comparable performance with plain self-attention while providing more accurate and clinically meaningful attention heatmaps.
4/30/2024

ExpPoint-MAE: Better interpretability and performance for self-supervised point cloud transformers
Ioannis Romanelis, Vlassis Fotis, Konstantinos Moustakas, Adrian Munteanu
0
0
In this paper we delve into the properties of transformers, attained through self-supervision, in the point cloud domain. Specifically, we evaluate the effectiveness of Masked Autoencoding as a pretraining scheme, and explore Momentum Contrast as an alternative. In our study we investigate the impact of data quantity on the learned features, and uncover similarities in the transformer's behavior across domains. Through comprehensive visualiations, we observe that the transformer learns to attend to semantically meaningful regions, indicating that pretraining leads to a better understanding of the underlying geometry. Moreover, we examine the finetuning process and its effect on the learned representations. Based on that, we devise an unfreezing strategy which consistently outperforms our baseline without introducing any other modifications to the model or the training pipeline, and achieve state-of-the-art results in the classification task among transformer models.
4/11/2024
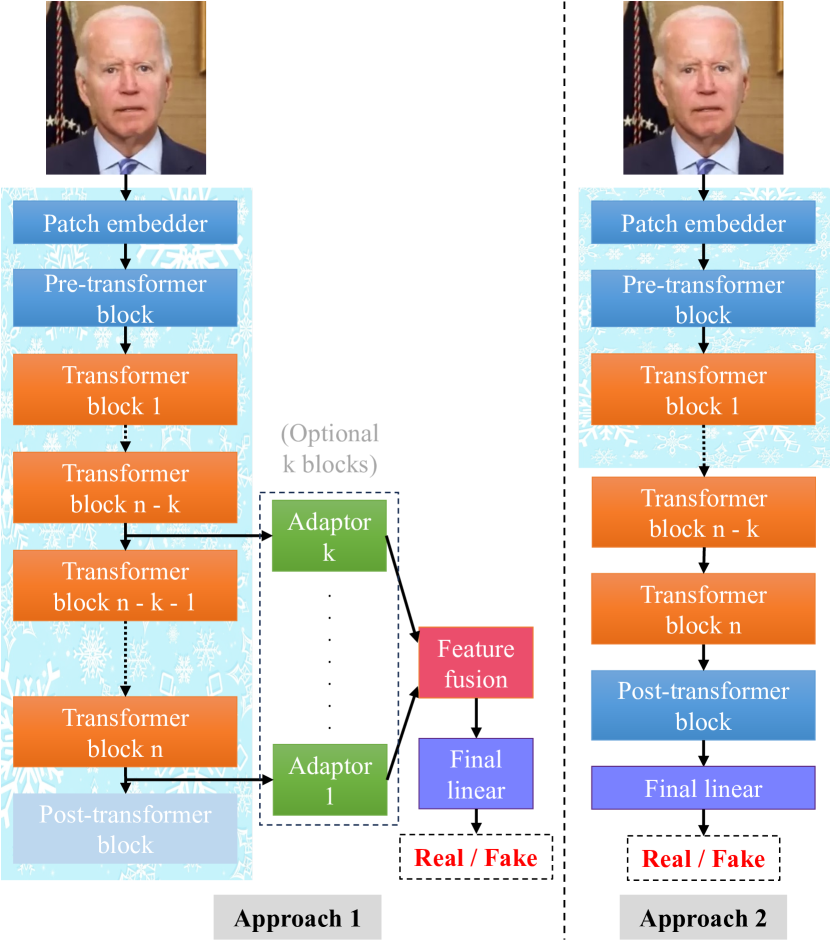
Exploring Self-Supervised Vision Transformers for Deepfake Detection: A Comparative Analysis
Huy H. Nguyen, Junichi Yamagishi, Isao Echizen
0
0
This paper investigates the effectiveness of self-supervised pre-trained transformers compared to supervised pre-trained transformers and conventional neural networks (ConvNets) for detecting various types of deepfakes. We focus on their potential for improved generalization, particularly when training data is limited. Despite the notable success of large vision-language models utilizing transformer architectures in various tasks, including zero-shot and few-shot learning, the deepfake detection community has still shown some reluctance to adopt pre-trained vision transformers (ViTs), especially large ones, as feature extractors. One concern is their perceived excessive capacity, which often demands extensive data, and the resulting suboptimal generalization when training or fine-tuning data is small or less diverse. This contrasts poorly with ConvNets, which have already established themselves as robust feature extractors. Additionally, training and optimizing transformers from scratch requires significant computational resources, making this accessible primarily to large companies and hindering broader investigation within the academic community. Recent advancements in using self-supervised learning (SSL) in transformers, such as DINO and its derivatives, have showcased significant adaptability across diverse vision tasks and possess explicit semantic segmentation capabilities. By leveraging DINO for deepfake detection with modest training data and implementing partial fine-tuning, we observe comparable adaptability to the task and the natural explainability of the detection result via the attention mechanism. Moreover, partial fine-tuning of transformers for deepfake detection offers a more resource-efficient alternative, requiring significantly fewer computational resources.
5/2/2024
🧠
Efficient Vision-Language Pre-training by Cluster Masking
Zihao Wei, Zixuan Pan, Andrew Owens
0
0
We propose a simple strategy for masking image patches during visual-language contrastive learning that improves the quality of the learned representations and the training speed. During each iteration of training, we randomly mask clusters of visually similar image patches, as measured by their raw pixel intensities. This provides an extra learning signal, beyond the contrastive training itself, since it forces a model to predict words for masked visual structures solely from context. It also speeds up training by reducing the amount of data used in each image. We evaluate the effectiveness of our model by pre-training on a number of benchmarks, finding that it outperforms other masking strategies, such as FLIP, on the quality of the learned representation.
5/15/2024