Efficient Vision-Language Pre-training by Cluster Masking
2405.08815
0
0
🧠
Abstract
We propose a simple strategy for masking image patches during visual-language contrastive learning that improves the quality of the learned representations and the training speed. During each iteration of training, we randomly mask clusters of visually similar image patches, as measured by their raw pixel intensities. This provides an extra learning signal, beyond the contrastive training itself, since it forces a model to predict words for masked visual structures solely from context. It also speeds up training by reducing the amount of data used in each image. We evaluate the effectiveness of our model by pre-training on a number of benchmarks, finding that it outperforms other masking strategies, such as FLIP, on the quality of the learned representation.
Create account to get full access
Overview
- The paper proposes a simple strategy for masking image patches during visual-language contrastive learning to improve the quality of the learned representations and the training speed.
- During training, the method randomly masks clusters of visually similar image patches, as measured by their raw pixel intensities.
- This provides an extra learning signal, forcing the model to predict words for masked visual structures solely from context, and also speeds up training by reducing the amount of data used in each image.
- The researchers evaluate the effectiveness of their model by pre-training on a number of benchmarks, finding it outperforms other masking strategies such as FLIP on the quality of the learned representation.
Plain English Explanation
The researchers have developed a new way to train visual-language models like CLIP that can understand both images and text. During training, their method randomly obscures or "masks" certain parts of the images, but in a clever way.
Instead of just hiding random patches, the method identifies clusters of visually similar patches and masks those together. This forces the model to learn how to predict the missing parts of the image based on the surrounding context. It's like covering up some of the pieces in a jigsaw puzzle and challenging the model to figure out what should be there.
This extra learning signal, combined with the fact that the model has to process less data in each image, helps the model learn better representations of visual concepts. The researchers found that this approach outperforms other masking strategies, leading to more capable visual-language models that can understand images and text more effectively.
Technical Explanation
The key technical innovation in this paper is the use of a novel masking strategy during visual-language contrastive learning. Rather than randomly masking individual image patches, the researchers propose clustering visually similar patches and masking them together.
This is done by first extracting image patches and measuring their similarity based on raw pixel intensities. Patches that are visually similar are then grouped into clusters, and during each training iteration, a random subset of these clusters are masked. This forces the model to predict the masked visual structures solely from the surrounding context, providing an extra learning signal beyond the contrastive training itself.
The researchers hypothesize that this approach leads to better learned representations, as the model has to reason more holistically about the visual structures in the image. Additionally, by reducing the amount of data processed in each image, the masking strategy can speed up training.
To evaluate the effectiveness of their approach, the researchers pre-train their model on several benchmarks and compare it to other masking strategies, such as FLIP. They find that their method outperforms these baselines in terms of the quality of the learned representations, as measured by downstream task performance.
Critical Analysis
The researchers provide a compelling technical approach and strong empirical results, but there are a few potential limitations and areas for further exploration:
-
The method relies on a relatively simple pixel-based similarity measure to cluster patches, which may not fully capture the semantic or functional relationships between visual structures. More sophisticated clustering algorithms or learned representations could potentially further improve the masking strategy.
-
The paper does not explore the effect of the masking strategy on the model's ability to generalize to novel images or tasks. It would be valuable to assess how well the learned representations transfer to different domains or applications, especially those that may require a more holistic understanding of visual scenes.
-
The researchers focus on pre-training and do not delve into the specifics of fine-tuning or downstream task performance. Understanding how the masking strategy interacts with different fine-tuning approaches could provide additional insights.
-
While the paper demonstrates the effectiveness of the masking strategy, it does not provide a deep analysis of the underlying mechanisms or reasons for its success. Further research into the cognitive and computational principles behind this approach could lead to even more effective training techniques for visual-language models.
Overall, the paper presents a simple yet powerful masking strategy that can improve the performance of visual-language models, and the findings are a valuable contribution to the field of contrastive learning.
Conclusion
The proposed masking strategy for visual-language contrastive learning offers a simple and effective way to improve the quality of the learned representations and the training speed. By clustering visually similar image patches and selectively masking them, the method provides an extra learning signal that forces the model to reason more holistically about visual structures.
The researchers' findings demonstrate the effectiveness of this approach, with the masked model outperforming other masking techniques on a range of benchmarks. While there are some potential limitations and areas for further exploration, this work represents an important step forward in developing more capable and efficient visual-language models that can better understand the world around us.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
👀
How Transformers Learn Diverse Attention Correlations in Masked Vision Pretraining
Yu Huang, Zixin Wen, Yuejie Chi, Yingbin Liang
0
0
Masked reconstruction, which predicts randomly masked patches from unmasked ones, has emerged as an important approach in self-supervised pretraining. However, the theoretical understanding of masked pretraining is rather limited, especially for the foundational architecture of transformers. In this paper, to the best of our knowledge, we provide the first end-to-end theoretical guarantee of learning one-layer transformers in masked reconstruction self-supervised pretraining. On the conceptual side, we posit a mechanism of how transformers trained with masked vision pretraining objectives produce empirically observed local and diverse attention patterns, on data distributions with spatial structures that highlight feature-position correlations. On the technical side, our end-to-end characterization of training dynamics in softmax-attention models simultaneously accounts for input and position embeddings, which is developed based on a careful analysis tracking the interplay between feature-wise and position-wise attention correlations.
6/6/2024

Masking Improves Contrastive Self-Supervised Learning for ConvNets, and Saliency Tells You Where
Zhi-Yi Chin, Chieh-Ming Jiang, Ching-Chun Huang, Pin-Yu Chen, Wei-Chen Chiu
0
0
While image data starts to enjoy the simple-but-effective self-supervised learning scheme built upon masking and self-reconstruction objective thanks to the introduction of tokenization procedure and vision transformer backbone, convolutional neural networks as another important and widely-adopted architecture for image data, though having contrastive-learning techniques to drive the self-supervised learning, still face the difficulty of leveraging such straightforward and general masking operation to benefit their learning process significantly. In this work, we aim to alleviate the burden of including masking operation into the contrastive-learning framework for convolutional neural networks as an extra augmentation method. In addition to the additive but unwanted edges (between masked and unmasked regions) as well as other adverse effects caused by the masking operations for ConvNets, which have been discussed by prior works, we particularly identify the potential problem where for one view in a contrastive sample-pair the randomly-sampled masking regions could be overly concentrated on important/salient objects thus resulting in misleading contrastiveness to the other view. To this end, we propose to explicitly take the saliency constraint into consideration in which the masked regions are more evenly distributed among the foreground and background for realizing the masking-based augmentation. Moreover, we introduce hard negative samples by masking larger regions of salient patches in an input image. Extensive experiments conducted on various datasets, contrastive learning mechanisms, and downstream tasks well verify the efficacy as well as the superior performance of our proposed method with respect to several state-of-the-art baselines.
6/11/2024
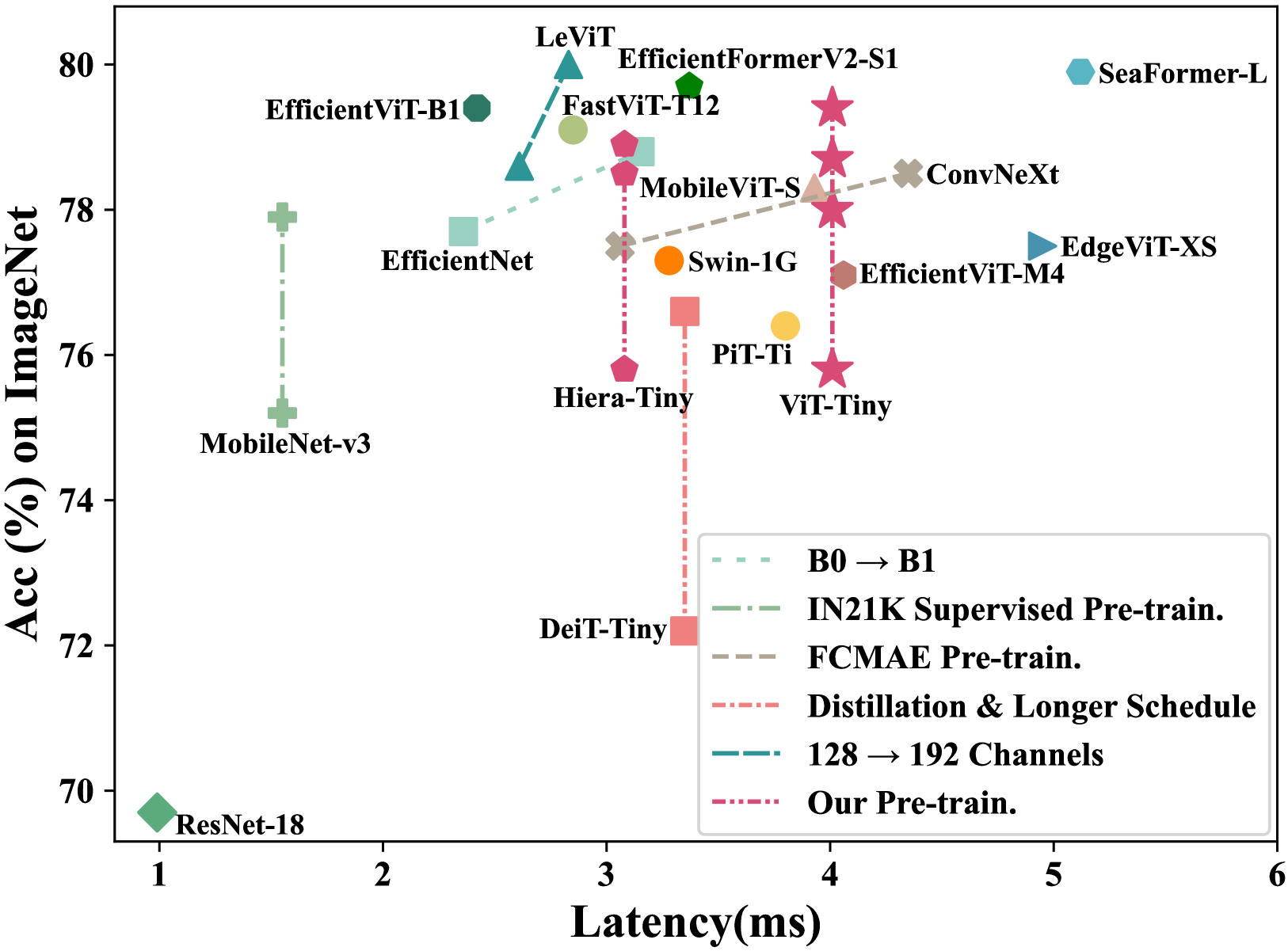
Observation, Analysis, and Solution: Exploring Strong Lightweight Vision Transformers via Masked Image Modeling Pre-Training
Jin Gao, Shubo Lin, Shaoru Wang, Yutong Kou, Zeming Li, Liang Li, Congxuan Zhang, Xiaoqin Zhang, Yizheng Wang, Weiming Hu
0
0
Masked image modeling (MIM) pre-training for large-scale vision transformers (ViTs) has enabled promising downstream performance on top of the learned self-supervised ViT features. In this paper, we question if the textit{extremely simple} lightweight ViTs' fine-tuning performance can also benefit from this pre-training paradigm, which is considerably less studied yet in contrast to the well-established lightweight architecture design methodology. We use an observation-analysis-solution flow for our study. We first systematically observe different behaviors among the evaluated pre-training methods with respect to the downstream fine-tuning data scales. Furthermore, we analyze the layer representation similarities and attention maps across the obtained models, which clearly show the inferior learning of MIM pre-training on higher layers, leading to unsatisfactory transfer performance on data-insufficient downstream tasks. This finding is naturally a guide to designing our distillation strategies during pre-training to solve the above deterioration problem. Extensive experiments have demonstrated the effectiveness of our approach. Our pre-training with distillation on pure lightweight ViTs with vanilla/hierarchical design ($5.7M$/$6.5M$) can achieve $79.4%$/$78.9%$ top-1 accuracy on ImageNet-1K. It also enables SOTA performance on the ADE20K segmentation task ($42.8%$ mIoU) and LaSOT tracking task ($66.1%$ AUC) in the lightweight regime. The latter even surpasses all the current SOTA lightweight CPU-realtime trackers.
5/28/2024
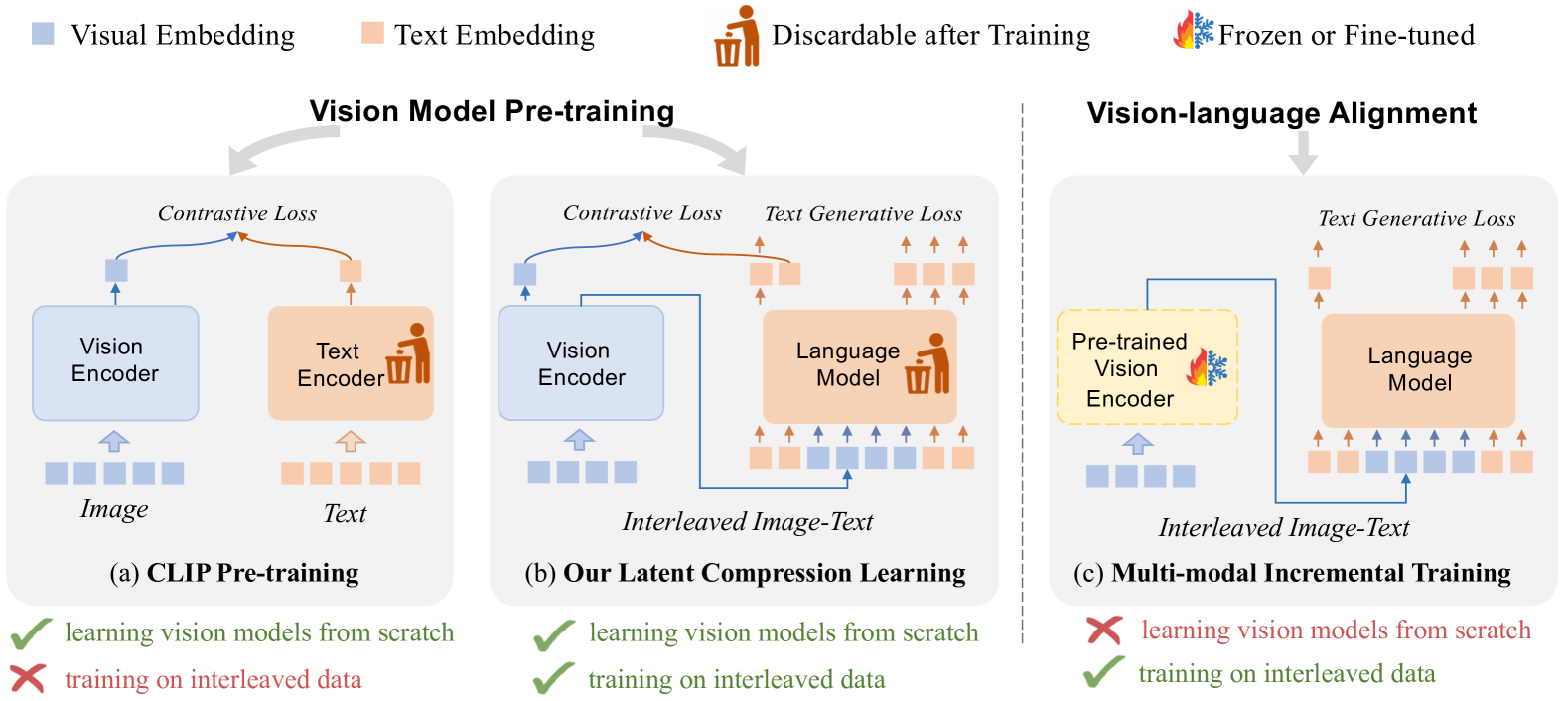
Vision Model Pre-training on Interleaved Image-Text Data via Latent Compression Learning
Chenyu Yang, Xizhou Zhu, Jinguo Zhu, Weijie Su, Junjie Wang, Xuan Dong, Wenhai Wang, Lewei Lu, Bin Li, Jie Zhou, Yu Qiao, Jifeng Dai
0
0
Recently, vision model pre-training has evolved from relying on manually annotated datasets to leveraging large-scale, web-crawled image-text data. Despite these advances, there is no pre-training method that effectively exploits the interleaved image-text data, which is very prevalent on the Internet. Inspired by the recent success of compression learning in natural language processing, we propose a novel vision model pre-training method called Latent Compression Learning (LCL) for interleaved image-text data. This method performs latent compression learning by maximizing the mutual information between the inputs and outputs of a causal attention model. The training objective can be decomposed into two basic tasks: 1) contrastive learning between visual representation and preceding context, and 2) generating subsequent text based on visual representation. Our experiments demonstrate that our method not only matches the performance of CLIP on paired pre-training datasets (e.g., LAION), but can also leverage interleaved pre-training data (e.g., MMC4) to learn robust visual representation from scratch, showcasing the potential of vision model pre-training with interleaved image-text data. Code is released at https://github.com/OpenGVLab/LCL.
6/12/2024