Human Demonstrations are Generalizable Knowledge for Robots
2312.02419
0
0

Abstract
Learning from human demonstrations is an emerging trend for designing intelligent robotic systems. However, previous methods typically regard videos as instructions, simply dividing them into action sequences for robotic repetition, which poses obstacles to generalization to diverse tasks or object instances. In this paper, we propose a different perspective, considering human demonstration videos not as mere instructions, but as a source of knowledge for robots. Motivated by this perspective and the remarkable comprehension and generalization capabilities exhibited by large language models (LLMs), we propose DigKnow, a method that DIstills Generalizable KNOWledge with a hierarchical structure. Specifically, DigKnow begins by converting human demonstration video frames into observation knowledge. This knowledge is then subjected to analysis to extract human action knowledge and further distilled into pattern knowledge compassing task and object instances, resulting in the acquisition of generalizable knowledge with a hierarchical structure. In settings with different tasks or object instances, DigKnow retrieves relevant knowledge for the current task and object instances. Subsequently, the LLM-based planner conducts planning based on the retrieved knowledge, and the policy executes actions in line with the plan to achieve the designated task. Utilizing the retrieved knowledge, we validate and rectify planning and execution outcomes, resulting in a substantial enhancement of the success rate. Experimental results across a range of tasks and scenes demonstrate the effectiveness of this approach in facilitating real-world robots to accomplish tasks with the knowledge derived from human demonstrations.
Create account to get full access
Overview
- This research paper explores the idea that human demonstrations can be used as generalizable knowledge for robots to learn and perform new tasks.
- The paper investigates methods for robots to learn from human demonstrations and apply that knowledge to new, unseen tasks.
- The key focus is on leveraging large language models (LLMs) and few-shot learning techniques to enable robots to quickly adapt and generalize from limited human demonstration data.
Plain English Explanation
Robots are increasingly being used to assist humans with a wide variety of tasks, from household chores to complex industrial applications. However, teaching robots to perform new tasks can be a time-consuming and challenging process, often requiring significant programming effort and careful task-specific design.
This research paper explores the idea that robots can learn from observing human demonstrations of tasks, and then use that knowledge to quickly adapt and perform new, related tasks. The key insight is that humans have a wealth of general knowledge and problem-solving skills that can be leveraged by robots, rather than having to start from scratch for each new task.
By using large language models (LLMs) - powerful AI systems trained on vast amounts of text data - the researchers show that robots can extract meaningful abstractions and generalizable knowledge from human demonstrations. This allows the robots to then apply that knowledge to new tasks, even with limited training data, through a process called few-shot learning.
For example, if a human demonstrates how to set the table, a robot could then use that knowledge to learn how to clear the table or load the dishwasher, without needing to be explicitly programmed for those specific tasks. The robot can understand the underlying principles and adapt its behavior accordingly.
This approach has the potential to make robots much more flexible and adaptable, reducing the need for extensive task-specific programming and enabling them to learn and operate in a more human-like way. It could unlock new possibilities for robots to assist humans in a wide range of applications, from household chores to complex industrial tasks.
Technical Explanation
The paper proposes a framework for learning symbolic task representations from human demonstrations, which can then be used to plan and generalize to new tasks.
The key components of the framework are:
- Task Encoding: An LLM-based encoder is used to extract a symbolic representation of the task from human demonstrations, capturing the underlying steps, goals, and constraints.
- Task Planning: The symbolic task representation is used to plan the sequence of actions needed to complete the task, leveraging few-shot learning techniques to adapt to new variations.
- Skill Reuse: The framework learns and reuses robotic skills (e.g., grasping, moving) that are common across tasks, further improving efficiency and generalization.
The researchers evaluate their approach on a range of simulated household tasks, such as setting the table, clearing the table, and loading the dishwasher. They demonstrate that the robots can quickly adapt to new task variations by leveraging the knowledge gained from human demonstrations, outperforming baselines that do not use this approach.
Critical Analysis
The research paper presents a promising approach for enabling robots to learn and generalize from human demonstrations, but it also raises some important considerations and potential limitations:
- Scalability and Robustness: While the experiments show promising results, it's unclear how well the approach would scale to a wider range of tasks and real-world environments, which may introduce additional complexities and sources of uncertainty.
- Interpretability and Explainability: The use of large language models and implicit knowledge representations may make it challenging to understand and explain the reasoning behind the robot's behaviors and decisions.
- Safety and Reliability: Ensuring the safe and reliable operation of robots that learn from potentially noisy or biased human demonstrations is a critical challenge that requires further investigation.
- Ethical Considerations: As robots become more capable of learning and generalizing from human data, there are important ethical questions around data privacy, algorithmic bias, and the responsible development of these technologies.
Overall, this research represents an important step towards more flexible and adaptable robots, but continued work is needed to address the challenges and limitations identified above.
Conclusion
This research paper introduces a novel framework for enabling robots to learn and generalize from human demonstrations using large language models and few-shot learning techniques. The key insight is that human demonstrations can serve as a rich source of generalizable knowledge that robots can leverage to quickly adapt and perform new tasks, rather than having to be programmed for each specific task.
The proposed approach has the potential to significantly improve the flexibility and adaptability of robots, unlocking new possibilities for their use in a wide range of applications. By tapping into the wealth of knowledge and problem-solving skills inherent in human behavior, robots can become more capable of assisting humans in complex, real-world environments.
While the research presents promising results, there are also important considerations around scalability, interpretability, safety, and ethical implications that will require further investigation. Nonetheless, this work represents an important step towards more intelligent and versatile robotic systems that can seamlessly integrate with and enhance human capabilities.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤯
Robotic Imitation of Human Actions
Josua Spisak, Matthias Kerzel, Stefan Wermter
0
0
Imitation can allow us to quickly gain an understanding of a new task. Through a demonstration, we can gain direct knowledge about which actions need to be performed and which goals they have. In this paper, we introduce a new approach to imitation learning that tackles the challenges of a robot imitating a human, such as the change in perspective and body schema. Our approach can use a single human demonstration to abstract information about the demonstrated task, and use that information to generalise and replicate it. We facilitate this ability by a new integration of two state-of-the-art methods: a diffusion action segmentation model to abstract temporal information from the demonstration and an open vocabulary object detector for spatial information. Furthermore, we refine the abstracted information and use symbolic reasoning to create an action plan utilising inverse kinematics, to allow the robot to imitate the demonstrated action.
6/4/2024
Dreamitate: Real-World Visuomotor Policy Learning via Video Generation
Junbang Liang, Ruoshi Liu, Ege Ozguroglu, Sruthi Sudhakar, Achal Dave, Pavel Tokmakov, Shuran Song, Carl Vondrick
0
0
A key challenge in manipulation is learning a policy that can robustly generalize to diverse visual environments. A promising mechanism for learning robust policies is to leverage video generative models, which are pretrained on large-scale datasets of internet videos. In this paper, we propose a visuomotor policy learning framework that fine-tunes a video diffusion model on human demonstrations of a given task. At test time, we generate an example of an execution of the task conditioned on images of a novel scene, and use this synthesized execution directly to control the robot. Our key insight is that using common tools allows us to effortlessly bridge the embodiment gap between the human hand and the robot manipulator. We evaluate our approach on four tasks of increasing complexity and demonstrate that harnessing internet-scale generative models allows the learned policy to achieve a significantly higher degree of generalization than existing behavior cloning approaches.
6/26/2024

Towards Generalist Robot Learning from Internet Video: A Survey
Robert McCarthy, Daniel C. H. Tan, Dominik Schmidt, Fernando Acero, Nathan Herr, Yilun Du, Thomas G. Thuruthel, Zhibin Li
0
0
This survey presents an overview of methods for learning from video (LfV) in the context of reinforcement learning (RL) and robotics. We focus on methods capable of scaling to large internet video datasets and, in the process, extracting foundational knowledge about the world's dynamics and physical human behaviour. Such methods hold great promise for developing general-purpose robots. We open with an overview of fundamental concepts relevant to the LfV-for-robotics setting. This includes a discussion of the exciting benefits LfV methods can offer (e.g., improved generalization beyond the available robot data) and commentary on key LfV challenges (e.g., missing information in video and LfV distribution shifts). Our literature review begins with an analysis of video foundation model techniques that can extract knowledge from large, heterogeneous video datasets. Next, we review methods that specifically leverage video data for robot learning. Here, we categorise work according to which RL knowledge modality (KM) benefits from the use of video data. We additionally highlight techniques for mitigating LfV challenges, including reviewing action representations that address missing action labels in video. Finally, we examine LfV datasets and benchmarks, before concluding with a discussion of challenges and opportunities in LfV. Here, we advocate for scalable foundation model approaches that can leverage the full range of internet video data, and that target the learning of the most promising RL KMs: the policy and dynamics model. Overall, we hope this survey will serve as a comprehensive reference for the emerging field of LfV, catalysing further research in the area and facilitating progress towards the development of general-purpose robots.
6/10/2024
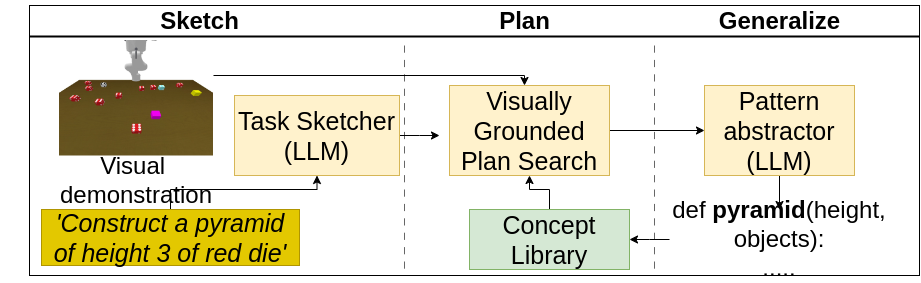
Sketch-Plan-Generalize: Continual Few-Shot Learning of Inductively Generalizable Spatial Concepts for Language-Guided Robot Manipulation
Namasivayam Kalithasan, Sachit Sachdeva, Himanshu Gaurav Singh, Vishal Bindal, Arnav Tuli, Gurarmaan Singh Panjeta, Divyanshu Aggarwal, Rohan Paul, Parag Singla
0
0
Our goal is to enable embodied agents to learn inductively generalizable spatial concepts, e.g., learning staircase as an inductive composition of towers of increasing height. Given a human demonstration, we seek a learning architecture that infers a succinct ${program}$ representation that explains the observed instance. Additionally, the approach should generalize inductively to novel structures of different sizes or complex structures expressed as a hierarchical composition of previously learned concepts. Existing approaches that use code generation capabilities of pre-trained large (visual) language models, as well as purely neural models, show poor generalization to a-priori unseen complex concepts. Our key insight is to factor inductive concept learning as (i) ${it Sketch:}$ detecting and inferring a coarse signature of a new concept (ii) ${it Plan:}$ performing MCTS search over grounded action sequences (iii) ${it Generalize:}$ abstracting out grounded plans as inductive programs. Our pipeline facilitates generalization and modular reuse, enabling continual concept learning. Our approach combines the benefits of the code generation ability of large language models (LLM) along with grounded neural representations, resulting in neuro-symbolic programs that show stronger inductive generalization on the task of constructing complex structures in relation to LLM-only and neural-only approaches. Furthermore, we demonstrate reasoning and planning capabilities with learned concepts for embodied instruction following.
5/30/2024