HVT: A Comprehensive Vision Framework for Learning in Non-Euclidean Space

0

Sign in to get full access
Overview
- This paper introduces HVT, a comprehensive vision framework for learning in non-Euclidean space.
- HVT leverages hyperbolic geometry to learn robust and transferable visual representations.
- The framework demonstrates strong performance on a variety of computer vision tasks.
Plain English Explanation
The paper presents a new approach called HVT (Hyperbolic Vision Transformer) that aims to improve computer vision by taking advantage of the unique properties of hyperbolic geometry. Hyperbolic geometry is a type of non-Euclidean geometry that has been shown to be well-suited for modeling certain types of data, like hierarchical structures.
The key idea behind HVT is to use hyperbolic space as the underlying representation for visual information, rather than the standard Euclidean space used by most computer vision models. This allows the framework to better capture the inherent hierarchical and tree-like structures present in many real-world visual data, such as object taxonomies or scene layouts.
By learning visual representations in this hyperbolic space, HVT is able to achieve superior performance on a wide range of computer vision tasks, including image classification, object detection, and semantic segmentation. The authors demonstrate that HVT outperforms standard Euclidean-based models, particularly on tasks that require reasoning about hierarchical or relational structures.
Technical Explanation
The core of the HVT framework is a hyperbolic variant of the popular Vision Transformer (ViT) architecture. ViT is a deep learning model that operates directly on image patches, rather than using convolutional layers like traditional CNN models.
In HVT, the standard Euclidean positional embeddings used in ViT are replaced with hyperbolic positional embeddings, which can better capture the hierarchical and tree-like structures present in visual data. The transformer layers in HVT also operate in the hyperbolic space, using specialized attention mechanisms and feed-forward layers that are adapted for this non-Euclidean geometry.
To train HVT, the authors introduce a novel hyperbolic contrastive learning objective that encourages the model to learn visual representations that are well-aligned with the underlying hyperbolic structure of the data. This is combined with standard vision transformer training techniques, such as patch embedding and multi-head attention.
The experiments in the paper demonstrate that HVT achieves state-of-the-art performance on a variety of computer vision benchmarks, including ImageNet classification, COCO object detection, and ADE20K semantic segmentation. The authors attribute this success to HVT's ability to better capture the hierarchical relationships and structural properties of visual data.
Critical Analysis
One key limitation of the HVT framework is that it relies on the assumption that the underlying data manifold can be well-represented by hyperbolic geometry. While this assumption may hold for certain types of visual data, it may not be universally true across all computer vision tasks and datasets.
Additionally, the specialized hyperbolic operations used in HVT, such as the attention mechanism and feed-forward layers, can introduce additional computational complexity and memory requirements compared to standard Euclidean-based models. This could make HVT more challenging to deploy in resource-constrained environments, such as on mobile devices or embedded systems.
The paper also does not provide a detailed analysis of the kinds of visual structures or hierarchies that HVT is particularly well-suited to capture. Further research may be needed to better understand the types of visual reasoning problems where the hyperbolic inductive bias of HVT provides the greatest benefits.
Despite these potential limitations, the strong empirical results presented in the paper suggest that the HVT framework represents a promising direction for leveraging the unique properties of hyperbolic geometry to advance the state-of-the-art in computer vision.
Conclusion
The HVT framework introduced in this paper demonstrates the potential of using hyperbolic geometry to learn more powerful and transferable visual representations. By operating in a non-Euclidean space that can better capture hierarchical and structural information, HVT is able to outperform standard Euclidean-based models on a variety of computer vision tasks.
While the framework has some limitations, the strong empirical results suggest that further research into hyperbolic deep learning models could lead to significant advancements in computer vision and other domains that involve reasoning about complex, hierarchical data. As the field continues to explore the applications of non-Euclidean geometries in machine learning, the HVT approach represents an important step forward in this direction.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
HVT: A Comprehensive Vision Framework for Learning in Non-Euclidean Space
Jacob Fein-Ashley, Ethan Feng, Minh Pham
Data representation in non-Euclidean spaces has proven effective for capturing hierarchical and complex relationships in real-world datasets. Hyperbolic spaces, in particular, provide efficient embeddings for hierarchical structures. This paper introduces the Hyperbolic Vision Transformer (HVT), a novel extension of the Vision Transformer (ViT) that integrates hyperbolic geometry. While traditional ViTs operate in Euclidean space, our method enhances the self-attention mechanism by leveraging hyperbolic distance and Mobius transformations. This enables more effective modeling of hierarchical and relational dependencies in image data. We present rigorous mathematical formulations, showing how hyperbolic geometry can be incorporated into attention layers, feed-forward networks, and optimization. We offer improved performance for image classification using the ImageNet dataset.
Read more9/27/2024
0
A Geometry-Aware Algorithm to Learn Hierarchical Embeddings in Hyperbolic Space
Zhangyu Wang, Lantian Xu, Zhifeng Kong, Weilong Wang, Xuyu Peng, Enyang Zheng
Hyperbolic embeddings are a class of representation learning methods that offer competitive performances when data can be abstracted as a tree-like graph. However, in practice, learning hyperbolic embeddings of hierarchical data is difficult due to the different geometry between hyperbolic space and the Euclidean space. To address such difficulties, we first categorize three kinds of illness that harm the performance of the embeddings. Then, we develop a geometry-aware algorithm using a dilation operation and a transitive closure regularization to tackle these illnesses. We empirically validate these techniques and present a theoretical analysis of the mechanism behind the dilation operation. Experiments on synthetic and real-world datasets reveal superior performances of our algorithm.
Read more7/24/2024
🤔
0
Understanding Hyperbolic Metric Learning through Hard Negative Sampling
Yun Yue, Fangzhou Lin, Guanyi Mou, Ziming Zhang
In recent years, there has been a growing trend of incorporating hyperbolic geometry methods into computer vision. While these methods have achieved state-of-the-art performance on various metric learning tasks using hyperbolic distance measurements, the underlying theoretical analysis supporting this superior performance remains under-exploited. In this study, we investigate the effects of integrating hyperbolic space into metric learning, particularly when training with contrastive loss. We identify a need for a comprehensive comparison between Euclidean and hyperbolic spaces regarding the temperature effect in the contrastive loss within the existing literature. To address this gap, we conduct an extensive investigation to benchmark the results of Vision Transformers (ViTs) using a hybrid objective function that combines loss from Euclidean and hyperbolic spaces. Additionally, we provide a theoretical analysis of the observed performance improvement. We also reveal that hyperbolic metric learning is highly related to hard negative sampling, providing insights for future work. This work will provide valuable data points and experience in understanding hyperbolic image embeddings. To shed more light on problem-solving and encourage further investigation into our approach, our code is available online (https://github.com/YunYunY/HypMix).
Read more5/6/2024
0
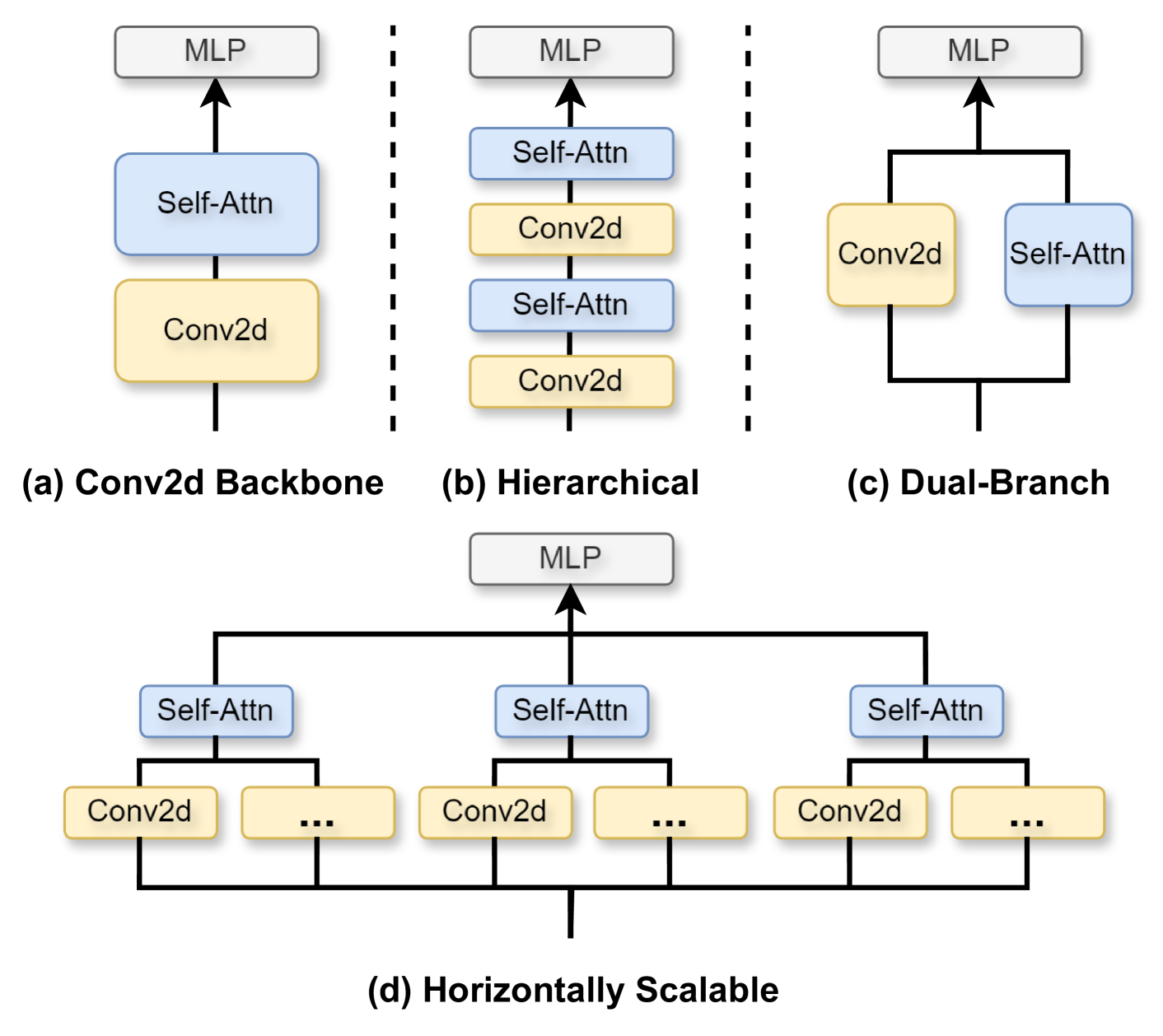
HSViT: Horizontally Scalable Vision Transformer
Chenhao Xu, Chang-Tsun Li, Chee Peng Lim, Douglas Creighton
Due to its deficiency in prior knowledge (inductive bias), Vision Transformer (ViT) requires pre-training on large-scale datasets to perform well. Moreover, the growing layers and parameters in ViT models impede their applicability to devices with limited computing resources. To mitigate the aforementioned challenges, this paper introduces a novel horizontally scalable vision transformer (HSViT) scheme. Specifically, a novel image-level feature embedding is introduced to ViT, where the preserved inductive bias allows the model to eliminate the need for pre-training while outperforming on small datasets. Besides, a novel horizontally scalable architecture is designed, facilitating collaborative model training and inference across multiple computing devices. The experimental results depict that, without pre-training, HSViT achieves up to 10% higher top-1 accuracy than state-of-the-art schemes on small datasets, while providing existing CNN backbones up to 3.1% improvement in top-1 accuracy on ImageNet. The code is available at https://github.com/xuchenhao001/HSViT.
Read more7/17/2024