Hybrid Approach to Parallel Stochastic Gradient Descent

0

Sign in to get full access
Overview
- This paper proposes a hybrid approach to parallel stochastic gradient descent (SGD) for distributed optimization.
- It combines synchronous and asynchronous methods to address the limitations of each approach and achieve better performance.
- The hybrid method aims to leverage the benefits of both synchronous and asynchronous SGD while mitigating their drawbacks.
Plain English Explanation
Stochastic gradient descent (SGD) is a widely used optimization technique in machine learning, especially for training large-scale models. When training these models, it's often beneficial to split the work across multiple computers or "workers" to speed up the process. This is called data parallelism.
Two common approaches to parallel SGD are the synchronous and asynchronous methods. In the synchronous approach, all workers compute gradients on their assigned data, then wait for each other before updating the shared model. This ensures the model updates are consistent, but it can be slow if some workers are slower than others.
The asynchronous approach allows workers to update the model immediately without waiting for others. This can be faster, but the model updates may be less consistent, which can lead to convergence issues.
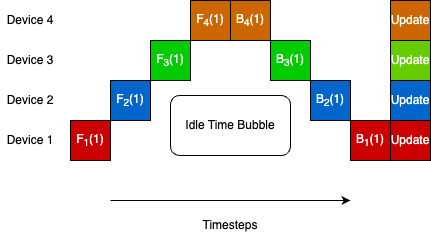
The paper proposes a hybrid approach that combines the strengths of both synchronous and asynchronous SGD. The idea is to use synchronous updates for a certain number of iterations, then switch to asynchronous updates for a while, and then repeat this cycle. This allows the method to benefit from the consistency of synchronous updates and the speed of asynchronous updates, while mitigating the drawbacks of each approach.
The authors demonstrate that their hybrid method can outperform both the synchronous and asynchronous approaches on various machine learning tasks, making it a promising technique for distributed optimization.
Technical Explanation
The paper introduces a hybrid approach to parallel stochastic gradient descent (SGD) that combines synchronous and asynchronous updates. The key idea is to alternate between these two update schemes in a cyclic fashion.
During the synchronous phase, workers compute gradients on their assigned data and wait for each other before updating the shared model. This ensures the model updates are consistent, but it can be slow if some workers are slower than others.
In the asynchronous phase, workers update the model immediately without waiting for others. This can be faster, but the model updates may be less consistent, which can lead to convergence issues.
By alternating between these two update schemes, the hybrid approach aims to leverage the benefits of both synchronous and asynchronous SGD while mitigating their drawbacks. The authors provide theoretical analysis to show that their hybrid method converges to the optimal solution under certain conditions.
The paper also presents extensive experiments on various machine learning tasks, including image classification and language modeling. The results demonstrate that the proposed hybrid method outperforms both the synchronous and asynchronous approaches in terms of convergence speed and final model performance.
Critical Analysis
The paper provides a thoughtful approach to addressing the trade-offs between synchronous and asynchronous SGD in the context of distributed optimization. The authors acknowledge that both methods have their own strengths and weaknesses, and the hybrid approach is an attempt to balance these considerations.
One potential limitation of the hybrid method is the need to carefully choose the duration of the synchronous and asynchronous phases. The authors mention that this can be problem-dependent, and finding the optimal cycle length may require additional tuning or heuristics.
Additionally, the paper focuses on the case of homogeneous worker machines, where all workers have similar computational capabilities. In real-world scenarios, the workers may have varying hardware configurations and processing speeds, which could introduce additional challenges. The authors mention this as a direction for future research, and it would be interesting to see how the hybrid method could be extended to handle heterogeneous worker environments.
Overall, the paper presents a promising hybrid approach that combines the strengths of synchronous and asynchronous SGD. The thorough experimental evaluation and the theoretical analysis provide a solid foundation for the proposed method. As the field of distributed optimization continues to evolve, this research could inspire further advancements in parallel training algorithms.
Conclusion
This paper introduces a hybrid approach to parallel stochastic gradient descent (SGD) that combines synchronous and asynchronous update schemes. The key idea is to alternate between these two update methods in a cyclic fashion, leveraging the benefits of both while mitigating their drawbacks.
The authors provide a theoretical analysis of the convergence properties of the hybrid method and demonstrate its empirical performance on various machine learning tasks. The results show that the proposed approach can outperform both the synchronous and asynchronous approaches in terms of convergence speed and final model performance.
The hybrid method presented in this paper represents a step forward in addressing the trade-offs inherent in parallel optimization algorithms. As machine learning models continue to grow in complexity, techniques like this that can efficiently harness the power of distributed computing will become increasingly important. This research could inspire further advancements in the field of distributed optimization and parallel training algorithms.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Hybrid Approach to Parallel Stochastic Gradient Descent
Aakash Sudhirbhai Vora, Dhrumil Chetankumar Joshi, Aksh Kantibhai Patel
Stochastic Gradient Descent is used for large datasets to train models to reduce the training time. On top of that data parallelism is widely used as a method to efficiently train neural networks using multiple worker nodes in parallel. Synchronous and asynchronous approach to data parallelism is used by most systems to train the model in parallel. However, both of them have their drawbacks. We propose a third approach to data parallelism which is a hybrid between synchronous and asynchronous approaches, using both approaches to train the neural network. When the threshold function is selected appropriately to gradually shift all parameter aggregation from asynchronous to synchronous, we show that in a given time period our hybrid approach outperforms both asynchronous and synchronous approaches.
Read more7/2/2024
0
Ravnest: Decentralized Asynchronous Training on Heterogeneous Devices
Anirudh Rajiv Menon, Unnikrishnan Menon, Kailash Ahirwar
Modern deep learning models, growing larger and more complex, have demonstrated exceptional generalization and accuracy due to training on huge datasets. This trend is expected to continue. However, the increasing size of these models poses challenges in training, as traditional centralized methods are limited by memory constraints at such scales. This paper proposes an asynchronous decentralized training paradigm for large modern deep learning models that harnesses the compute power of regular heterogeneous PCs with limited resources connected across the internet to achieve favourable performance metrics. Ravnest facilitates decentralized training by efficiently organizing compute nodes into clusters with similar data transfer rates and compute capabilities, without necessitating that each node hosts the entire model. These clusters engage in $textit{Zero-Bubble Asynchronous Model Parallel}$ training, and a $textit{Parallel Multi-Ring All-Reduce}$ method is employed to effectively execute global parameter averaging across all clusters. We have framed our asynchronous SGD loss function as a block structured optimization problem with delayed updates and derived an optimal convergence rate of $Oleft(frac{1}{sqrt{K}}right)$. We further discuss linear speedup with respect to the number of participating clusters and the bound on the staleness parameter.
Read more5/24/2024
🧠
0
GSplit: Scaling Graph Neural Network Training on Large Graphs via Split-Parallelism
Sandeep Polisetty, Juelin Liu, Kobi Falus, Yi Ren Fung, Seung-Hwan Lim, Hui Guan, Marco Serafini
Graph neural networks (GNNs), an emerging class of machine learning models for graphs, have gained popularity for their superior performance in various graph analytical tasks. Mini-batch training is commonly used to train GNNs on large graphs, and data parallelism is the standard approach to scale mini-batch training across multiple GPUs. One of the major performance costs in GNN training is the loading of input features, which prevents GPUs from being fully utilized. In this paper, we argue that this problem is exacerbated by redundancies that are inherent to the data parallel approach. To address this issue, we introduce a hybrid parallel mini-batch training paradigm called split parallelism. Split parallelism avoids redundant data loads and splits the sampling and training of each mini-batch across multiple GPUs online, at each iteration, using a lightweight splitting algorithm. We implement split parallelism in GSplit and show that it outperforms state-of-the-art mini-batch training systems like DGL, Quiver, and $P^3$.
Read more6/28/2024

0
High-Dimensional Sparse Data Low-rank Representation via Accelerated Asynchronous Parallel Stochastic Gradient Descent
Qicong Hu, Hao Wu
Data characterized by high dimensionality and sparsity are commonly used to describe real-world node interactions. Low-rank representation (LR) can map high-dimensional sparse (HDS) data to low-dimensional feature spaces and infer node interactions via modeling data latent associations. Unfortunately, existing optimization algorithms for LR models are computationally inefficient and slowly convergent on large-scale datasets. To address this issue, this paper proposes an Accelerated Asynchronous Parallel Stochastic Gradient Descent A2PSGD for High-Dimensional Sparse Data Low-rank Representation with three fold-ideas: a) establishing a lock-free scheduler to simultaneously respond to scheduling requests from multiple threads; b) introducing a greedy algorithm-based load balancing strategy for balancing the computational load among threads; c) incorporating Nesterov's accelerated gradient into the learning scheme to accelerate model convergence. Empirical studies show that A2PSGD outperforms existing optimization algorithms for HDS data LR in both accuracy and training time.
Read more8/30/2024