HyperBERT: Mixing Hypergraph-Aware Layers with Language Models for Node Classification on Text-Attributed Hypergraphs

0
💬
Sign in to get full access
Overview
- Hypergraphs are a complex data structure that can represent higher-order interactions among multiple entities
- Hypergraph-based deep learning methods have been explored for node classification on text-attributed hypergraphs
- Existing methods struggle to capture both the hypergraph structure and the rich linguistic attributes of the nodes
- This paper proposes a new architecture, HyperBERT, to address these challenges
Plain English Explanation
Hypergraphs are a way of representing complex relationships between multiple things at the same time. For example, a hypergraph could show how a group of people, locations, and events are all connected. Existing machine learning methods have tried to use hypergraphs for tasks like classifying the type of information in the nodes (the individual things) of a hypergraph. However, these methods have had trouble fully capturing both the structure of the hypergraph and the meaning of the text associated with each node.
The HyperBERT model proposed in this paper aims to solve this problem. It combines a powerful language model (BERT) with specialized layers that can better understand the higher-order relationships in the hypergraph structure. This allows the model to leverage both the contextual information from the hypergraph and the semantic information from the text to improve its performance on node classification tasks.
Technical Explanation
The key innovation of the HyperBERT model is the introduction of specialized "hypergraph-aware" layers that are added to a pre-trained BERT model. These layers are designed to capture the higher-order structural information present in the hypergraph, which complements the strong text encoding capabilities of BERT.
The hypergraph-aware layers work by first learning embeddings for the hyperedges (the connections between multiple nodes) in the hypergraph. These embeddings are then used to guide the attention mechanism of the BERT model, allowing it to focus on the most relevant higher-order relationships when encoding the node text. This architecture helps the model better harness both the structural context from the hypergraph and the semantic information from the node attributes.
The authors evaluate HyperBERT on five challenging text-attributed hypergraph node classification benchmarks, and report that it achieves new state-of-the-art results. This demonstrates the effectiveness of their approach in leveraging the complementary strengths of hypergraph structure and text semantics.
Critical Analysis
The HyperBERT paper makes a compelling case for the importance of jointly modeling higher-order hypergraph structure and node text attributes for improved node classification performance. The authors provide a thorough experimental evaluation, comparing their model to a range of baselines and prior methods such as topology-guided hypergraph transformer networks, hyperbolic heterogeneous graph attention networks, and HiGPT.
That said, the paper does not discuss potential limitations or caveats of the HyperBERT approach. For example, the computational complexity of the hypergraph-aware layers and their scalability to very large hypergraphs are not explored. Additionally, the authors do not investigate how HyperBERT might perform on tasks beyond node classification, such as link prediction or hypergraph generation.
Overall, the HyperBERT model represents a promising advance in hypergraph representation learning and could have valuable applications in fields like social network analysis, biology, and recommendation systems. Further research is needed to fully understand the capabilities and limitations of this approach.
Conclusion
In this paper, the authors have introduced HyperBERT, a novel deep learning architecture for node classification on text-attributed hypergraphs. HyperBERT combines the strengths of a pre-trained BERT model with specialized layers that can effectively capture the higher-order structural information present in hypergraphs.
By jointly modeling both the hypergraph topology and the node text attributes, HyperBERT is able to achieve state-of-the-art performance on several challenging benchmarks. This work represents an important step forward in our ability to extract insights from complex, multi-relational data structures like hypergraphs, with potential applications in a wide range of domains.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
0
HyperBERT: Mixing Hypergraph-Aware Layers with Language Models for Node Classification on Text-Attributed Hypergraphs
Adri'an Bazaga, Pietro Li`o, Gos Micklem
Hypergraphs are characterized by complex topological structure, representing higher-order interactions among multiple entities through hyperedges. Lately, hypergraph-based deep learning methods to learn informative data representations for the problem of node classification on text-attributed hypergraphs have garnered increasing research attention. However, existing methods struggle to simultaneously capture the full extent of hypergraph structural information and the rich linguistic attributes inherent in the nodes attributes, which largely hampers their effectiveness and generalizability. To overcome these challenges, we explore ways to further augment a pretrained BERT model with specialized hypergraph-aware layers for the task of node classification. Such layers introduce higher-order structural inductive bias into the language model, thus improving the model's capacity to harness both higher-order context information from the hypergraph structure and semantic information present in text. In this paper, we propose a new architecture, HyperBERT, a mixed text-hypergraph model which simultaneously models hypergraph relational structure while maintaining the high-quality text encoding capabilities of a pre-trained BERT. Notably, HyperBERT presents results that achieve a new state-of-the-art on five challenging text-attributed hypergraph node classification benchmarks.
Read more9/30/2024

0
Hypergraph Transformer for Semi-Supervised Classification
Zexi Liu, Bohan Tang, Ziyuan Ye, Xiaowen Dong, Siheng Chen, Yanfeng Wang
Hypergraphs play a pivotal role in the modelling of data featuring higher-order relations involving more than two entities. Hypergraph neural networks emerge as a powerful tool for processing hypergraph-structured data, delivering remarkable performance across various tasks, e.g., hypergraph node classification. However, these models struggle to capture global structural information due to their reliance on local message passing. To address this challenge, we propose a novel hypergraph learning framework, HyperGraph Transformer (HyperGT). HyperGT uses a Transformer-based neural network architecture to effectively consider global correlations among all nodes and hyperedges. To incorporate local structural information, HyperGT has two distinct designs: i) a positional encoding based on the hypergraph incidence matrix, offering valuable insights into node-node and hyperedge-hyperedge interactions; and ii) a hypergraph structure regularization in the loss function, capturing connectivities between nodes and hyperedges. Through these designs, HyperGT achieves comprehensive hypergraph representation learning by effectively incorporating global interactions while preserving local connectivity patterns. Extensive experiments conducted on real-world hypergraph node classification tasks showcase that HyperGT consistently outperforms existing methods, establishing new state-of-the-art benchmarks. Ablation studies affirm the effectiveness of the individual designs of our model.
Read more6/4/2024
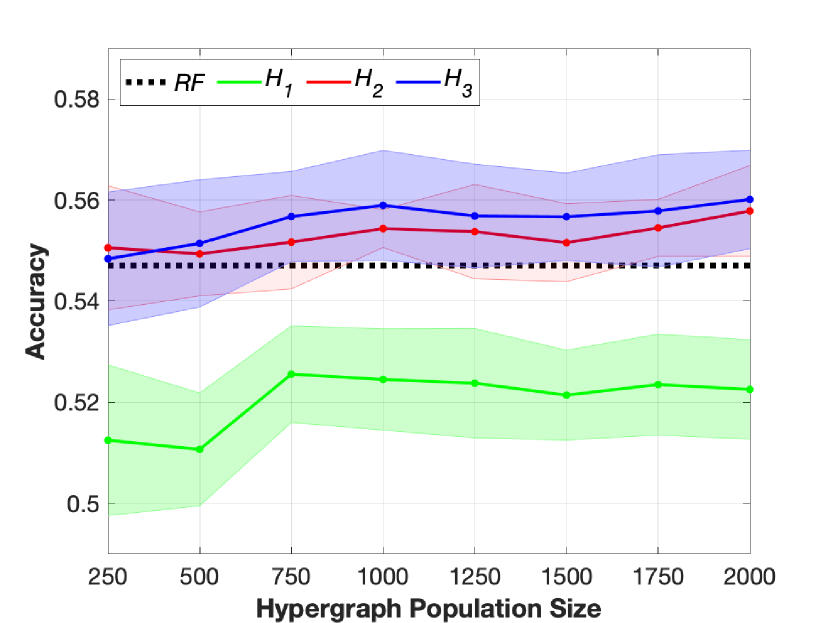
0
A classification model based on a population of hypergraphs
Samuel Barton, Adelle Coster, Diane Donovan, James Lefevre
This paper introduces a novel hypergraph classification algorithm. The use of hypergraphs in this framework has been widely studied. In previous work, hypergraph models are typically constructed using distance or attribute based methods. That is, hyperedges are generated by connecting a set of samples which are within a certain distance or have a common attribute. These methods however, do not often focus on multi-way interactions directly. The algorithm provided in this paper looks to address this problem by constructing hypergraphs which explore multi-way interactions of any order. We also increase the performance and robustness of the algorithm by using a population of hypergraphs. The algorithm is evaluated on two datasets, demonstrating promising performance compared to a generic random forest classification algorithm.
Read more5/27/2024

0
New!Language Models are Graph Learners
Zhe Xu, Kaveh Hassani, Si Zhang, Hanqing Zeng, Michihiro Yasunaga, Limei Wang, Dongqi Fu, Ning Yao, Bo Long, Hanghang Tong
Language Models (LMs) are increasingly challenging the dominance of domain-specific models, including Graph Neural Networks (GNNs) and Graph Transformers (GTs), in graph learning tasks. Following this trend, we propose a novel approach that empowers off-the-shelf LMs to achieve performance comparable to state-of-the-art GNNs on node classification tasks, without requiring any architectural modification. By preserving the LM's original architecture, our approach retains a key benefit of LM instruction tuning: the ability to jointly train on diverse datasets, fostering greater flexibility and efficiency. To achieve this, we introduce two key augmentation strategies: (1) Enriching LMs' input using topological and semantic retrieval methods, which provide richer contextual information, and (2) guiding the LMs' classification process through a lightweight GNN classifier that effectively prunes class candidates. Our experiments on real-world datasets show that backbone Flan-T5 models equipped with these augmentation strategies outperform state-of-the-art text-output node classifiers and are comparable to top-performing vector-output node classifiers. By bridging the gap between specialized task-specific node classifiers and general LMs, this work paves the way for more versatile and widely applicable graph learning models. We will open-source the code upon publication.
Read more10/4/2024