Hyperbolic Random Forests

0
👨🏫
Sign in to get full access
Overview
- Hyperbolic space is becoming popular for representing hierarchical data
- Existing hyperbolic classifiers struggle with complex hierarchical data
- This paper proposes generalizing random forests to work in hyperbolic space
Plain English Explanation
Hyperbolic space is a type of geometric space that is useful for representing data with a hierarchical structure, whether that hierarchy is explicit or implicit. Many real-world datasets, such as population hypergraphs, have this kind of hierarchical organization, so hyperbolic space is becoming a popular choice for working with them.
However, to use this kind of space effectively, we need algorithms that can perform fundamental tasks like classification. Recent research has looked at adapting traditional classifiers like logistic regression and support vector machines (SVMs) to work in hyperbolic space. While these approaches can be effective, they struggle when dealing with more complex hierarchical data.
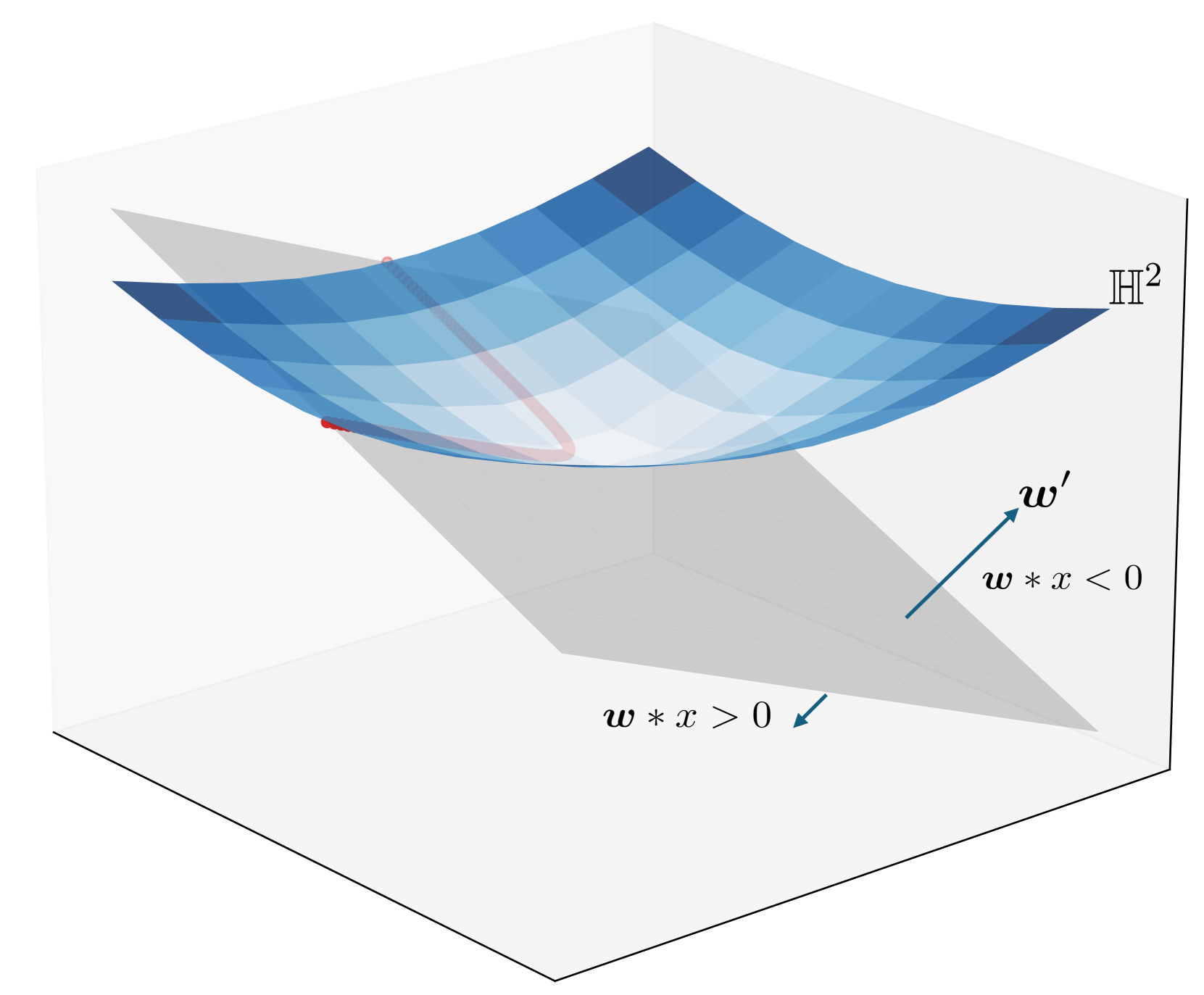
To address this, the researchers in this paper propose generalizing the well-known random forests algorithm to work in hyperbolic space. They do this by redefining the way the algorithm splits the data, using a concept called "horospheres" instead of the usual hyperplanes.
Finding the globally optimal split is computationally difficult, so the researchers use a large-margin classifier to find good candidate horospheres instead. They also outline new methods for handling multi-class data and imbalanced datasets in this hyperbolic random forest framework.
Experiments show that this approach outperforms both standard random forests and other recent hyperbolic classifiers on a range of benchmark datasets.
Technical Explanation
The key innovation in this paper is the generalization of random forests to operate in hyperbolic space, rather than the typical Euclidean space.
To do this, the researchers redefine the notion of a split in the decision trees that make up a random forest. Instead of using hyperplanes, which are flat surfaces in Euclidean space, they use horospheres, which are curved surfaces in hyperbolic space.
Finding the globally optimal horosphere split is computationally intractable, so the researchers instead use a large-margin classifier to identify promising candidate horospheres.
To handle multi-class data and imbalanced datasets, the researchers also propose a new method for combining classes based on their lowest common ancestor, as well as a class-balanced version of the large-margin loss function.
Experiments on standard and newly introduced benchmark datasets show that this hyperbolic random forest approach outperforms both conventional random forests and other recent hyperbolic classifiers, such as those based on logistic regression or SVMs.
Critical Analysis
The paper provides a solid technical contribution by generalizing the popular random forests algorithm to work in hyperbolic space. This is a valuable advancement, as it allows this powerful machine learning technique to be applied to datasets with inherent hierarchical structure.
That said, the paper does not address some potential limitations or areas for further research. For example, the computational complexity of finding optimal horosphere splits is still an open challenge, and the proposed large-margin approach may not be the most efficient solution. Additionally, the paper does not explore the interpretability of the resulting hyperbolic random forests, which is an important consideration for many real-world applications.
Further research could also investigate the performance of this approach on a wider range of hierarchical datasets, including those from domains like textual entailment or population modeling, to better understand its broader applicability and potential limitations.
Conclusion
This paper presents an innovative approach to adapting the classic random forests algorithm to work in hyperbolic space, which is becoming an increasingly popular choice for representing hierarchical data. By redefining the split criterion using horospheres and introducing new methods for handling multi-class and imbalanced datasets, the researchers have developed a powerful hyperbolic classifier that outperforms existing approaches.
While the paper leaves room for further exploration of the technique's limitations and potential extensions, it represents an important step forward in making sophisticated machine learning tools available for datasets with inherent hierarchical structure. This work could have significant implications for a wide range of real-world applications where such data is common.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
👨🏫
0
Hyperbolic Random Forests
Lars Doorenbos, Pablo M'arquez-Neila, Raphael Sznitman, Pascal Mettes
Hyperbolic space is becoming a popular choice for representing data due to the hierarchical structure - whether implicit or explicit - of many real-world datasets. Along with it comes a need for algorithms capable of solving fundamental tasks, such as classification, in hyperbolic space. Recently, multiple papers have investigated hyperbolic alternatives to hyperplane-based classifiers, such as logistic regression and SVMs. While effective, these approaches struggle with more complex hierarchical data. We, therefore, propose to generalize the well-known random forests to hyperbolic space. We do this by redefining the notion of a split using horospheres. Since finding the globally optimal split is computationally intractable, we find candidate horospheres through a large-margin classifier. To make hyperbolic random forests work on multi-class data and imbalanced experiments, we furthermore outline a new method for combining classes based on their lowest common ancestor and a class-balanced version of the large-margin loss. Experiments on standard and new benchmarks show that our approach outperforms both conventional random forest algorithms and recent hyperbolic classifiers.
Read more6/26/2024
🔎
0
Mixed-Curvature Decision Trees and Random Forests
Philippe Chlenski, Quentin Chu, Itsik Pe'er
We extend decision tree and random forest algorithms to product space manifolds: Cartesian products of Euclidean, hyperspherical, and hyperbolic manifolds. Such spaces have extremely expressive geometries capable of representing many arrangements of distances with low metric distortion. To date, all classifiers for product spaces fit a single linear decision boundary, and no regressor has been described. Our method enables a simple, expressive method for classification and regression in product manifolds. We demonstrate the superior accuracy of our tool compared to Euclidean methods operating in the ambient space or the tangent plane of the manifold across a range of constant-curvature and product manifolds. Code for our implementation and experiments is available at https://github.com/pchlenski/embedders.
Read more7/19/2024
0
Convex Relaxation for Solving Large-Margin Classifiers in Hyperbolic Space
Sheng Yang, Peihan Liu, Cengiz Pehlevan
Hyperbolic spaces have increasingly been recognized for their outstanding performance in handling data with inherent hierarchical structures compared to their Euclidean counterparts. However, learning in hyperbolic spaces poses significant challenges. In particular, extending support vector machines to hyperbolic spaces is in general a constrained non-convex optimization problem. Previous and popular attempts to solve hyperbolic SVMs, primarily using projected gradient descent, are generally sensitive to hyperparameters and initializations, often leading to suboptimal solutions. In this work, by first rewriting the problem into a polynomial optimization, we apply semidefinite relaxation and sparse moment-sum-of-squares relaxation to effectively approximate the optima. From extensive empirical experiments, these methods are shown to perform better than the projected gradient descent approach.
Read more5/28/2024
0
A Geometry-Aware Algorithm to Learn Hierarchical Embeddings in Hyperbolic Space
Zhangyu Wang, Lantian Xu, Zhifeng Kong, Weilong Wang, Xuyu Peng, Enyang Zheng
Hyperbolic embeddings are a class of representation learning methods that offer competitive performances when data can be abstracted as a tree-like graph. However, in practice, learning hyperbolic embeddings of hierarchical data is difficult due to the different geometry between hyperbolic space and the Euclidean space. To address such difficulties, we first categorize three kinds of illness that harm the performance of the embeddings. Then, we develop a geometry-aware algorithm using a dilation operation and a transitive closure regularization to tackle these illnesses. We empirically validate these techniques and present a theoretical analysis of the mechanism behind the dilation operation. Experiments on synthetic and real-world datasets reveal superior performances of our algorithm.
Read more7/24/2024