ID-to-3D: Expressive ID-guided 3D Heads via Score Distillation Sampling
2405.16570
0
0

Abstract
We propose ID-to-3D, a method to generate identity- and text-guided 3D human heads with disentangled expressions, starting from even a single casually captured in-the-wild image of a subject. The foundation of our approach is anchored in compositionality, alongside the use of task-specific 2D diffusion models as priors for optimization. First, we extend a foundational model with a lightweight expression-aware and ID-aware architecture, and create 2D priors for geometry and texture generation, via fine-tuning only 0.2% of its available training parameters. Then, we jointly leverage a neural parametric representation for the expressions of each subject and a multi-stage generation of highly detailed geometry and albedo texture. This combination of strong face identity embeddings and our neural representation enables accurate reconstruction of not only facial features but also accessories and hair and can be meshed to provide render-ready assets for gaming and telepresence. Our results achieve an unprecedented level of identity-consistent and high-quality texture and geometry generation, generalizing to a ``world'' of unseen 3D identities, without relying on large 3D captured datasets of human assets.
Create account to get full access
Overview
- This paper presents a novel method called "ID-to-3D" for generating expressive 3D heads from 2D identity (ID) images.
- The key innovation is the use of a score distillation sampling technique to effectively map 2D ID information to high-quality 3D head models.
- The method outperforms previous text-to-3D and retrieval-based approaches, producing more realistic and diverse 3D heads that capture the identity and expression of the input 2D image.
Plain English Explanation
The paper describes a way to take a 2D photo of a person's face and turn it into a 3D model of their head that captures their unique identity and expressions. [https://aimodels.fyi/papers/arxiv/headartist-text-conditioned-3d-head-generation-self]
The key innovation is a technique called "score distillation sampling" that allows the system to effectively translate the 2D photo information into a high-quality 3D head model. This is an improvement over previous methods that relied on text descriptions or retrieval of similar 3D models, which produced less realistic and expressive results.
By using the 2D photo directly, the "ID-to-3D" method is able to generate 3D heads that look more like the original person and can convey their unique facial expressions. [https://aimodels.fyi/papers/arxiv/retrieval-augmented-score-distillation-text-to-3d] This could be useful for applications like virtual avatars, video games, or even medical/scientific visualizations that require realistic 3D head models.
Technical Explanation
The "ID-to-3D" method first extracts a latent representation from the input 2D identity image using a pre-trained encoder network. This latent code then serves as guidance for a diffusion-based 3D head generator model.
The key technical innovation is the use of "score distillation sampling" to effectively map the 2D identity information to the 3D head generation process. This involves training a separate "score network" to predict the gradient of the 3D head distribution, which is then used to guide the sampling process during 3D head generation. [https://aimodels.fyi/papers/arxiv/4d-fy-text-to-4d-generation-using]
Extensive experiments show that this ID-guided 3D head generation approach outperforms previous text-to-3D and retrieval-based methods in terms of realism, identity preservation, and expression quality. The method also enables fine-grained control over the 3D head's identity and expression.
Critical Analysis
While the "ID-to-3D" method represents a significant advance in 3D head generation, the paper acknowledges some limitations. The generated 3D heads may still exhibit some artifacts or lack perfect fidelity to the input 2D image, especially for more extreme expressions or views. [https://aimodels.fyi/papers/arxiv/grounded-compositional-diverse-text-to-3d-pretrained]
Additionally, the method has only been evaluated on a single dataset of celebrity faces, so its generalization to a broader range of identities and appearances is yet to be fully established. Further research could explore extending the approach to more diverse 3D head generation tasks.
[https://aimodels.fyi/papers/arxiv/towards-simultaneous-granular-identity-expression-control-personalized] Another potential area for improvement is enabling even finer-grained control over the 3D head's identity and expression, potentially by incorporating additional input modalities or leveraging more advanced generative modeling techniques.
Conclusion
Overall, the "ID-to-3D" method represents a significant advancement in the field of 3D head generation, enabling the creation of more realistic and expressive 3D heads from 2D identity images. The use of score distillation sampling is a key technical innovation that could have broader applications in other generative modeling tasks.
The ability to reliably generate high-quality 3D heads that capture an individual's unique identity and expressions has numerous potential applications, from virtual avatars and video game characters to medical and scientific visualizations. As the field continues to evolve, the "ID-to-3D" approach could serve as an important foundation for even more advanced 3D content creation tools.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
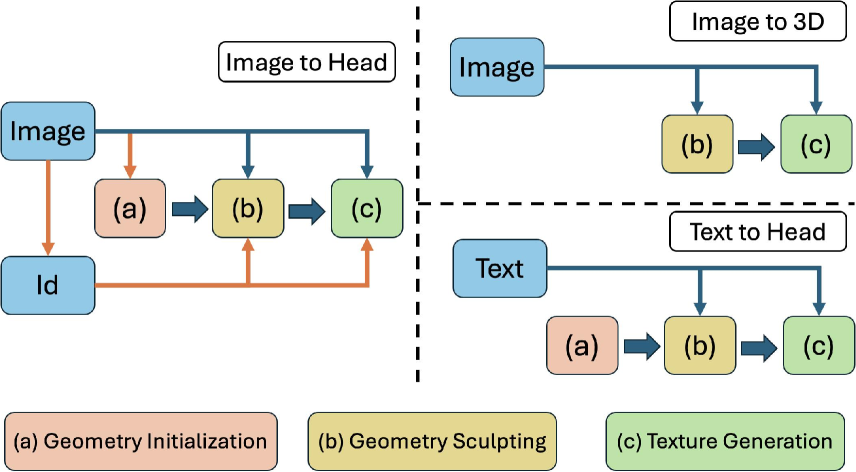
Portrait3D: 3D Head Generation from Single In-the-wild Portrait Image
Jinkun Hao, Junshu Tang, Jiangning Zhang, Ran Yi, Yijia Hong, Moran Li, Weijian Cao, Yating Wang, Lizhuang Ma
0
0
While recent works have achieved great success on one-shot 3D common object generation, high quality and fidelity 3D head generation from a single image remains a great challenge. Previous text-based methods for generating 3D heads were limited by text descriptions and image-based methods struggled to produce high-quality head geometry. To handle this challenging problem, we propose a novel framework, Portrait3D, to generate high-quality 3D heads while preserving their identities. Our work incorporates the identity information of the portrait image into three parts: 1) geometry initialization, 2) geometry sculpting, and 3) texture generation stages. Given a reference portrait image, we first align the identity features with text features to realize ID-aware guidance enhancement, which contains the control signals representing the face information. We then use the canny map, ID features of the portrait image, and a pre-trained text-to-normal/depth diffusion model to generate ID-aware geometry supervision, and 3D-GAN inversion is employed to generate ID-aware geometry initialization. Furthermore, with the ability to inject identity information into 3D head generation, we use ID-aware guidance to calculate ID-aware Score Distillation (ISD) for geometry sculpting. For texture generation, we adopt the ID Consistent Texture Inpainting and Refinement which progressively expands the view for texture inpainting to obtain an initialization UV texture map. We then use the id-aware guidance to provide image-level supervision for noisy multi-view images to obtain a refined texture map. Extensive experiments demonstrate that we can generate high-quality 3D heads with accurate geometry and texture from single in-the-wild portrait images. The project page is at https://jinkun-hao.github.io/Portrait3D/.
6/26/2024

HeadArtist: Text-conditioned 3D Head Generation with Self Score Distillation
Hongyu Liu, Xuan Wang, Ziyu Wan, Yujun Shen, Yibing Song, Jing Liao, Qifeng Chen
0
0
This work presents HeadArtist for 3D head generation from text descriptions. With a landmark-guided ControlNet serving as the generative prior, we come up with an efficient pipeline that optimizes a parameterized 3D head model under the supervision of the prior distillation itself. We call such a process self score distillation (SSD). In detail, given a sampled camera pose, we first render an image and its corresponding landmarks from the head model, and add some particular level of noise onto the image. The noisy image, landmarks, and text condition are then fed into the frozen ControlNet twice for noise prediction. Two different classifier-free guidance (CFG) weights are applied during these two predictions, and the prediction difference offers a direction on how the rendered image can better match the text of interest. Experimental results suggest that our approach delivers high-quality 3D head sculptures with adequate geometry and photorealistic appearance, significantly outperforming state-ofthe-art methods. We also show that the same pipeline well supports editing the generated heads, including both geometry deformation and appearance change.
5/9/2024

New!Dream-in-Style: Text-to-3D Generation using Stylized Score Distillation
Hubert Kompanowski, Binh-Son Hua
0
0
We present a method to generate 3D objects in styles. Our method takes a text prompt and a style reference image as input and reconstructs a neural radiance field to synthesize a 3D model with the content aligning with the text prompt and the style following the reference image. To simultaneously generate the 3D object and perform style transfer in one go, we propose a stylized score distillation loss to guide a text-to-3D optimization process to output visually plausible geometry and appearance. Our stylized score distillation is based on a combination of an original pretrained text-to-image model and its modified sibling with the key and value features of self-attention layers manipulated to inject styles from the reference image. Comparisons with state-of-the-art methods demonstrated the strong visual performance of our method, further supported by the quantitative results from our user study.
6/28/2024

VividDreamer: Towards High-Fidelity and Efficient Text-to-3D Generation
Zixuan Chen, Ruijie Su, Jiahao Zhu, Lingxiao Yang, Jian-Huang Lai, Xiaohua Xie
0
0
Text-to-3D generation aims to create 3D assets from text-to-image diffusion models. However, existing methods face an inherent bottleneck in generation quality because the widely-used objectives such as Score Distillation Sampling (SDS) inappropriately omit U-Net jacobians for swift generation, leading to significant bias compared to the true gradient obtained by full denoising sampling. This bias brings inconsistent updating direction, resulting in implausible 3D generation e.g., color deviation, Janus problem, and semantically inconsistent details). In this work, we propose Pose-dependent Consistency Distillation Sampling (PCDS), a novel yet efficient objective for diffusion-based 3D generation tasks. Specifically, PCDS builds the pose-dependent consistency function within diffusion trajectories, allowing to approximate true gradients through minimal sampling steps (1-3). Compared to SDS, PCDS can acquire a more accurate updating direction with the same sampling time (1 sampling step), while enabling few-step (2-3) sampling to trade compute for higher generation quality. For efficient generation, we propose a coarse-to-fine optimization strategy, which first utilizes 1-step PCDS to create the basic structure of 3D objects, and then gradually increases PCDS steps to generate fine-grained details. Extensive experiments demonstrate that our approach outperforms the state-of-the-art in generation quality and training efficiency, conspicuously alleviating the implausible 3D generation issues caused by the deviated updating direction. Moreover, it can be simply applied to many 3D generative applications to yield impressive 3D assets, please see our project page: https://narcissusex.github.io/VividDreamer.
6/24/2024