Portrait3D: 3D Head Generation from Single In-the-wild Portrait Image
2406.16710
0
0
Abstract
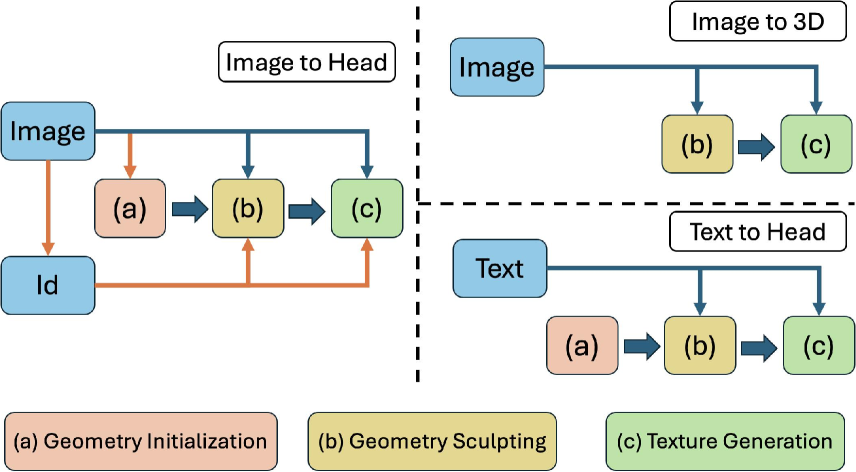
While recent works have achieved great success on one-shot 3D common object generation, high quality and fidelity 3D head generation from a single image remains a great challenge. Previous text-based methods for generating 3D heads were limited by text descriptions and image-based methods struggled to produce high-quality head geometry. To handle this challenging problem, we propose a novel framework, Portrait3D, to generate high-quality 3D heads while preserving their identities. Our work incorporates the identity information of the portrait image into three parts: 1) geometry initialization, 2) geometry sculpting, and 3) texture generation stages. Given a reference portrait image, we first align the identity features with text features to realize ID-aware guidance enhancement, which contains the control signals representing the face information. We then use the canny map, ID features of the portrait image, and a pre-trained text-to-normal/depth diffusion model to generate ID-aware geometry supervision, and 3D-GAN inversion is employed to generate ID-aware geometry initialization. Furthermore, with the ability to inject identity information into 3D head generation, we use ID-aware guidance to calculate ID-aware Score Distillation (ISD) for geometry sculpting. For texture generation, we adopt the ID Consistent Texture Inpainting and Refinement which progressively expands the view for texture inpainting to obtain an initialization UV texture map. We then use the id-aware guidance to provide image-level supervision for noisy multi-view images to obtain a refined texture map. Extensive experiments demonstrate that we can generate high-quality 3D heads with accurate geometry and texture from single in-the-wild portrait images. The project page is at https://jinkun-hao.github.io/Portrait3D/.
Create account to get full access
Overview
- This research paper presents a novel approach called "Portrait3D" for generating high-quality 3D head models from a single in-the-wild portrait image.
- The proposed method can produce realistic 3D head reconstructions without requiring complex multi-view or depth sensor inputs, making it practical for real-world applications.
- The key innovations include a learnable deformation module that can capture detailed facial features, and a rendering pipeline that generates photorealistic 3D outputs.
Plain English Explanation
The Portrait3D paper describes a new way to create 3D models of people's heads from just a single regular 2D photo. Normally, making 3D models requires special equipment like multiple cameras or depth sensors, but this new method can do it using only a single portrait image.
The researchers developed a system that can learn to capture all the fine details of a person's face, like the shape of their nose, eyes, and mouth, and then use that information to build a realistic 3D model of their head. This 3D model can then be rendered to look just like the original photo, but in 3D.
This is a significant advance because it makes 3D head modeling much more accessible and practical for real-world applications, where the ability to work with just a single photo is very useful. Instead of needing specialized hardware, this approach could allow anyone to create high-quality 3D portraits from their regular photos.
Technical Explanation
The Portrait3D method works by first using a convolutional neural network to extract a detailed feature representation from the input 2D portrait image. This feature representation captures the key details of the person's facial structure and appearance.
Next, the system uses a learnable deformation module to transform a generic 3D head model to match the specific features of the input face. This deformation process allows the 3D model to accurately capture the unique shape and details of the person's head.
Finally, a rendering pipeline is used to generate the final 3D output. This includes applying realistic textures, lighting, and other visual effects to make the 3D head model look photorealistic and closely match the input portrait.
The key innovations in this work are the learnable deformation module, which enables detailed 3D reconstruction from a single image, and the rendering pipeline, which produces high-quality 3D outputs. This contrasts with prior methods that required multiple views or depth sensors to achieve comparable 3D reconstruction quality.
Critical Analysis
The Portrait3D approach represents a significant advance in single-image 3D head modeling, but it does have some limitations.
While the method can produce highly realistic 3D reconstructions, it is currently constrained to just the head region and does not extend to the full body. Expanding the approach to handle the entire human form would be an important area for future research.
Additionally, the paper does not extensively explore the robustness of the method to variations in lighting, occlusions, or other real-world challenges that could impact performance in practical applications. Evaluating the system's ability to handle diverse in-the-wild portrait conditions would help assess its real-world viability.
Overall, the Portrait3D technique represents an exciting step forward in 3D facial modeling, and the authors' innovations in deformation and rendering could have broader impacts on the field of computer vision and graphics.
Conclusion
The Portrait3D research presents a novel method for generating high-quality 3D head models from a single 2D portrait image. By leveraging learnable deformation and realistic rendering, the approach can produce 3D reconstructions that closely match the input photo, without requiring specialized hardware or multiple views.
This advance makes 3D facial modeling much more accessible and practical for real-world applications, opening up new possibilities in areas like virtual avatars, face-based authentication, and mixed reality experiences. While the current work is limited to the head region, expanding the approach to handle full-body 3D reconstruction from single images could further broaden its impact.
Overall, the Portrait3D technique represents an important contribution to the field of computer vision and graphics, demonstrating the potential for AI-powered 3D reconstruction from 2D images.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Portrait3D: Text-Guided High-Quality 3D Portrait Generation Using Pyramid Representation and GANs Prior
Yiqian Wu, Hao Xu, Xiangjun Tang, Xien Chen, Siyu Tang, Zhebin Zhang, Chen Li, Xiaogang Jin
0
0
Existing neural rendering-based text-to-3D-portrait generation methods typically make use of human geometry prior and diffusion models to obtain guidance. However, relying solely on geometry information introduces issues such as the Janus problem, over-saturation, and over-smoothing. We present Portrait3D, a novel neural rendering-based framework with a novel joint geometry-appearance prior to achieve text-to-3D-portrait generation that overcomes the aforementioned issues. To accomplish this, we train a 3D portrait generator, 3DPortraitGAN-Pyramid, as a robust prior. This generator is capable of producing 360{deg} canonical 3D portraits, serving as a starting point for the subsequent diffusion-based generation process. To mitigate the grid-like artifact caused by the high-frequency information in the feature-map-based 3D representation commonly used by most 3D-aware GANs, we integrate a novel pyramid tri-grid 3D representation into 3DPortraitGAN-Pyramid. To generate 3D portraits from text, we first project a randomly generated image aligned with the given prompt into the pre-trained 3DPortraitGAN-Pyramid's latent space. The resulting latent code is then used to synthesize a pyramid tri-grid. Beginning with the obtained pyramid tri-grid, we use score distillation sampling to distill the diffusion model's knowledge into the pyramid tri-grid. Following that, we utilize the diffusion model to refine the rendered images of the 3D portrait and then use these refined images as training data to further optimize the pyramid tri-grid, effectively eliminating issues with unrealistic color and unnatural artifacts. Our experimental results show that Portrait3D can produce realistic, high-quality, and canonical 3D portraits that align with the prompt.
4/17/2024

Real-time 3D-aware Portrait Editing from a Single Image
Qingyan Bai, Zifan Shi, Yinghao Xu, Hao Ouyang, Qiuyu Wang, Ceyuan Yang, Xuan Wang, Gordon Wetzstein, Yujun Shen, Qifeng Chen
0
0
This work presents 3DPE, a practical method that can efficiently edit a face image following given prompts, like reference images or text descriptions, in a 3D-aware manner. To this end, a lightweight module is distilled from a 3D portrait generator and a text-to-image model, which provide prior knowledge of face geometry and superior editing capability, respectively. Such a design brings two compelling advantages over existing approaches. First, our system achieves real-time editing with a feedforward network (i.e., ~0.04s per image), over 100x faster than the second competitor. Second, thanks to the powerful priors, our module could focus on the learning of editing-related variations, such that it manages to handle various types of editing simultaneously in the training phase and further supports fast adaptation to user-specified customized types of editing during inference (e.g., with ~5min fine-tuning per style). The code, the model, and the interface will be made publicly available to facilitate future research.
4/3/2024

ID-to-3D: Expressive ID-guided 3D Heads via Score Distillation Sampling
Francesca Babiloni, Alexandros Lattas, Jiankang Deng, Stefanos Zafeiriou
0
0
We propose ID-to-3D, a method to generate identity- and text-guided 3D human heads with disentangled expressions, starting from even a single casually captured in-the-wild image of a subject. The foundation of our approach is anchored in compositionality, alongside the use of task-specific 2D diffusion models as priors for optimization. First, we extend a foundational model with a lightweight expression-aware and ID-aware architecture, and create 2D priors for geometry and texture generation, via fine-tuning only 0.2% of its available training parameters. Then, we jointly leverage a neural parametric representation for the expressions of each subject and a multi-stage generation of highly detailed geometry and albedo texture. This combination of strong face identity embeddings and our neural representation enables accurate reconstruction of not only facial features but also accessories and hair and can be meshed to provide render-ready assets for gaming and telepresence. Our results achieve an unprecedented level of identity-consistent and high-quality texture and geometry generation, generalizing to a ``world'' of unseen 3D identities, without relying on large 3D captured datasets of human assets.
5/29/2024

Unique3D: High-Quality and Efficient 3D Mesh Generation from a Single Image
Kailu Wu, Fangfu Liu, Zhihan Cai, Runjie Yan, Hanyang Wang, Yating Hu, Yueqi Duan, Kaisheng Ma
0
0
In this work, we introduce Unique3D, a novel image-to-3D framework for efficiently generating high-quality 3D meshes from single-view images, featuring state-of-the-art generation fidelity and strong generalizability. Previous methods based on Score Distillation Sampling (SDS) can produce diversified 3D results by distilling 3D knowledge from large 2D diffusion models, but they usually suffer from long per-case optimization time with inconsistent issues. Recent works address the problem and generate better 3D results either by finetuning a multi-view diffusion model or training a fast feed-forward model. However, they still lack intricate textures and complex geometries due to inconsistency and limited generated resolution. To simultaneously achieve high fidelity, consistency, and efficiency in single image-to-3D, we propose a novel framework Unique3D that includes a multi-view diffusion model with a corresponding normal diffusion model to generate multi-view images with their normal maps, a multi-level upscale process to progressively improve the resolution of generated orthographic multi-views, as well as an instant and consistent mesh reconstruction algorithm called ISOMER, which fully integrates the color and geometric priors into mesh results. Extensive experiments demonstrate that our Unique3D significantly outperforms other image-to-3D baselines in terms of geometric and textural details.
6/14/2024