iDRAMA-Scored-2024: A Dataset of the Scored Social Media Platform from 2020 to 2023
2405.10233
0
0
Abstract
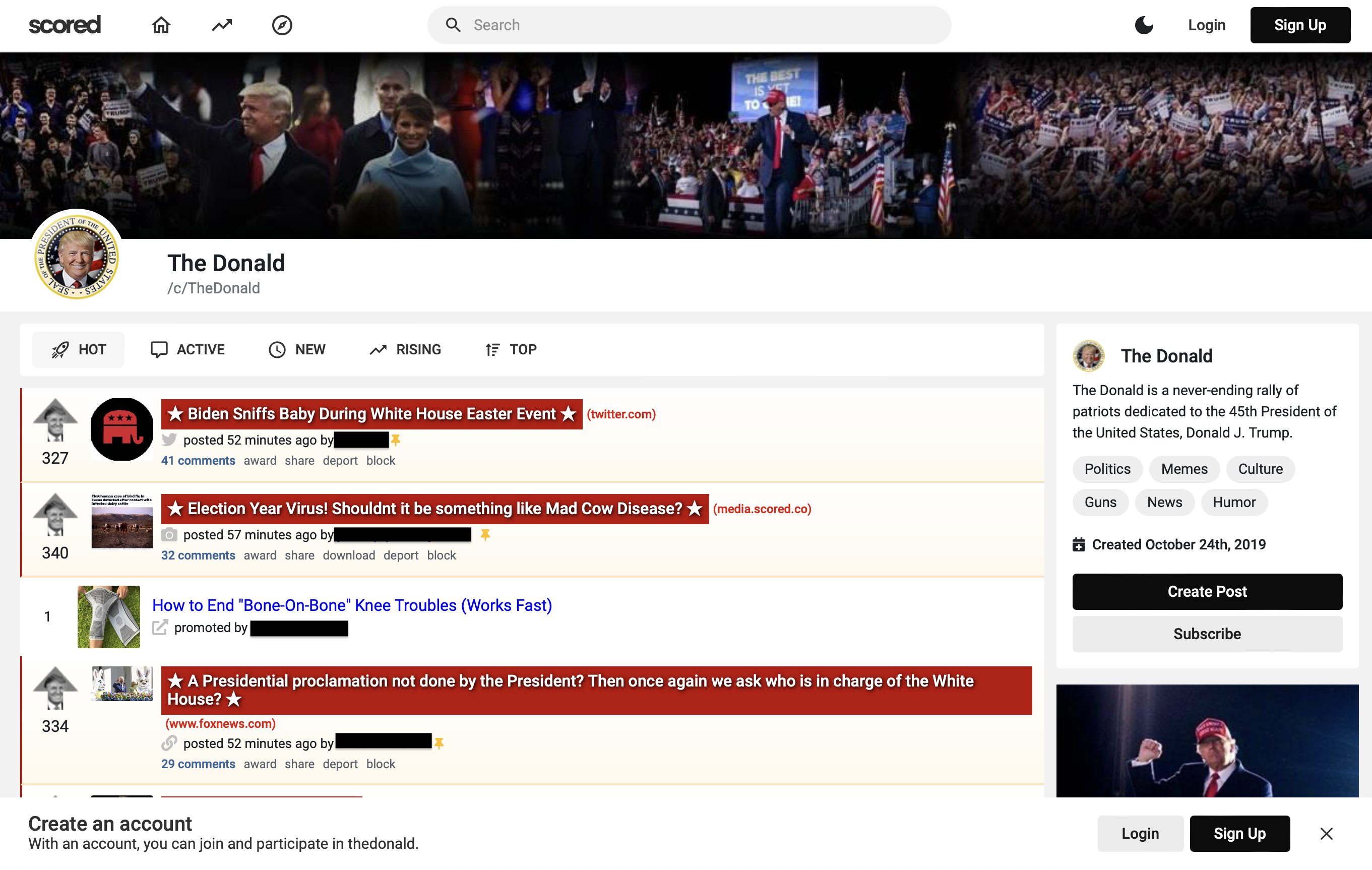
Online web communities often face bans for violating platform policies, encouraging their migration to alternative platforms. This migration, however, can result in increased toxicity and unforeseen consequences on the new platform. In recent years, researchers have collected data from many alternative platforms, indicating coordinated efforts leading to offline events, conspiracy movements, hate speech propagation, and harassment. Thus, it becomes crucial to characterize and understand these alternative platforms. To advance research in this direction, we collect and release a large-scale dataset from Scored -- an alternative Reddit platform that sheltered banned fringe communities, for example, c/TheDonald (a prominent right-wing community) and c/GreatAwakening (a conspiratorial community). Over four years, we collected approximately 57M posts from Scored, with at least 58 communities identified as migrating from Reddit and over 950 communities created since the platform's inception. Furthermore, we provide sentence embeddings of all posts in our dataset, generated through a state-of-the-art model, to further advance the field in characterizing the discussions within these communities. We aim to provide these resources to facilitate their investigations without the need for extensive data collection and processing efforts.
Create account to get full access
Overview
- This paper introduces a new dataset called iDRAMA-Scored-2024, which contains data from a social media platform called iDRAMA from 2020 to 2023.
- The dataset includes user engagement metrics, textual content, and annotations of the posts.
- The authors aim to provide a resource for researchers to study the evolution of online discourse and user behavior over time.
Plain English Explanation
The researchers have created a new dataset that contains information from a social media platform called iDRAMA over a 4-year period, from 2020 to 2023. This dataset includes details about how users interacted with the platform, the content they posted, and annotations or labels applied to the posts.
The goal of this dataset is to give researchers a valuable resource to study how online discussions and user behavior on this platform changed over time. By having access to this data, researchers can analyze trends, identify patterns, and gain insights into the evolution of digital discourse. This could lead to a better understanding of how people communicate and engage with each other on social media.
The dataset could be particularly useful for researchers interested in examining the impacts of online communities, analyzing the use and misuse of addiction-related content, or exploring the effectiveness of different moderation strategies.
Technical Explanation
The iDRAMA-Scored-2024 dataset contains data from the iDRAMA social media platform between 2020 and 2023. The dataset includes:
- User engagement metrics, such as likes, shares, and comments
- The full text of all posts made during this period
- Annotations or "scores" applied to each post, which could indicate the level of toxicity, sentiment, or other attributes
The dataset was created by the researchers by scraping the iDRAMA platform and collecting this data over the 4-year time frame. They then processed and organized the information into a structured format for researchers to access and analyze.
The key features of this dataset are its longitudinal nature, covering multiple years, and the inclusion of both engagement data and content annotations. This allows researchers to study the evolution of online discourse and investigate how user behavior and interactions change over time.
Critical Analysis
The iDRAMA-Scored-2024 dataset provides a valuable resource for researchers, but it is important to consider some potential limitations and areas for further research:
- The dataset is limited to a single social media platform, so the findings may not be generalizable to other online communities.
- The accuracy and reliability of the post annotations or "scores" may be questionable, as the criteria and methods used to generate them are not fully explained.
- There could be biases or gaps in the data, as the researchers had to rely on the platform's APIs and policies to collect the information.
Future research could explore ways to validate the dataset's annotations, compare the findings to other social media platforms, or investigate the potential impacts of data collection and annotation methods on the research insights.
Conclusion
The iDRAMA-Scored-2024 dataset offers a unique opportunity for researchers to study the evolution of online discourse and user behavior over a 4-year period. By providing access to longitudinal data on user engagement, content, and annotations, the dataset has the potential to generate valuable insights that could inform the design of healthier and more inclusive social media platforms. However, it is important to consider the dataset's limitations and potential biases when interpreting the findings.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
I'm in the Bluesky Tonight: Insights from a Year Worth of Social Data
Andrea Failla, Giulio Rossetti
0
0
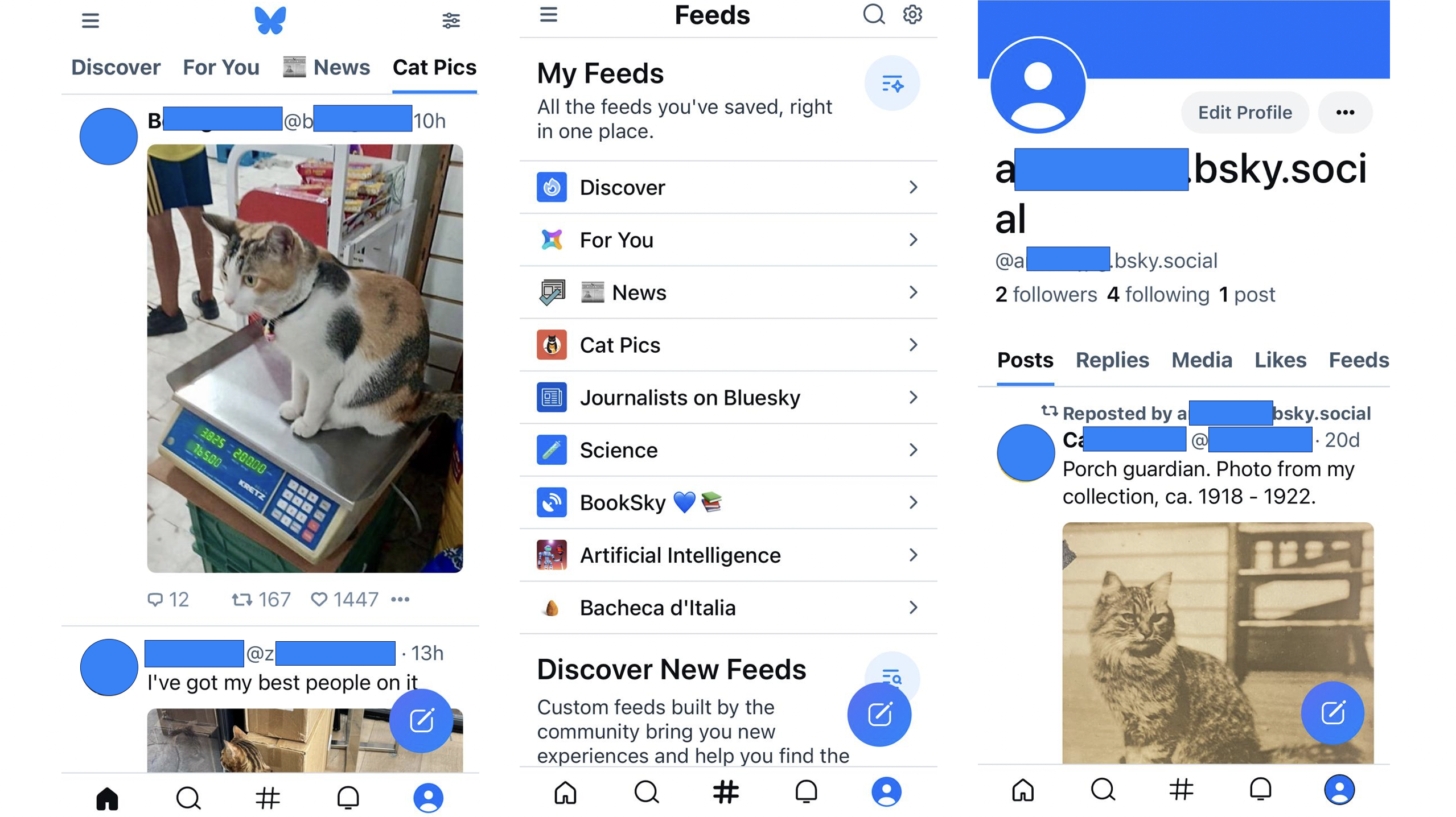
Pollution of online social spaces caused by rampaging d/misinformation is a growing societal concern. However, recent decisions to reduce access to social media APIs are causing a shortage of publicly available, recent, social media data, thus hindering the advancement of computational social science as a whole. We present a large, high-coverage dataset of social interactions and user-generated content from Bluesky Social to address this pressing issue. The dataset contains the complete post history of over 4M users (81% of all registered accounts), totalling 235M posts. We also make available social data covering follow, comment, repost, and quote interactions. Since Bluesky allows users to create and bookmark feed generators (i.e., content recommendation algorithms), we also release the full output of several popular algorithms available on the platform, along with their timestamped ``like'' interactions and time of bookmarking. This dataset allows unprecedented analysis of online behavior and human-machine engagement patterns. Notably, it provides ground-truth data for studying the effects of content exposure and self-selection and performing content virality and diffusion analysis.
5/1/2024
Analyzing Toxicity in Deep Conversations: A Reddit Case Study
Vigneshwaran Shankaran, Rajesh Sharma
0
0
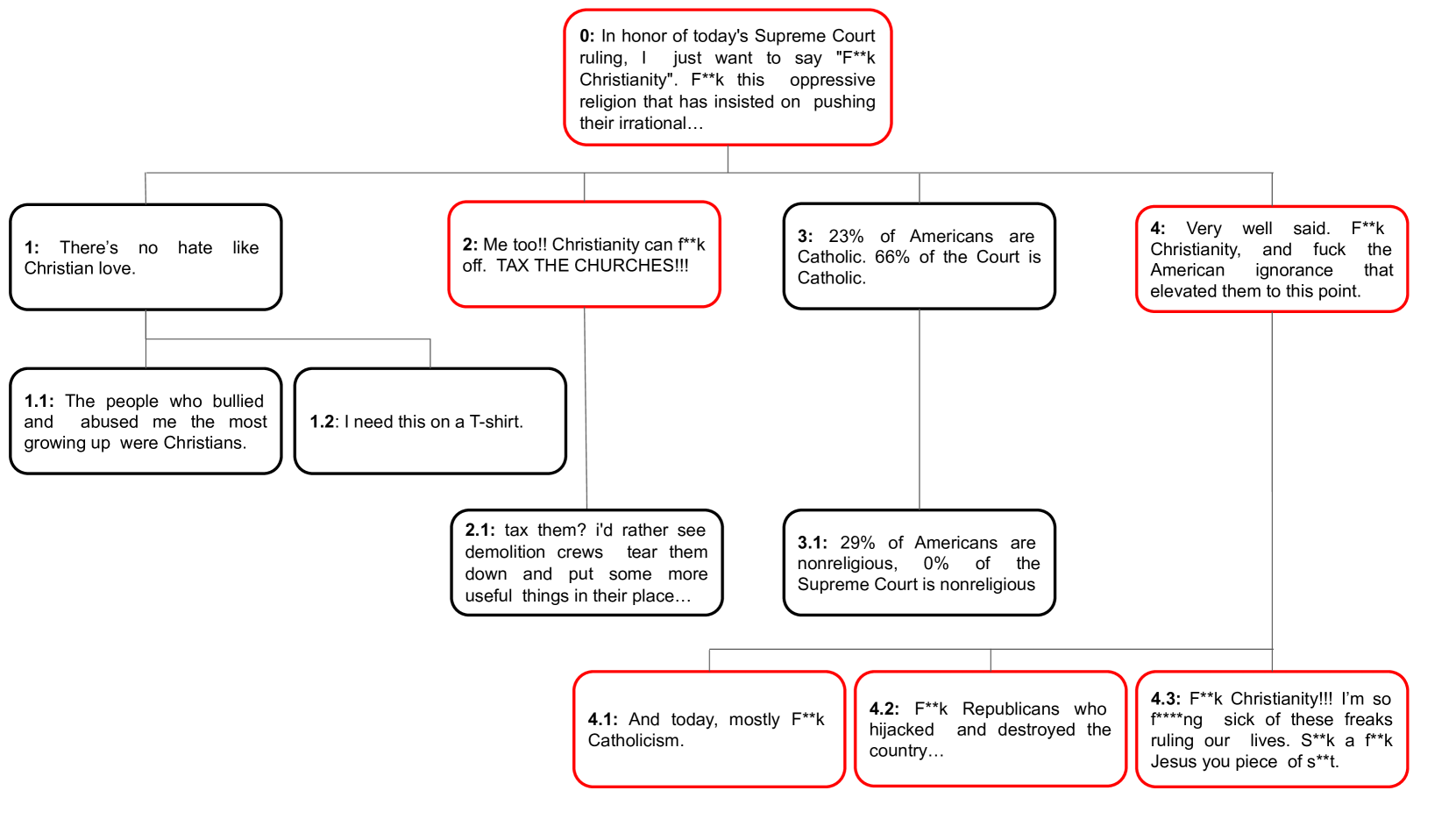
Online social media has become increasingly popular in recent years due to its ease of access and ability to connect with others. One of social media's main draws is its anonymity, allowing users to share their thoughts and opinions without fear of judgment or retribution. This anonymity has also made social media prone to harmful content, which requires moderation to ensure responsible and productive use. Several methods using artificial intelligence have been employed to detect harmful content. However, conversation and contextual analysis of hate speech are still understudied. Most promising works only analyze a single text at a time rather than the conversation supporting it. In this work, we employ a tree-based approach to understand how users behave concerning toxicity in public conversation settings. To this end, we collect both the posts and the comment sections of the top 100 posts from 8 Reddit communities that allow profanity, totaling over 1 million responses. We find that toxic comments increase the likelihood of subsequent toxic comments being produced in online conversations. Our analysis also shows that immediate context plays a vital role in shaping a response rather than the original post. We also study the effect of consensual profanity and observe overlapping similarities with non-consensual profanity in terms of user behavior and patterns.
4/12/2024

Reddit-Impacts: A Named Entity Recognition Dataset for Analyzing Clinical and Social Effects of Substance Use Derived from Social Media
Yao Ge, Sudeshna Das, Karen O'Connor, Mohammed Ali Al-Garadi, Graciela Gonzalez-Hernandez, Abeed Sarker
0
0
Substance use disorders (SUDs) are a growing concern globally, necessitating enhanced understanding of the problem and its trends through data-driven research. Social media are unique and important sources of information about SUDs, particularly since the data in such sources are often generated by people with lived experiences. In this paper, we introduce Reddit-Impacts, a challenging Named Entity Recognition (NER) dataset curated from subreddits dedicated to discussions on prescription and illicit opioids, as well as medications for opioid use disorder. The dataset specifically concentrates on the lesser-studied, yet critically important, aspects of substance use--its clinical and social impacts. We collected data from chosen subreddits using the publicly available Application Programming Interface for Reddit. We manually annotated text spans representing clinical and social impacts reported by people who also reported personal nonmedical use of substances including but not limited to opioids, stimulants and benzodiazepines. Our objective is to create a resource that can enable the development of systems that can automatically detect clinical and social impacts of substance use from text-based social media data. The successful development of such systems may enable us to better understand how nonmedical use of substances affects individual health and societal dynamics, aiding the development of effective public health strategies. In addition to creating the annotated data set, we applied several machine learning models to establish baseline performances. Specifically, we experimented with transformer models like BERT, and RoBERTa, one few-shot learning model DANN by leveraging the full training dataset, and GPT-3.5 by using one-shot learning, for automatic NER of clinical and social impacts. The dataset has been made available through the 2024 SMM4H shared tasks.
5/13/2024
IndoToxic2024: A Demographically-Enriched Dataset of Hate Speech and Toxicity Types for Indonesian Language
Lucky Susanto, Musa Izzanardi Wijanarko, Prasetia Anugrah Pratama, Traci Hong, Ika Idris, Alham Fikri Aji, Derry Wijaya
0
0
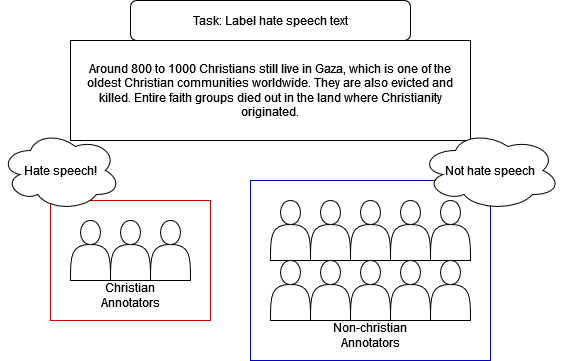
Hate speech poses a significant threat to social harmony. Over the past two years, Indonesia has seen a ten-fold increase in the online hate speech ratio, underscoring the urgent need for effective detection mechanisms. However, progress is hindered by the limited availability of labeled data for Indonesian texts. The condition is even worse for marginalized minorities, such as Shia, LGBTQ, and other ethnic minorities because hate speech is underreported and less understood by detection tools. Furthermore, the lack of accommodation for subjectivity in current datasets compounds this issue. To address this, we introduce IndoToxic2024, a comprehensive Indonesian hate speech and toxicity classification dataset. Comprising 43,692 entries annotated by 19 diverse individuals, the dataset focuses on texts targeting vulnerable groups in Indonesia, specifically during the hottest political event in the country: the presidential election. We establish baselines for seven binary classification tasks, achieving a macro-F1 score of 0.78 with a BERT model (IndoBERTweet) fine-tuned for hate speech classification. Furthermore, we demonstrate how incorporating demographic information can enhance the zero-shot performance of the large language model, gpt-3.5-turbo. However, we also caution that an overemphasis on demographic information can negatively impact the fine-tuned model performance due to data fragmentation.
6/28/2024