Analyzing Toxicity in Deep Conversations: A Reddit Case Study
2404.07879
0
0
Abstract
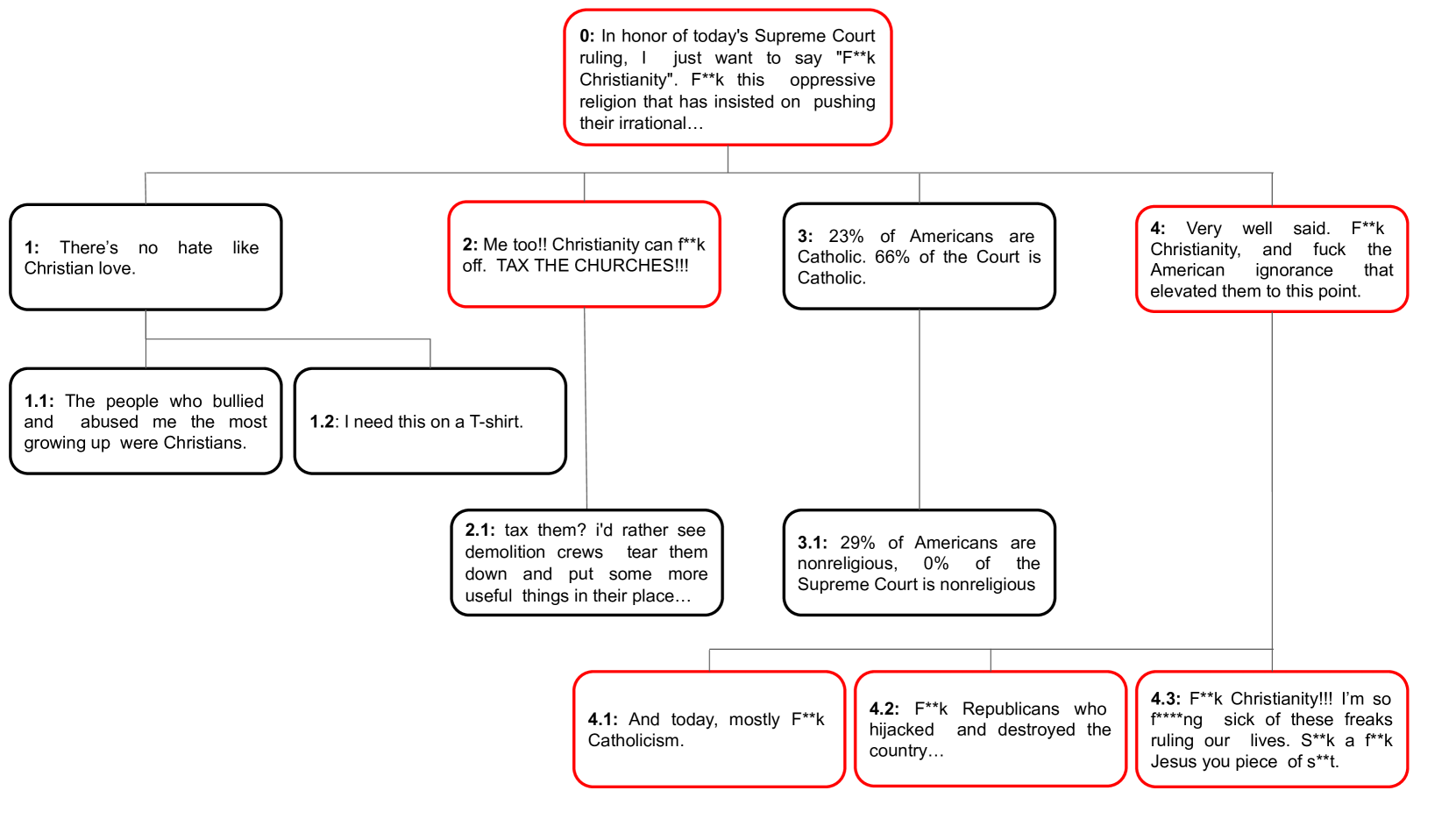
Online social media has become increasingly popular in recent years due to its ease of access and ability to connect with others. One of social media's main draws is its anonymity, allowing users to share their thoughts and opinions without fear of judgment or retribution. This anonymity has also made social media prone to harmful content, which requires moderation to ensure responsible and productive use. Several methods using artificial intelligence have been employed to detect harmful content. However, conversation and contextual analysis of hate speech are still understudied. Most promising works only analyze a single text at a time rather than the conversation supporting it. In this work, we employ a tree-based approach to understand how users behave concerning toxicity in public conversation settings. To this end, we collect both the posts and the comment sections of the top 100 posts from 8 Reddit communities that allow profanity, totaling over 1 million responses. We find that toxic comments increase the likelihood of subsequent toxic comments being produced in online conversations. Our analysis also shows that immediate context plays a vital role in shaping a response rather than the original post. We also study the effect of consensual profanity and observe overlapping similarities with non-consensual profanity in terms of user behavior and patterns.
Create account to get full access
Overview
- This paper explores the problem of detecting and mitigating toxicity in online conversations, using a case study of the Reddit platform.
- The researchers analyzed a large dataset of Reddit comments to understand the dynamics of toxic behavior and develop methods for identifying and addressing it.
- The findings provide insights into the complex nature of online toxicity and offer potential strategies for creating healthier, more inclusive online communities.
Plain English Explanation
The paper examines the issue of toxicity, or harmful and abusive language, that can arise in online discussions. The researchers focused on Reddit, a popular online forum, to better understand how and why this type of behavior occurs.
By analyzing a large dataset of comments from Reddit, the researchers were able to identify patterns and characteristics of toxic conversations. This helped them develop methods for automatically detecting when conversations are becoming toxic and potentially intervening to mitigate the harm.
The findings highlight the complex nature of online toxicity, which can be influenced by factors like the tone and structure of the conversation, the relationships between participants, and broader social and cultural dynamics. The researchers suggest that addressing this problem will require a multifaceted approach, including technical solutions as well as community-based strategies to foster more respectful and inclusive online discourse.
Overall, this research provides valuable insights into an important and challenging issue facing many online communities, and offers potential pathways for creating safer and more positive digital spaces.
Technical Explanation
The researchers collected a large dataset of comments from the Reddit platform, which included information about the text of the comments, the users who posted them, and the structure of the conversations. They then used machine learning techniques to analyze the dataset and identify patterns related to toxic behavior.
The key components of their approach included:
- Feature extraction: The researchers extracted various features from the comment text and conversation context, such as sentiment, linguistic complexity, and network structure.
- Toxicity classification: They trained a deep learning model to classify comments as toxic or non-toxic, using the extracted features as inputs.
- Conversation analysis: By tracking how toxicity spreads through conversations, the researchers were able to develop strategies for detecting and mitigating toxic exchanges.
The findings revealed insights into the dynamics of online toxicity, such as the role of social network structure and the linguistic characteristics of toxic language. The researchers also explored the potential for automated interventions to disrupt the spread of toxicity and foster more constructive conversations.
Critical Analysis
The paper provides a comprehensive and rigorous analysis of online toxicity, but it also acknowledges several limitations and areas for further research.
One potential concern is the reliance on user-reported toxicity labels, which may not capture the full complexity of how people perceive and experience harmful behavior in online discussions. The researchers note that developing more nuanced and context-aware toxicity detection models could be an important area for future work.
Additionally, while the paper explores strategies for automated intervention, it does not delve deeply into the potential unintended consequences or ethical implications of such approaches. Ensuring that any moderation efforts are equitable, transparent, and respectful of user privacy will be a critical consideration as this technology is further developed and deployed.
Overall, the study makes a valuable contribution to our understanding of online toxicity and offers promising directions for creating healthier, more inclusive digital communities. However, continued research and careful consideration of the societal impacts will be needed to fully address this complex and multifaceted challenge.
Conclusion
This paper provides a comprehensive analysis of toxicity in online conversations, using Reddit as a case study. The researchers developed methods for automatically detecting and mitigating the spread of toxic behavior, drawing on insights about the social and linguistic characteristics of toxic exchanges.
The findings highlight the complex nature of online toxicity and the need for a multi-pronged approach to address it, including technical solutions, community-based strategies, and careful consideration of the ethical implications. As digital spaces become increasingly central to our social and civic lives, this research provides important insights for creating safer and more inclusive online communities.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
The Constant in HATE: Analyzing Toxicity in Reddit across Topics and Languages
Wondimagegnhue Tsegaye Tufa, Ilia Markov, Piek Vossen
0
0
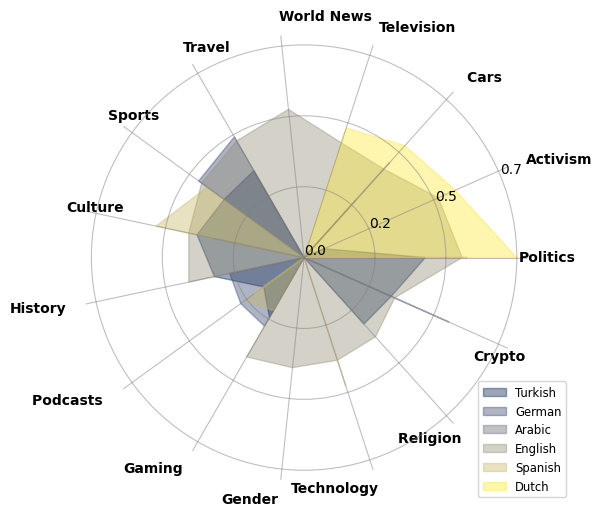
Toxic language remains an ongoing challenge on social media platforms, presenting significant issues for users and communities. This paper provides a cross-topic and cross-lingual analysis of toxicity in Reddit conversations. We collect 1.5 million comment threads from 481 communities in six languages: English, German, Spanish, Turkish,Arabic, and Dutch, covering 80 topics such as Culture, Politics, and News. We thoroughly analyze how toxicity spikes within different communities in relation to specific topics. We observe consistent patterns of increased toxicity across languages for certain topics, while also noting significant variations within specific language communities.
4/30/2024
🛠️
Grounding Toxicity in Real-World Events across Languages
Wondimagegnhue Tsegaye Tufa, Ilia Markov, Piek Vossen
0
0
Social media conversations frequently suffer from toxicity, creating significant issues for users, moderators, and entire communities. Events in the real world, like elections or conflicts, can initiate and escalate toxic behavior online. Our study investigates how real-world events influence the origin and spread of toxicity in online discussions across various languages and regions. We gathered Reddit data comprising 4.5 million comments from 31 thousand posts in six different languages (Dutch, English, German, Arabic, Turkish and Spanish). We target fifteen major social and political world events that occurred between 2020 and 2023. We observe significant variations in toxicity, negative sentiment, and emotion expressions across different events and language communities, showing that toxicity is a complex phenomenon in which many different factors interact and still need to be investigated. We will release the data for further research along with our code.
5/24/2024

Toxic Memes: A Survey of Computational Perspectives on the Detection and Explanation of Meme Toxicities
Delfina Sol Martinez Pandiani, Erik Tjong Kim Sang, Davide Ceolin
0
0
Internet memes, channels for humor, social commentary, and cultural expression, are increasingly used to spread toxic messages. Studies on the computational analyses of toxic memes have significantly grown over the past five years, and the only three surveys on computational toxic meme analysis cover only work published until 2022, leading to inconsistent terminology and unexplored trends. Our work fills this gap by surveying content-based computational perspectives on toxic memes, and reviewing key developments until early 2024. Employing the PRISMA methodology, we systematically extend the previously considered papers, achieving a threefold result. First, we survey 119 new papers, analyzing 158 computational works focused on content-based toxic meme analysis. We identify over 30 datasets used in toxic meme analysis and examine their labeling systems. Second, after observing the existence of unclear definitions of meme toxicity in computational works, we introduce a new taxonomy for categorizing meme toxicity types. We also note an expansion in computational tasks beyond the simple binary classification of memes as toxic or non-toxic, indicating a shift towards achieving a nuanced comprehension of toxicity. Third, we identify three content-based dimensions of meme toxicity under automatic study: target, intent, and conveyance tactics. We develop a framework illustrating the relationships between these dimensions and meme toxicities. The survey analyzes key challenges and recent trends, such as enhanced cross-modal reasoning, integrating expert and cultural knowledge, the demand for automatic toxicity explanations, and handling meme toxicity in low-resource languages. Also, it notes the rising use of Large Language Models (LLMs) and generative AI for detecting and generating toxic memes. Finally, it proposes pathways for advancing toxic meme detection and interpretation.
6/12/2024
iDRAMA-Scored-2024: A Dataset of the Scored Social Media Platform from 2020 to 2023
Jay Patel, Pujan Paudel, Emiliano De Cristofaro, Gianluca Stringhini, Jeremy Blackburn
0
0
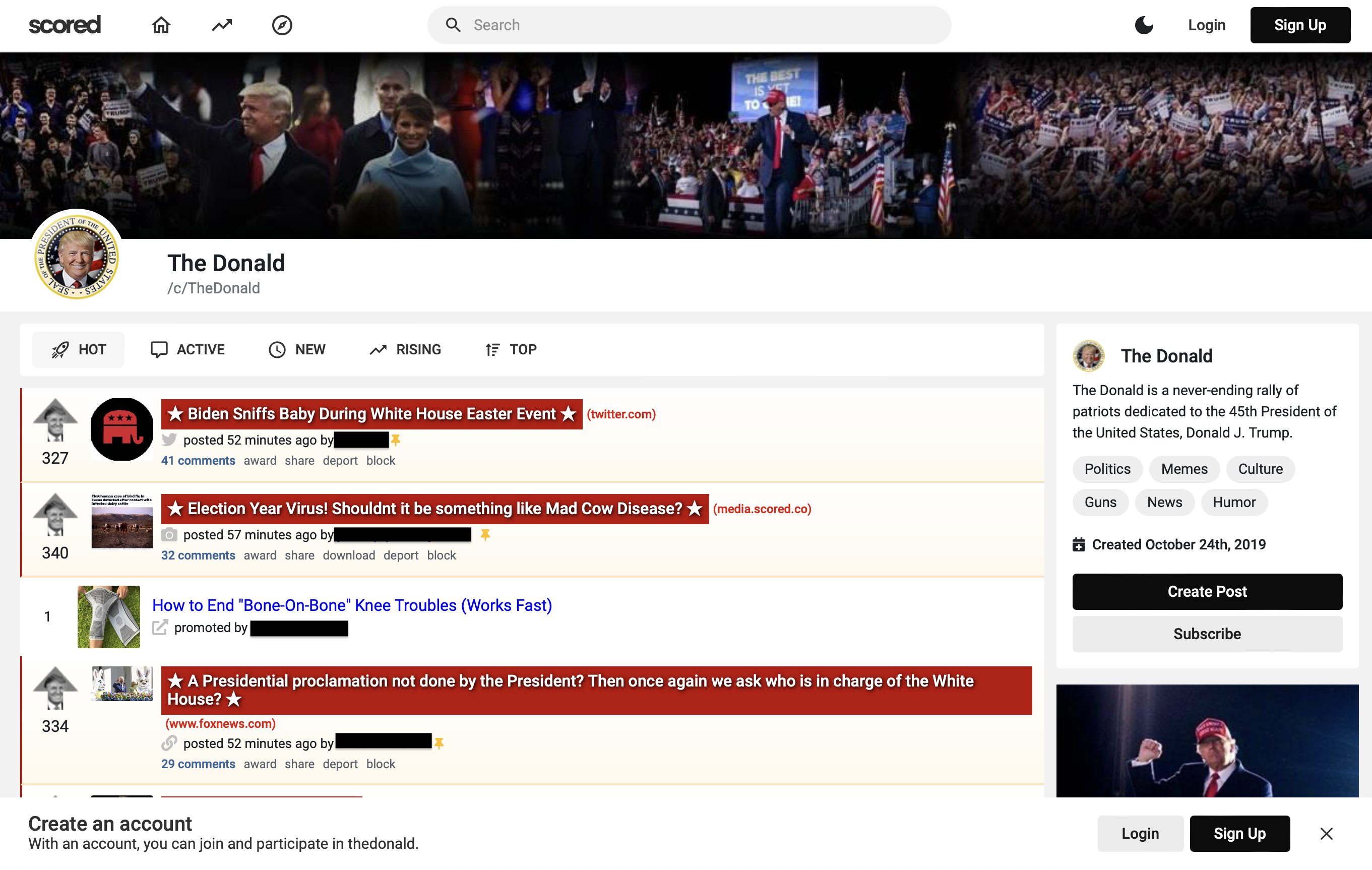
Online web communities often face bans for violating platform policies, encouraging their migration to alternative platforms. This migration, however, can result in increased toxicity and unforeseen consequences on the new platform. In recent years, researchers have collected data from many alternative platforms, indicating coordinated efforts leading to offline events, conspiracy movements, hate speech propagation, and harassment. Thus, it becomes crucial to characterize and understand these alternative platforms. To advance research in this direction, we collect and release a large-scale dataset from Scored -- an alternative Reddit platform that sheltered banned fringe communities, for example, c/TheDonald (a prominent right-wing community) and c/GreatAwakening (a conspiratorial community). Over four years, we collected approximately 57M posts from Scored, with at least 58 communities identified as migrating from Reddit and over 950 communities created since the platform's inception. Furthermore, we provide sentence embeddings of all posts in our dataset, generated through a state-of-the-art model, to further advance the field in characterizing the discussions within these communities. We aim to provide these resources to facilitate their investigations without the need for extensive data collection and processing efforts.
5/17/2024