Imbalanced Graph-Level Anomaly Detection via Counterfactual Augmentation and Feature Learning

0

Sign in to get full access
Overview
- This paper presents a new approach for detecting anomalies in graph-structured data, which is a challenging problem due to the imbalanced nature of anomalies in real-world graphs.
- The proposed method, called GLAD (Imbalanced Graph-Level Anomaly Detection), uses counterfactual augmentation and feature learning to improve the performance of graph neural networks in detecting anomalies.
- The key innovations include a counterfactual augmentation technique to generate diverse positive samples, and a feature learning module that learns discriminative features for anomaly detection.
Plain English Explanation
In this paper, the researchers tackle the problem of detecting anomalies, or unusual patterns, in graph-structured data. Graphs are a way of representing relationships between different entities, like people in a social network or components in a computer system. Detecting anomalies in graphs is important for applications like fraud detection, cybersecurity, and network monitoring.
One of the main challenges is that anomalies are relatively rare compared to normal patterns in real-world graphs. This imbalance makes it difficult for machine learning models to learn to identify the anomalies effectively. To address this, the researchers developed a new approach called GLAD (Imbalanced Graph-Level Anomaly Detection).
The key ideas behind GLAD are:
-
Counterfactual Augmentation: The researchers use a technique called counterfactual augmentation to generate new "what-if" samples that are similar to the existing normal samples but slightly different. This helps the model learn a more robust representation of normal patterns, making it better able to identify anomalies.
-
Feature Learning: GLAD also includes a module that learns discriminative features specifically for the task of anomaly detection. This helps the model focus on the most important characteristics that distinguish normal and anomalous graphs.
By combining these two innovations, GLAD is able to outperform existing graph anomaly detection methods, especially in scenarios where the anomalies are rare and hard to detect.
Technical Explanation
The paper introduces the GLAD (Imbalanced Graph-Level Anomaly Detection) framework, which addresses the challenge of imbalanced graph-level anomaly detection.
The key components of GLAD are:
-
Counterfactual Augmentation: To address the imbalance between normal and anomalous graphs, GLAD uses a counterfactual augmentation technique to generate diverse positive (normal) samples. This is done by perturbing the features and structure of existing normal graphs in a controlled way, creating "what-if" scenarios that are still considered normal.
-
Feature Learning: GLAD includes a feature learning module that learns discriminative features for the anomaly detection task. This helps the model focus on the most relevant characteristics that distinguish normal and anomalous graphs, rather than relying on generic graph features.
-
Anomaly Detection: The GLAD framework uses a graph neural network to learn representations of the input graphs. These representations are then used to classify each graph as either normal or anomalous.
The authors evaluate GLAD on several real-world graph datasets and show that it outperforms state-of-the-art graph anomaly detection methods, especially in scenarios with highly imbalanced data. The counterfactual augmentation and feature learning components are key to GLAD's superior performance.
Critical Analysis
The paper presents a well-designed and thoughtful approach to the challenging problem of imbalanced graph-level anomaly detection. The use of counterfactual augmentation to generate diverse positive samples is a clever strategy to address the data imbalance, and the feature learning module is an important innovation that helps the model focus on the most discriminative characteristics.
One potential limitation of the research is that it relies on the availability of labeled graph data for training, which can be difficult to obtain in real-world scenarios. The authors mention that extending GLAD to semi-supervised or unsupervised settings could be an interesting direction for future work.
Additionally, the paper does not provide much discussion on the computational complexity or scalability of the GLAD framework, which could be important considerations for practical applications of the method. Evaluating the performance of GLAD on larger and more diverse graph datasets could also help validate the generalizability of the approach.
Overall, the GLAD framework represents a significant contribution to the field of graph anomaly detection, and the ideas presented in the paper could inspire further advancements in this important area of research.
Conclusion
This paper introduces the GLAD (Imbalanced Graph-Level Anomaly Detection) framework, which addresses the challenge of detecting anomalies in graph-structured data. GLAD uses a combination of counterfactual augmentation and feature learning to improve the performance of graph neural networks in this task, especially in scenarios with highly imbalanced data.
The key innovations of GLAD, including the counterfactual augmentation technique and the feature learning module, have been shown to outperform state-of-the-art graph anomaly detection methods. This work represents an important step forward in the field of graph anomaly detection, with potential applications in areas like fraud detection, cybersecurity, and network monitoring.
While the paper has some limitations, such as the reliance on labeled data and the lack of discussion on computational complexity, the ideas presented are compelling and could inspire further research to address these challenges. Overall, the GLAD framework is a valuable contribution to the field of graph-based anomaly detection.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Imbalanced Graph-Level Anomaly Detection via Counterfactual Augmentation and Feature Learning
Zitong Wang, Xuexiong Luo, Enfeng Song, Qiuqing Bai, Fu Lin
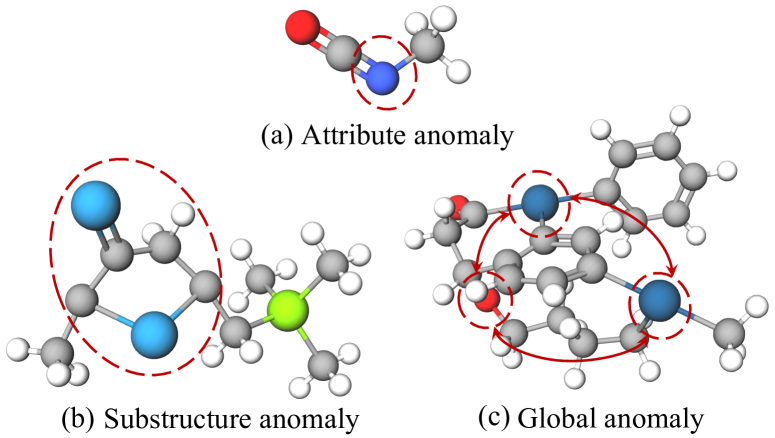
Graph-level anomaly detection (GLAD) has already gained significant importance and has become a popular field of study, attracting considerable attention across numerous downstream works. The core focus of this domain is to capture and highlight the anomalous information within given graph datasets. In most existing studies, anomalies are often the instances of few. The stark imbalance misleads current GLAD methods to focus on learning the patterns of normal graphs more, further impacting anomaly detection performance. Moreover, existing methods predominantly utilize the inherent features of nodes to identify anomalous graph patterns which is approved suboptimal according to our experiments. In this work, we propose an imbalanced GLAD method via counterfactual augmentation and feature learning. Specifically, we first construct anomalous samples based on counterfactual learning, aiming to expand and balance the datasets. Additionally, we construct a module based on Graph Neural Networks (GNNs), which allows us to utilize degree attributes to complement the inherent attribute features of nodes. Then, we design an adaptive weight learning module to integrate features tailored to different datasets effectively to avoid indiscriminately treating all features as equivalent. Furthermore, extensive baseline experiments conducted on public datasets substantiate the robustness and effectiveness. Besides, we apply the model to brain disease datasets, which can prove the generalization capability of our work. The source code of our work is available online.
Read more7/17/2024
0
GLADformer: A Mixed Perspective for Graph-level Anomaly Detection
Fan Xu, Nan Wang, Hao Wu, Xuezhi Wen, Dalin Zhang, Siyang Lu, Binyong Li, Wei Gong, Hai Wan, Xibin Zhao
Graph-Level Anomaly Detection (GLAD) aims to distinguish anomalous graphs within a graph dataset. However, current methods are constrained by their receptive fields, struggling to learn global features within the graphs. Moreover, most contemporary methods are based on spatial domain and lack exploration of spectral characteristics. In this paper, we propose a multi-perspective hybrid graph-level anomaly detector namely GLADformer, consisting of two key modules. Specifically, we first design a Graph Transformer module with global spectrum enhancement, which ensures balanced and resilient parameter distributions by fusing global features and spectral distribution characteristics. Furthermore, to uncover local anomalous attributes, we customize a band-pass spectral GNN message passing module that further enhances the model's generalization capability. Through comprehensive experiments on ten real-world datasets from multiple domains, we validate the effectiveness and robustness of GLADformer. This demonstrates that GLADformer outperforms current state-of-the-art models in graph-level anomaly detection, particularly in effectively capturing global anomaly representations and spectral characteristics.
Read more7/4/2024
🧠
0
Guarding Graph Neural Networks for Unsupervised Graph Anomaly Detection
Yuanchen Bei, Sheng Zhou, Jinke Shi, Yao Ma, Haishuai Wang, Jiajun Bu
Unsupervised graph anomaly detection aims at identifying rare patterns that deviate from the majority in a graph without the aid of labels, which is important for a variety of real-world applications. Recent advances have utilized Graph Neural Networks (GNNs) to learn effective node representations by aggregating information from neighborhoods. This is motivated by the hypothesis that nodes in the graph tend to exhibit consistent behaviors with their neighborhoods. However, such consistency can be disrupted by graph anomalies in multiple ways. Most existing methods directly employ GNNs to learn representations, disregarding the negative impact of graph anomalies on GNNs, resulting in sub-optimal node representations and anomaly detection performance. While a few recent approaches have redesigned GNNs for graph anomaly detection under semi-supervised label guidance, how to address the adverse effects of graph anomalies on GNNs in unsupervised scenarios and learn effective representations for anomaly detection are still under-explored. To bridge this gap, in this paper, we propose a simple yet effective framework for Guarding Graph Neural Networks for Unsupervised Graph Anomaly Detection (G3AD). Specifically, G3AD introduces two auxiliary networks along with correlation constraints to guard the GNNs from inconsistent information encoding. Furthermore, G3AD introduces an adaptive caching module to guard the GNNs from solely reconstructing the observed data that contains anomalies. Extensive experiments demonstrate that our proposed G3AD can outperform seventeen state-of-the-art methods on both synthetic and real-world datasets.
Read more4/26/2024
❗
0
Towards Fair Graph Anomaly Detection: Problem, Benchmark Datasets, and Evaluation
Neng Kai Nigel Neo, Yeon-Chang Lee, Yiqiao Jin, Sang-Wook Kim, Srijan Kumar
The Fair Graph Anomaly Detection (FairGAD) problem aims to accurately detect anomalous nodes in an input graph while avoiding biased predictions against individuals from sensitive subgroups. However, the current literature does not comprehensively discuss this problem, nor does it provide realistic datasets that encompass actual graph structures, anomaly labels, and sensitive attributes. To bridge this gap, we introduce a formal definition of the FairGAD problem and present two novel datasets constructed from the social media platforms Reddit and Twitter. These datasets comprise 1.2 million and 400,000 edges associated with 9,000 and 47,000 nodes, respectively, and leverage political leanings as sensitive attributes and misinformation spreaders as anomaly labels. We demonstrate that our FairGAD datasets significantly differ from the synthetic datasets used by the research community. Using our datasets, we investigate the performance-fairness trade-off in nine existing GAD and non-graph AD methods on five state-of-the-art fairness methods. Our code and datasets are available at https://github.com/nigelnnk/FairGAD
Read more7/30/2024