Implementing engrams from a machine learning perspective: the relevance of a latent space

0

Sign in to get full access
Overview
- Exploring the use of machine learning, specifically autoencoders, to model the concept of engrams - the neural representations of memories.
- Highlights the relevance of the latent space in autoencoders for understanding the intrinsic dimension of data and its implications for memory representation.
Plain English Explanation
The paper examines how machine learning techniques, particularly autoencoders, can be used to model the concept of engrams - the neural representations of memories in the brain.
The key idea is that the latent space, or the compressed representation learned by the autoencoder, may hold valuable insights into the intrinsic dimensionality of the data, which could be relevant for understanding how memories are stored and retrieved in the brain. By exploring the structure of the latent space, researchers can gain a better understanding of the underlying patterns and features that are important for representing and processing memories.
This research could have important implications for the field of neuromimetic computing, where the goal is to develop artificial systems that can mimic the information processing capabilities of the human brain.
Technical Explanation
The paper delves into the structure of autoencoders and how the intrinsic dimension of the data, as captured by the latent space, can provide insights into the representation of engrams. Autoencoders are a type of neural network that are trained to learn a compressed representation of the input data, which can then be used to reconstruct the original input.
The authors argue that the dimensionality of the latent space, which reflects the intrinsic complexity of the data, may be relevant for understanding the way memories are represented in the brain. By studying the structure and properties of the latent space, researchers can gain insights into the fundamental principles underlying memory formation and retrieval.
The paper discusses various approaches to analyzing the latent space, such as visualization techniques and dimensionality reduction methods, and how these can be used to explore the relationship between the latent representation and the underlying memory processes.
Critical Analysis
The paper presents a compelling argument for the potential of using machine learning techniques, particularly autoencoders, to study the neural mechanisms of memory. However, the authors acknowledge that this is a complex and challenging problem, and there are several caveats and limitations to consider.
One potential issue is the extent to which the latent space of an autoencoder accurately reflects the intrinsic dimensionality of the data, as there may be other factors, such as the architecture of the network and the training process, that can influence the resulting representation.
Additionally, the paper does not address the potential challenges of scaling these techniques to more realistic and complex memory tasks, as the experiments presented may be oversimplified or focused on specific types of memory representations.
Further research is needed to fully understand the relationship between the latent space of autoencoders and the neurobiological mechanisms of memory, as well as to explore the broader implications of this approach for the development of neuromimetic computing systems.
Conclusion
This paper presents an intriguing approach to studying the neural underpinnings of memory using machine learning techniques, specifically autoencoders. By exploring the latent space of these models, researchers can gain insights into the intrinsic dimensionality of data and how it may relate to the representation of engrams in the brain.
While there are challenges and limitations to this approach, the potential implications for neuromimetic computing and our understanding of memory processes are significant. This research could pave the way for more advanced models of cognition and information processing, with applications in fields ranging from cognitive neuroscience to artificial intelligence.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Implementing engrams from a machine learning perspective: the relevance of a latent space
J Marco de Lucas
In our previous work, we proposed that engrams in the brain could be biologically implemented as autoencoders over recurrent neural networks. These autoencoders would comprise basic excitatory/inhibitory motifs, with credit assignment deriving from a simple homeostatic criterion. This brief note examines the relevance of the latent space in these autoencoders. We consider the relationship between the dimensionality of these autoencoders and the complexity of the information being encoded. We discuss how observed differences between species in their connectome could be linked to their cognitive capacities. Finally, we link this analysis with a basic but often overlooked fact: human cognition is likely limited by our own brain structure. However, this limitation does not apply to machine learning systems, and we should be aware of the need to learn how to exploit this augmented vision of the nature.
Read more7/24/2024

0
Closed-Form Interpretation of Neural Network Latent Spaces with Symbolic Gradients
Zakaria Patel, Sebastian J. Wetzel
It has been demonstrated in many scientific fields that artificial neural networks like autoencoders or Siamese networks encode meaningful concepts in their latent spaces. However, there does not exist a comprehensive framework for retrieving this information in a human-readable form without prior knowledge. In order to extract these concepts, we introduce a framework for finding closed-form interpretations of neurons in latent spaces of artificial neural networks. The interpretation framework is based on embedding trained neural networks into an equivalence class of functions that encode the same concept. We interpret these neural networks by finding an intersection between the equivalence class and human-readable equations defined by a symbolic search space. The approach is demonstrated by retrieving invariants of matrices and conserved quantities of dynamical systems from latent spaces of Siamese neural networks.
Read more9/10/2024
0
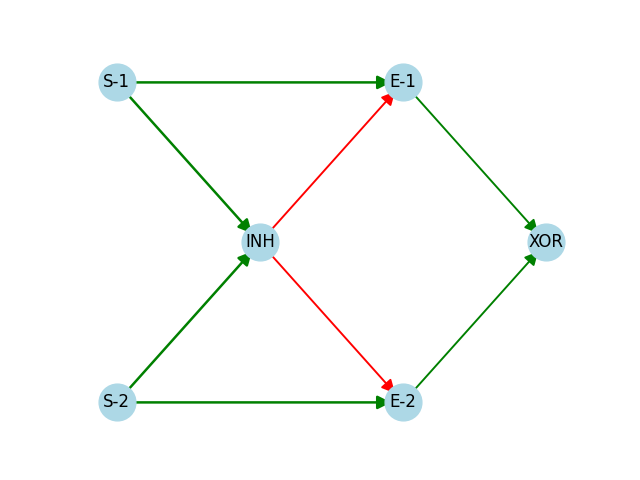
Implementing engrams from a machine learning perspective: XOR as a basic motif
Jesus Marco de Lucas, Maria Pe~na Fernandez, Lara Lloret Iglesias
We have previously presented the idea of how complex multimodal information could be represented in our brains in a compressed form, following mechanisms similar to those employed in machine learning tools, like autoencoders. In this short comment note we reflect, mainly with a didactical purpose, upon the basic question for a biological implementation: what could be the mechanism working as a loss function, and how it could be connected to a neuronal network providing the required feedback to build a simple training configuration. We present our initial ideas based on a basic motif that implements an XOR switch, using few excitatory and inhibitory neurons. Such motif is guided by a principle of homeostasis, and it implements a loss function that could provide feedback to other neuronal structures, establishing a control system. We analyse the presence of this XOR motif in the connectome of C.Elegans, and indicate the relationship with the well-known lateral inhibition motif. We then explore how to build a basic biological neuronal structure with learning capacity integrating this XOR motif. Guided by the computational analogy, we show an initial example that indicates the feasibility of this approach, applied to learning binary sequences, like it is the case for simple melodies. In summary, we provide didactical examples exploring the parallelism between biological and computational learning mechanisms, identifying basic motifs and training procedures, and how an engram encoding a melody could be built using a simple recurrent network involving both excitatory and inhibitory neurons.
Read more6/17/2024
0
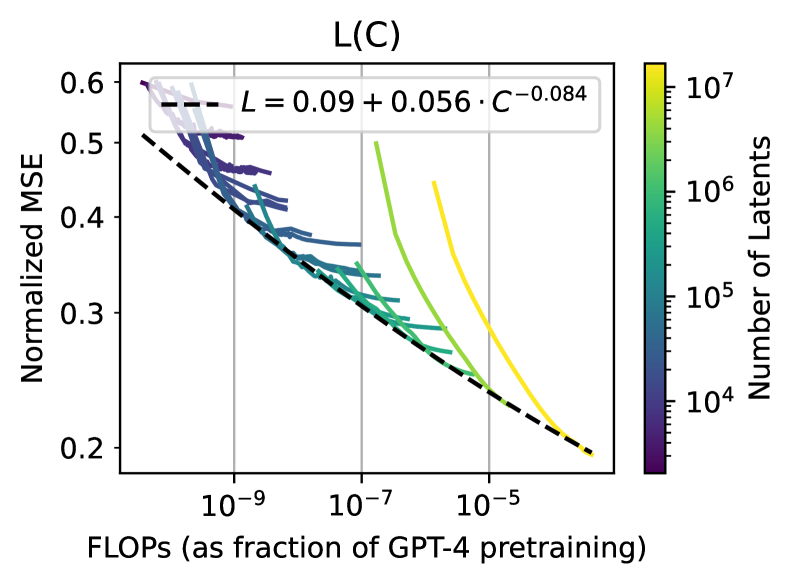
Scaling and evaluating sparse autoencoders
Leo Gao, Tom Dupr'e la Tour, Henk Tillman, Gabriel Goh, Rajan Troll, Alec Radford, Ilya Sutskever, Jan Leike, Jeffrey Wu
Sparse autoencoders provide a promising unsupervised approach for extracting interpretable features from a language model by reconstructing activations from a sparse bottleneck layer. Since language models learn many concepts, autoencoders need to be very large to recover all relevant features. However, studying the properties of autoencoder scaling is difficult due to the need to balance reconstruction and sparsity objectives and the presence of dead latents. We propose using k-sparse autoencoders [Makhzani and Frey, 2013] to directly control sparsity, simplifying tuning and improving the reconstruction-sparsity frontier. Additionally, we find modifications that result in few dead latents, even at the largest scales we tried. Using these techniques, we find clean scaling laws with respect to autoencoder size and sparsity. We also introduce several new metrics for evaluating feature quality based on the recovery of hypothesized features, the explainability of activation patterns, and the sparsity of downstream effects. These metrics all generally improve with autoencoder size. To demonstrate the scalability of our approach, we train a 16 million latent autoencoder on GPT-4 activations for 40 billion tokens. We release training code and autoencoders for open-source models, as well as a visualizer.
Read more6/7/2024