The Importance of Positional Encoding Initialization in Transformers for Relational Reasoning
2406.08272
0
0
Abstract
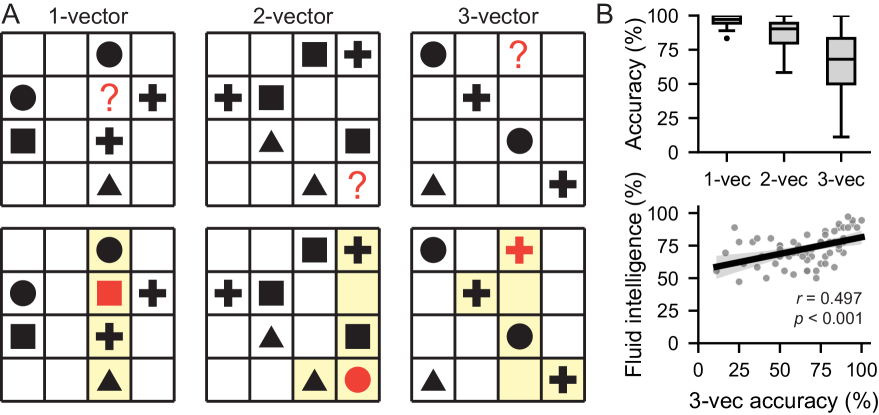
Relational reasoning refers to the ability to infer and understand the relations between multiple entities. In humans, this ability underpins many higher cognitive functions, such as problem solving and decision-making, and has been reliably linked to fluid intelligence. Despite machine learning models making impressive advances across various domains, such as natural language processing and vision, the extent to which such models can perform relational reasoning tasks remains unclear. Here we study the importance of positional encoding (PE) for relational reasoning in the Transformer, and find that a learnable PE outperforms all other commonly-used PEs (e.g., absolute, relative, rotary, etc.). Moreover, we find that when using a PE with a learnable parameter, the choice of initialization greatly influences the learned representations and its downstream generalization performance. Specifically, we find that a learned PE initialized from a small-norm distribution can 1) uncover ground-truth position information, 2) generalize in the presence of noisy inputs, and 3) produce behavioral patterns that are consistent with human performance. Our results shed light on the importance of learning high-performing and robust PEs during relational reasoning tasks, which will prove useful for tasks in which ground truth positions are not provided or not known.
Create account to get full access
Overview
- This paper investigates the importance of positional encoding initialization in Transformer models for relational reasoning tasks.
- Positional encoding is a crucial component of Transformer models, which capture the relative positions of input elements.
- The authors explore how different positional encoding initialization methods can impact the model's ability to learn and reason about relationships between entities.
Plain English Explanation
Transformer models are a type of artificial intelligence that have become very popular in recent years. These models are particularly good at understanding and processing language, as well as other types of sequential data.
A key part of Transformer models is the "positional encoding," which tells the model where each element in the input is positioned. This is important because the relationships between different parts of the input are often crucial for understanding the overall meaning.
In this paper, the researchers investigate how the initial values of the positional encoding can affect the model's ability to learn and reason about relationships between entities. They explore different ways of initializing the positional encoding and examine the impact on the model's performance on relational reasoning tasks.
The findings from this research can help guide the design and use of Transformer models in a variety of applications, such as natural language processing and time series forecasting. By understanding the importance of positional encoding initialization, researchers and practitioners can optimize Transformer models for better performance on tasks that require reasoning about relationships between different elements.
Technical Explanation
The paper investigates the importance of positional encoding initialization in Transformer models for relational reasoning tasks. Positional encoding is a crucial component of Transformer models, as it captures the relative positions of input elements. The authors explore how different positional encoding initialization methods can impact the model's ability to learn and reason about relationships between entities.
The paper presents several experiments that compare the performance of Transformer models with different positional encoding initialization methods on relational reasoning tasks. The authors evaluate the models on various benchmark datasets and analyze the results to understand the impact of the initialization approach.
The findings suggest that the choice of positional encoding initialization can significantly affect the model's performance on relational reasoning tasks. The authors observe that certain initialization methods, such as using sinusoidal functions or learnable parameters, can lead to better learning and reasoning capabilities compared to other approaches.
The paper provides insights into the importance of positional encoding initialization in Transformer models and highlights the need to carefully consider this design choice when developing models for tasks that require understanding relationships between entities. The results can inform the development of more effective Transformer-based models for a wide range of applications, including natural language processing, time series forecasting, and graph-based learning.
Critical Analysis
The paper presents a well-designed study that systematically explores the impact of positional encoding initialization on the performance of Transformer models in relational reasoning tasks. The authors acknowledge the potential limitations of their work, such as the need to extend the analysis to more diverse datasets and tasks.
One potential area for further research could be investigating the generalization of the findings to other types of Transformer-based models, such as those used in graph-based learning or time series forecasting. Additionally, exploring the interaction between positional encoding initialization and other architectural or training choices could provide a more comprehensive understanding of the factors that influence the performance of Transformer models in relational reasoning tasks.
The paper's findings highlight the importance of carefully considering the positional encoding initialization in the design and development of Transformer models. However, it would be valuable to further investigate the underlying mechanisms by which different initialization methods impact the model's ability to learn and reason about relationships. This could involve analyzing the model's internal representations or conducting additional ablation studies to isolate the specific factors contributing to the observed performance differences.
Overall, the paper presents a valuable contribution to the understanding of Transformer models and the role of positional encoding initialization in tasks that require relational reasoning. The findings can inform the development of more effective Transformer-based models and inspire further research in this important area of machine learning.
Conclusion
This paper emphasizes the crucial role of positional encoding initialization in Transformer models for relational reasoning tasks. The authors demonstrate that the choice of positional encoding initialization can significantly impact the model's ability to learn and reason about relationships between entities.
The findings from this research can help guide the design and optimization of Transformer models in a variety of applications, such as natural language processing, time series forecasting, and graph-based learning. By understanding the importance of positional encoding initialization, researchers and practitioners can develop more effective Transformer-based models that can better capture and reason about the relationships within their input data.
The insights provided in this paper represent an important step forward in understanding the intricacies of Transformer models and their performance on tasks that require reasoning about complex relationships. The potential for further research in this area, as discussed in the critical analysis, suggests that the impact of this work may extend beyond the specific findings presented and contribute to the broader advancement of Transformer-based AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Comparing Graph Transformers via Positional Encodings
Mitchell Black, Zhengchao Wan, Gal Mishne, Amir Nayyeri, Yusu Wang
0
0
The distinguishing power of graph transformers is closely tied to the choice of positional encoding: features used to augment the base transformer with information about the graph. There are two primary types of positional encoding: absolute positional encodings (APEs) and relative positional encodings (RPEs). APEs assign features to each node and are given as input to the transformer. RPEs instead assign a feature to each pair of nodes, e.g., graph distance, and are used to augment the attention block. A priori, it is unclear which method is better for maximizing the power of the resulting graph transformer. In this paper, we aim to understand the relationship between these different types of positional encodings. Interestingly, we show that graph transformers using APEs and RPEs are equivalent in terms of distinguishing power. In particular, we demonstrate how to interchange APEs and RPEs while maintaining their distinguishing power in terms of graph transformers. Based on our theoretical results, we provide a study on several APEs and RPEs (including the resistance distance and the recently introduced stable and expressive positional encoding (SPE)) and compare their distinguishing power in terms of transformers. We believe our work will help navigate the huge number of choices of positional encoding and will provide guidance on the future design of positional encodings for graph transformers.
6/6/2024

GridPE: Unifying Positional Encoding in Transformers with a Grid Cell-Inspired Framework
Boyang Li, Yulin Wu, Nuoxian Huang
0
0
Understanding spatial location and relationships is a fundamental capability for modern artificial intelligence systems. Insights from human spatial cognition provide valuable guidance in this domain. Recent neuroscientific discoveries have highlighted the role of grid cells as a fundamental neural component for spatial representation, including distance computation, path integration, and scale discernment. In this paper, we introduce a novel positional encoding scheme inspired by Fourier analysis and the latest findings in computational neuroscience regarding grid cells. Assuming that grid cells encode spatial position through a summation of Fourier basis functions, we demonstrate the translational invariance of the grid representation during inner product calculations. Additionally, we derive an optimal grid scale ratio for multi-dimensional Euclidean spaces based on principles of biological efficiency. Utilizing these computational principles, we have developed a **Grid**-cell inspired **Positional Encoding** technique, termed **GridPE**, for encoding locations within high-dimensional spaces. We integrated GridPE into the Pyramid Vision Transformer architecture. Our theoretical analysis shows that GridPE provides a unifying framework for positional encoding in arbitrary high-dimensional spaces. Experimental results demonstrate that GridPE significantly enhances the performance of transformers, underscoring the importance of incorporating neuroscientific insights into the design of artificial intelligence systems.
6/12/2024
Intriguing Properties of Positional Encoding in Time Series Forecasting
Jianqi Zhang, Jingyao Wang, Wenwen Qiang, Fanjiang Xu, Changwen Zheng, Fuchun Sun, Hui Xiong
0
0
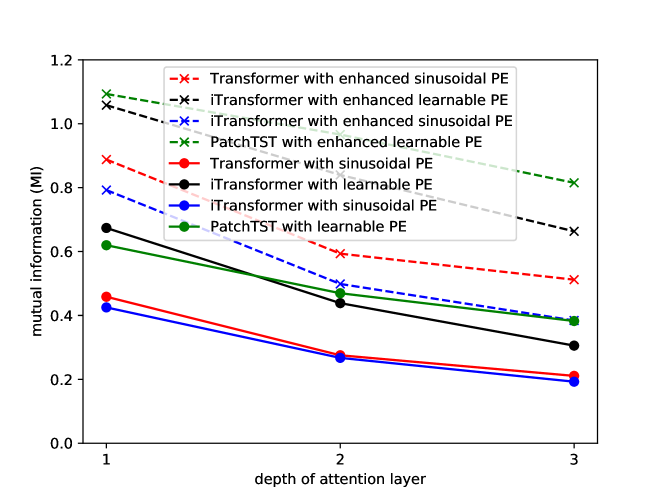
Transformer-based methods have made significant progress in time series forecasting (TSF). They primarily handle two types of tokens, i.e., temporal tokens that contain all variables of the same timestamp, and variable tokens that contain all input time points for a specific variable. Transformer-based methods rely on positional encoding (PE) to mark tokens' positions, facilitating the model to perceive the correlation between tokens. However, in TSF, research on PE remains insufficient. To address this gap, we conduct experiments and uncover intriguing properties of existing PEs in TSF: (i) The positional information injected by PEs diminishes as the network depth increases; (ii) Enhancing positional information in deep networks is advantageous for improving the model's performance; (iii) PE based on the similarity between tokens can improve the model's performance. Motivated by these findings, we introduce two new PEs: Temporal Position Encoding (T-PE) for temporal tokens and Variable Positional Encoding (V-PE) for variable tokens. Both T-PE and V-PE incorporate geometric PE based on tokens' positions and semantic PE based on the similarity between tokens but using different calculations. To leverage both the PEs, we design a Transformer-based dual-branch framework named T2B-PE. It first calculates temporal tokens' correlation and variable tokens' correlation respectively and then fuses the dual-branch features through the gated unit. Extensive experiments demonstrate the superior robustness and effectiveness of T2B-PE. The code is available at: href{https://github.com/jlu-phyComputer/T2B-PE}{https://github.com/jlu-phyComputer/T2B-PE}.
4/17/2024
Contextual Position Encoding: Learning to Count What's Important
Olga Golovneva, Tianlu Wang, Jason Weston, Sainbayar Sukhbaatar
0
0
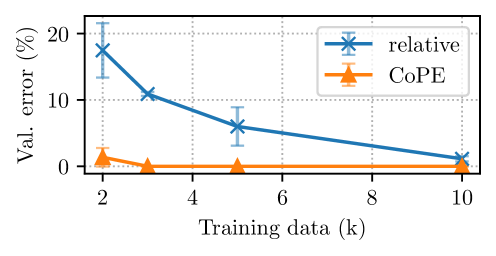
The attention mechanism is a critical component of Large Language Models (LLMs) that allows tokens in a sequence to interact with each other, but is order-invariant. Incorporating position encoding (PE) makes it possible to address by position, such as attending to the i-th token. However, current PE methods use token counts to derive position, and thus cannot generalize to higher levels of abstraction, such as attending to the i-th sentence. In this paper, we propose a new position encoding method, Contextual Position Encoding (CoPE), that allows positions to be conditioned on context by incrementing position only on certain tokens determined by the model. This allows more general position addressing such as attending to the $i$-th particular word, noun, or sentence. We show that CoPE can solve the selective copy, counting and Flip-Flop tasks where popular position embeddings fail, and improves perplexity on language modeling and coding tasks.
5/31/2024