Intriguing Properties of Positional Encoding in Time Series Forecasting

0
Sign in to get full access
Overview
- This paper investigates the intriguing properties of positional encoding in time series forecasting using Transformer-based methods.
- Positional encoding is a technique used in Transformer models to incorporate information about the position of each input element.
- The paper explores the impact of different positional encoding schemes on the performance of Transformer-based time series forecasting models.
Plain English Explanation
Positional encoding is a crucial component of Transformer models, which are a type of machine learning architecture used for tasks like language modeling and time series forecasting. Transformer models are designed to understand the relationships between different parts of the input, but they don't inherently know the order of the input. Positional encoding is a way to add information about the position of each input element, which can help the model learn these relationships more effectively.
This paper investigates how different ways of encoding the position information can affect the performance of Transformer-based time series forecasting models. The researchers explore different positional encoding schemes, such as using sine and cosine functions or learnable embeddings, and evaluate their impact on the model's ability to make accurate predictions. They also examine how the choice of positional encoding affects the model's ability to extrapolate, or make predictions beyond the range of the training data.
The key insights from this research could help researchers and practitioners develop more effective Transformer-based models for time series forecasting and other applications where the order of the input is important. By understanding the intricacies of positional encoding, they can make more informed choices about the architecture and training of their models, potentially leading to improved performance and better real-world applications.
Technical Explanation
The paper explores the impact of different positional encoding schemes on the performance of Transformer-based time series forecasting models. Transformer models are a type of neural network architecture that has achieved state-of-the-art results in a variety of tasks, including time series forecasting. A key component of Transformer models is the use of positional encoding, which adds information about the position of each input element to the model's input.
The researchers investigate several different positional encoding schemes, including:
- Sine and cosine functions: This is the standard positional encoding method used in the original Transformer paper, where the position of each input element is encoded using sine and cosine functions of different frequencies.
- Learnable positional embeddings: In this approach, the model learns a unique positional embedding for each input position, similar to how word embeddings are learned in language models.
- Relative positional encoding: This method encodes the relative position between each pair of input elements, rather than the absolute position of each element.
The paper evaluates the performance of Transformer-based time series forecasting models using these different positional encoding schemes on a range of benchmark datasets. The results show that the choice of positional encoding can have a significant impact on the model's forecasting accuracy, as well as its ability to extrapolate beyond the training data.
Critical Analysis
The paper presents a thorough investigation of the impact of positional encoding on Transformer-based time series forecasting models. The researchers have carefully designed their experiments to isolate the effects of different positional encoding schemes and provide valuable insights into the intricacies of this important component of Transformer architectures.
One potential limitation of the study is that it focuses primarily on synthetic and relatively simple time series datasets. While these provide a controlled environment for evaluating the effects of positional encoding, it would be interesting to see how the findings translate to more complex, real-world time series data. Additionally, the paper does not explore the interaction between positional encoding and other architectural choices, such as the use of attention mechanisms or the design of the Transformer layers.
Another area for further research could be the stability and expressiveness of different positional encoding schemes, particularly in the context of time series forecasting. Understanding how the choice of positional encoding affects the model's ability to learn and generalize could lead to more robust and reliable Transformer-based forecasting systems.
Overall, this paper makes a valuable contribution to our understanding of the role of positional encoding in Transformer-based time series forecasting. The insights and recommendations provided in the paper could help researchers and practitioners make more informed choices when designing and training these models for real-world applications.
Conclusion
This paper investigates the intriguing properties of positional encoding in Transformer-based time series forecasting models. The researchers explore the impact of different positional encoding schemes, including sine and cosine functions, learnable positional embeddings, and relative positional encoding, on the performance and extrapolation capabilities of these models.
The key findings suggest that the choice of positional encoding can have a significant impact on the model's forecasting accuracy and its ability to make predictions beyond the training data. These insights could inform the design and training of more effective Transformer-based models for time series forecasting and other applications where the order of the input is important.
By understanding the nuances of positional encoding, researchers and practitioners can make more informed decisions about the architecture and training of their models, potentially leading to improved performance and better real-world applications of Transformer-based methods in the field of time series forecasting and beyond.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Intriguing Properties of Positional Encoding in Time Series Forecasting
Jianqi Zhang, Jingyao Wang, Wenwen Qiang, Fanjiang Xu, Changwen Zheng, Fuchun Sun, Hui Xiong
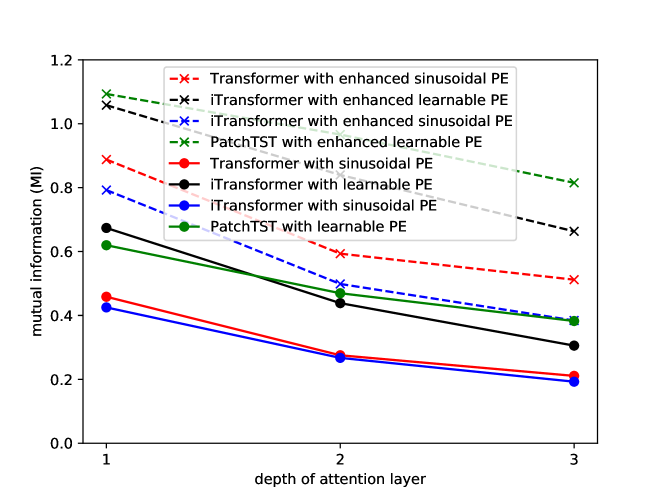
Transformer-based methods have made significant progress in time series forecasting (TSF). They primarily handle two types of tokens, i.e., temporal tokens that contain all variables of the same timestamp, and variable tokens that contain all input time points for a specific variable. Transformer-based methods rely on positional encoding (PE) to mark tokens' positions, facilitating the model to perceive the correlation between tokens. However, in TSF, research on PE remains insufficient. To address this gap, we conduct experiments and uncover intriguing properties of existing PEs in TSF: (i) The positional information injected by PEs diminishes as the network depth increases; (ii) Enhancing positional information in deep networks is advantageous for improving the model's performance; (iii) PE based on the similarity between tokens can improve the model's performance. Motivated by these findings, we introduce two new PEs: Temporal Position Encoding (T-PE) for temporal tokens and Variable Positional Encoding (V-PE) for variable tokens. Both T-PE and V-PE incorporate geometric PE based on tokens' positions and semantic PE based on the similarity between tokens but using different calculations. To leverage both the PEs, we design a Transformer-based dual-branch framework named T2B-PE. It first calculates temporal tokens' correlation and variable tokens' correlation respectively and then fuses the dual-branch features through the gated unit. Extensive experiments demonstrate the superior robustness and effectiveness of T2B-PE. The code is available at: href{https://github.com/jlu-phyComputer/T2B-PE}{https://github.com/jlu-phyComputer/T2B-PE}.
Read more4/17/2024

0
Comparing Graph Transformers via Positional Encodings
Mitchell Black, Zhengchao Wan, Gal Mishne, Amir Nayyeri, Yusu Wang
The distinguishing power of graph transformers is closely tied to the choice of positional encoding: features used to augment the base transformer with information about the graph. There are two primary types of positional encoding: absolute positional encodings (APEs) and relative positional encodings (RPEs). APEs assign features to each node and are given as input to the transformer. RPEs instead assign a feature to each pair of nodes, e.g., graph distance, and are used to augment the attention block. A priori, it is unclear which method is better for maximizing the power of the resulting graph transformer. In this paper, we aim to understand the relationship between these different types of positional encodings. Interestingly, we show that graph transformers using APEs and RPEs are equivalent in terms of distinguishing power. In particular, we demonstrate how to interchange APEs and RPEs while maintaining their distinguishing power in terms of graph transformers. Based on our theoretical results, we provide a study on several APEs and RPEs (including the resistance distance and the recently introduced stable and expressive positional encoding (SPE)) and compare their distinguishing power in terms of transformers. We believe our work will help navigate the huge number of choices of positional encoding and will provide guidance on the future design of positional encodings for graph transformers.
Read more8/26/2024

0
Length Extrapolation of Transformers: A Survey from the Perspective of Positional Encoding
Liang Zhao, Xiaocheng Feng, Xiachong Feng, Dongliang Xu, Qing Yang, Hongtao Liu, Bing Qin, Ting Liu
Transformer has taken the field of natural language processing (NLP) by storm since its birth. Further, Large language models (LLMs) built upon it have captured worldwide attention due to its superior abilities. Nevertheless, all Transformer-based models including these powerful LLMs suffer from a preset length limit and can hardly generalize from short training sequences to longer inference ones, namely, they can not perform length extrapolation. Hence, a plethora of methods have been proposed to enhance length extrapolation of Transformer, in which the positional encoding (PE) is recognized as the major factor. In this survey, we present these advances towards length extrapolation in a unified notation from the perspective of PE. Specifically, we first introduce extrapolatable PEs, including absolute and relative PEs. Then, we dive into extrapolation methods based on them, covering position interpolation and randomized position methods. Finally, several challenges and future directions in this area are highlighted. Through this survey, We aim to enable the reader to gain a deep understanding of existing methods and provide stimuli for future research.
Read more4/3/2024
0
Improving Transformers using Faithful Positional Encoding
Tsuyoshi Id'e, Jokin Labaien, Pin-Yu Chen
We propose a new positional encoding method for a neural network architecture called the Transformer. Unlike the standard sinusoidal positional encoding, our approach is based on solid mathematical grounds and has a guarantee of not losing information about the positional order of the input sequence. We show that the new encoding approach systematically improves the prediction performance in the time-series classification task.
Read more5/17/2024