Impossible Distillation: from Low-Quality Model to High-Quality Dataset & Model for Summarization and Paraphrasing
2305.16635
1
0
📈
Abstract
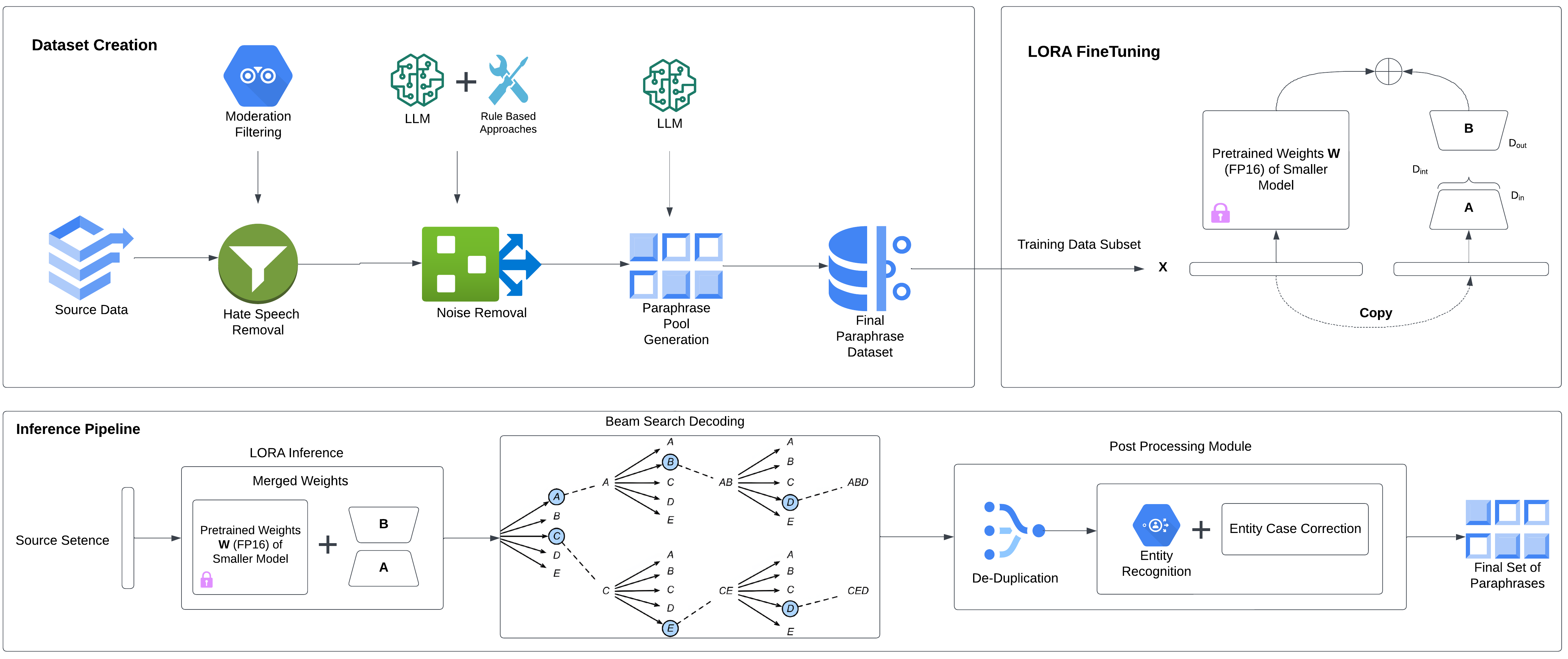
We present Impossible Distillation, a novel framework for paraphrasing and sentence summarization, that distills a high-quality dataset and model from a low-quality teacher that itself cannot perform these tasks. Unlike prior works that rely on an extreme-scale teacher model (e.g., GPT3) or task-specific architecture, we hypothesize and verify the paraphrastic proximity intrinsic to pre-trained LMs (e.g., GPT2), where paraphrases occupy a proximal subspace in the LM distribution. By identifying and distilling generations from these subspaces, Impossible Distillation produces a high-quality dataset and model even from GPT2-scale LMs. We evaluate our method on multiple benchmarks spanning unconstrained / syntax-controlled paraphrase generation and sentence summarization. Our model with 770M parameters consistently outperforms strong baselines, including models distilled from ChatGPT, and sometimes, even ChatGPT itself. Also, we find that our distilled dataset from 1.5B LMs exhibits higher diversity and fidelity than up to 13 times larger datasets.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- Presents a novel framework called "Impossible Distillation" for paraphrasing and sentence summarization
- Distills a high-quality dataset and model from a low-quality teacher model that cannot perform these tasks
- Leverages the paraphrastic proximity intrinsic to pre-trained language models (LMs) like GPT-2
Plain English Explanation
The researchers have developed a new technique called "Impossible Distillation" that can create high-quality paraphrasing and sentence summarization models, even when starting from a low-quality teacher model that cannot perform these tasks well.
The key insight is that pre-trained language models like GPT-2 have an inherent ability to generate paraphrases, as the paraphrases occupy a similar "space" within the model's distribution. By identifying and distilling these paraphrase-like generations, the researchers were able to build a powerful model, despite starting with a relatively small GPT-2 model as the "teacher."
This is an important advance because prior work on model distillation [1][2][3] has typically relied on extremely large "teacher" models like GPT-3, or specialized architectures. In contrast, Impossible Distillation shows that high-quality models can be extracted from more modest-sized language models, opening up new possibilities for practical applications of paraphrasing and summarization.
Technical Explanation
The core hypothesis behind Impossible Distillation is that pre-trained language models like GPT-2 have an intrinsic "paraphrastic proximity" - meaning that paraphrased sentences occupy a proximal subspace within the model's distribution. By identifying and distilling the generations from these subspaces, the researchers were able to create a high-quality paraphrasing and summarization model, even starting from a relatively small GPT-2 teacher model.
The key steps of the Impossible Distillation framework are:
- Generating a large set of paraphrased and summarized sentences from the GPT-2 teacher model.
- Filtering this generation set to identify the highest-quality paraphrases and summaries.
- Training a student model to mimic the filtered generations, producing a high-quality paraphrasing and summarization model.
The researchers evaluated their method on several benchmark tasks, including unconstrained paraphrase generation, syntax-controlled paraphrase generation, and sentence summarization. Their 770M parameter student model consistently outperformed strong baselines, including models distilled from the much larger ChatGPT model. Interestingly, the student model sometimes even outperformed ChatGPT itself on these tasks.
Additionally, the researchers found that the distilled dataset from their 1.5B parameter teacher model exhibited higher diversity and fidelity than datasets up to 13 times larger, suggesting their distillation approach is highly efficient.
Critical Analysis
A key strength of the Impossible Distillation approach is its ability to extract high-quality models from relatively modest-sized teacher models, in contrast to prior work that has relied on extreme-scale models like GPT-3. This makes the technique more accessible and applicable for practical use cases.
That said, the paper does not deeply explore the limitations of the method. For example, it's unclear how the performance and efficiency of Impossible Distillation would scale as the teacher model size increases. Additionally, the paper does not address potential biases or safety concerns that may arise from distilling a model from the GPT-2 teacher.
Further research could investigate the broader applicability of the paraphrastic proximity insight, both for distillation and other language modeling tasks. Exploring the connection to recent work on language-independent representations for zero-shot summarization could also be an interesting avenue to pursue.
Conclusion
The Impossible Distillation framework represents an important advance in paraphrasing and sentence summarization, demonstrating that high-quality models can be distilled from relatively small pre-trained language models. This opens up new possibilities for practical applications of these tasks, as the technique does not require access to massive, extreme-scale teacher models.
The key insight of paraphrastic proximity within pre-trained LMs is a novel and valuable contribution, and the strong empirical results suggest that Impossible Distillation could have a significant impact on the field of text generation and summarization.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Parameter Efficient Diverse Paraphrase Generation Using Sequence-Level Knowledge Distillation
Lasal Jayawardena, Prasan Yapa
0
0
Over the past year, the field of Natural Language Generation (NLG) has experienced an exponential surge, largely due to the introduction of Large Language Models (LLMs). These models have exhibited the most effective performance in a range of domains within the Natural Language Processing and Generation domains. However, their application in domain-specific tasks, such as paraphrasing, presents significant challenges. The extensive number of parameters makes them difficult to operate on commercial hardware, and they require substantial time for inference, leading to high costs in a production setting. In this study, we tackle these obstacles by employing LLMs to develop three distinct models for the paraphrasing field, applying a method referred to as sequence-level knowledge distillation. These distilled models are capable of maintaining the quality of paraphrases generated by the LLM. They demonstrate faster inference times and the ability to generate diverse paraphrases of comparable quality. A notable characteristic of these models is their ability to exhibit syntactic diversity while also preserving lexical diversity, features previously uncommon due to existing data quality issues in datasets and not typically observed in neural-based approaches. Human evaluation of our models shows that there is only a 4% drop in performance compared to the LLM teacher model used in the distillation process, despite being 1000 times smaller. This research provides a significant contribution to the NLG field, offering a more efficient and cost-effective solution for paraphrasing tasks.
4/22/2024
💬
On the Surprising Efficacy of Distillation as an Alternative to Pre-Training Small Models
Sean Farhat, Deming Chen
0
0
In this paper, we propose that small models may not need to absorb the cost of pre-training to reap its benefits. Instead, they can capitalize on the astonishing results achieved by modern, enormous models to a surprising degree. We observe that, when distilled on a task from a pre-trained teacher model, a small model can achieve or surpass the performance it would achieve if it was pre-trained then finetuned on that task. To allow this phenomenon to be easily leveraged, we establish a connection reducing knowledge distillation to modern contrastive learning, opening two doors: (1) vastly different model architecture pairings can work for the distillation, and (2) most contrastive learning algorithms rooted in the theory of Noise Contrastive Estimation can be easily applied and used. We demonstrate this paradigm using pre-trained teacher models from open-source model hubs, Transformer and convolution based model combinations, and a novel distillation algorithm that massages the Alignment/Uniformity perspective of contrastive learning by Wang & Isola (2020) into a distillation objective. We choose this flavor of contrastive learning due to its low computational cost, an overarching theme of this work. We also observe that this phenomenon tends not to occur if the task is data-limited. However, this can be alleviated by leveraging yet another scale-inspired development: large, pre-trained generative models for dataset augmentation. Again, we use an open-source model, and our rudimentary prompts are sufficient to boost the small model`s performance. Thus, we highlight a training method for small models that is up to 94% faster than the standard pre-training paradigm without sacrificing performance. For practitioners discouraged from fully utilizing modern foundation datasets for their small models due to the prohibitive scale, we believe our work keeps that door open.
5/6/2024
💬
Sub-goal Distillation: A Method to Improve Small Language Agents
Maryam Hashemzadeh, Elias Stengel-Eskin, Sarath Chandar, Marc-Alexandre Cote
0
0
While Large Language Models (LLMs) have demonstrated significant promise as agents in interactive tasks, their substantial computational requirements and restricted number of calls constrain their practical utility, especially in long-horizon interactive tasks such as decision-making or in scenarios involving continuous ongoing tasks. To address these constraints, we propose a method for transferring the performance of an LLM with billions of parameters to a much smaller language model (770M parameters). Our approach involves constructing a hierarchical agent comprising a planning module, which learns through Knowledge Distillation from an LLM to generate sub-goals, and an execution module, which learns to accomplish these sub-goals using elementary actions. In detail, we leverage an LLM to annotate an oracle path with a sequence of sub-goals towards completing a goal. Subsequently, we utilize this annotated data to fine-tune both the planning and execution modules. Importantly, neither module relies on real-time access to an LLM during inference, significantly reducing the overall cost associated with LLM interactions to a fixed cost. In ScienceWorld, a challenging and multi-task interactive text environment, our method surpasses standard imitation learning based solely on elementary actions by 16.7% (absolute). Our analysis highlights the efficiency of our approach compared to other LLM-based methods. Our code and annotated data for distillation can be found on GitHub.
5/7/2024

New!Curriculum Dataset Distillation
Zhiheng Ma, Anjia Cao, Funing Yang, Xing Wei
0
0
Most dataset distillation methods struggle to accommodate large-scale datasets due to their substantial computational and memory requirements. In this paper, we present a curriculum-based dataset distillation framework designed to harmonize scalability with efficiency. This framework strategically distills synthetic images, adhering to a curriculum that transitions from simple to complex. By incorporating curriculum evaluation, we address the issue of previous methods generating images that tend to be homogeneous and simplistic, doing so at a manageable computational cost. Furthermore, we introduce adversarial optimization towards synthetic images to further improve their representativeness and safeguard against their overfitting to the neural network involved in distilling. This enhances the generalization capability of the distilled images across various neural network architectures and also increases their robustness to noise. Extensive experiments demonstrate that our framework sets new benchmarks in large-scale dataset distillation, achieving substantial improvements of 11.1% on Tiny-ImageNet, 9.0% on ImageNet-1K, and 7.3% on ImageNet-21K. The source code will be released to the community.
5/16/2024