Parameter Efficient Diverse Paraphrase Generation Using Sequence-Level Knowledge Distillation
2404.12596
0
0
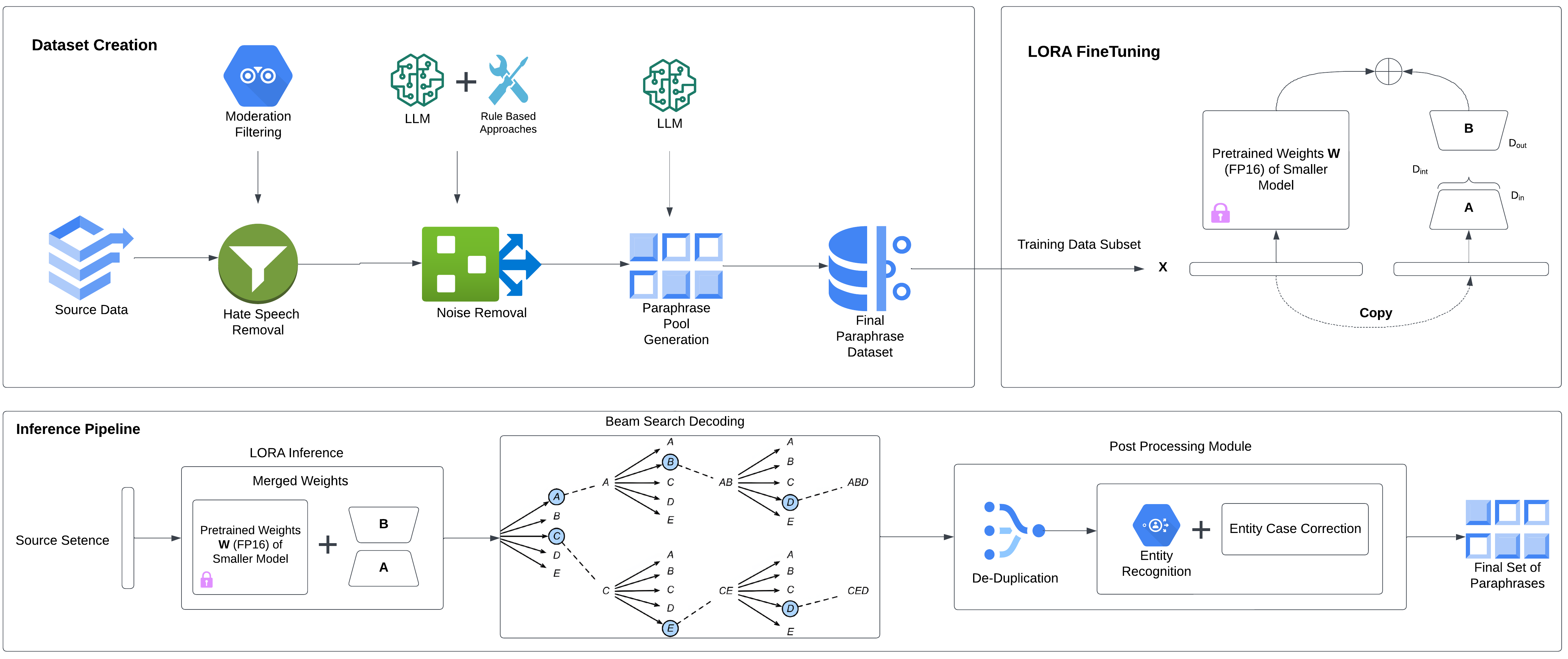
Abstract
Over the past year, the field of Natural Language Generation (NLG) has experienced an exponential surge, largely due to the introduction of Large Language Models (LLMs). These models have exhibited the most effective performance in a range of domains within the Natural Language Processing and Generation domains. However, their application in domain-specific tasks, such as paraphrasing, presents significant challenges. The extensive number of parameters makes them difficult to operate on commercial hardware, and they require substantial time for inference, leading to high costs in a production setting. In this study, we tackle these obstacles by employing LLMs to develop three distinct models for the paraphrasing field, applying a method referred to as sequence-level knowledge distillation. These distilled models are capable of maintaining the quality of paraphrases generated by the LLM. They demonstrate faster inference times and the ability to generate diverse paraphrases of comparable quality. A notable characteristic of these models is their ability to exhibit syntactic diversity while also preserving lexical diversity, features previously uncommon due to existing data quality issues in datasets and not typically observed in neural-based approaches. Human evaluation of our models shows that there is only a 4% drop in performance compared to the LLM teacher model used in the distillation process, despite being 1000 times smaller. This research provides a significant contribution to the NLG field, offering a more efficient and cost-effective solution for paraphrasing tasks.
Create account to get full access
Overview
- This paper introduces a method for generating diverse paraphrases using a parameter-efficient approach based on sequence-level knowledge distillation.
- The authors propose a novel training strategy that allows a small student model to learn effective paraphrase generation from a larger teacher model, while preserving the diversity of the generated outputs.
- The research aims to develop a more efficient paraphrase generation system that can be deployed on resource-constrained devices, without sacrificing the quality and diversity of the generated text.
Plain English Explanation
Paraphrasing is the ability to express the same idea using different words. This can be a useful skill in various applications, such as language learning, text summarization, and dialogue systems. However, training models to generate diverse paraphrases can be challenging and computationally expensive, especially on devices with limited resources.
The researchers in this paper have developed a new approach to address this problem. They trained a smaller "student" model to learn paraphrasing skills from a larger "teacher" model, using a technique called "sequence-level knowledge distillation." This allows the student model to generate diverse paraphrases while being more efficient and requiring fewer parameters than the original teacher model.
The key idea is to have the student model mimic the behavior of the teacher model at the sequence level, rather than just at the word level. This helps the student model capture the nuances and diversity of the paraphrases generated by the teacher, without having to replicate its entire architecture.
By using this approach, the researchers were able to create a paraphrase generation system that is more efficient and can be deployed on devices with limited resources, while still maintaining the quality and diversity of the generated text. This could be particularly useful in applications where paraphrasing is needed but computational resources are constrained, such as on mobile devices or in edge computing scenarios.
Technical Explanation
The paper presents a method for parameter-efficient diverse paraphrase generation using sequence-level knowledge distillation. The authors propose a novel training strategy that allows a small "student" model to learn effective paraphrase generation from a larger "teacher" model, while preserving the diversity of the generated outputs.
The key idea is to use sequence-level knowledge distillation, where the student model is trained to mimic the teacher model's behavior at the sequence level, rather than just at the word level. This helps the student model capture the nuances and diversity of the paraphrases generated by the teacher, without having to replicate its entire architecture.
The training process involves three main components: a teacher model, a student model, and a paraphrase discriminator. The teacher model is a large, pre-trained paraphrase generation model, which serves as the source of knowledge. The student model is a smaller, more efficient model that is trained to generate diverse paraphrases by distilling knowledge from the teacher.
The paraphrase discriminator is a separate model that is trained to distinguish between the paraphrases generated by the teacher and the student. This discriminator is used to provide additional feedback to the student model during training, helping it to generate paraphrases that are indistinguishable from the teacher's output.
The authors evaluate their approach on several paraphrase generation benchmarks and compare it to other state-of-the-art methods. The results show that the proposed approach can achieve comparable or better performance while using significantly fewer parameters than the original teacher model.
Critical Analysis
The research presented in this paper offers a promising approach to developing efficient and diverse paraphrase generation models. The use of sequence-level knowledge distillation is a novel and interesting technique that can help bridge the gap between the performance of large, resource-intensive models and smaller, more efficient ones.
One potential limitation of the approach is that it relies on the availability of a high-quality teacher model, which may not always be the case. If the teacher model is not sufficiently diverse or accurate, the student model may struggle to learn effective paraphrasing skills. Additionally, the training process involving the paraphrase discriminator may be computationally intensive, which could limit the scalability of the approach.
Another area for further research could be exploring the generalization capabilities of the student model. The paper focuses on evaluating the model's performance on specific paraphrase generation benchmarks, but it would be interesting to see how well the model performs on more diverse text genres and domains.
Despite these potential limitations, the overall approach presented in the paper is a valuable contribution to the field of paraphrase generation and language modeling. The ability to create efficient and diverse paraphrase generation models has significant practical applications, and the researchers have demonstrated a novel and promising solution to this challenge.
Conclusion
This paper introduces a parameter-efficient approach to diverse paraphrase generation using sequence-level knowledge distillation. By training a smaller student model to mimic the behavior of a larger teacher model at the sequence level, the authors have developed a more efficient paraphrase generation system that can be deployed on resource-constrained devices without sacrificing the quality and diversity of the generated text.
The research represents a significant advancement in the field of paraphrase generation, as it addresses the challenge of creating diverse and high-performing models while minimizing the computational requirements. The proposed approach has the potential to enable a wide range of applications, from language learning to dialogue systems, where efficient and diverse paraphrasing capabilities are crucial.
While the paper presents some limitations and areas for further research, the overall contribution is highly valuable and demonstrates the potential of leveraging knowledge distillation techniques to develop more efficient and capable language models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Multi-Stage Balanced Distillation: Addressing Long-Tail Challenges in Sequence-Level Knowledge Distillation
Yuhang Zhou, Jing Zhu, Paiheng Xu, Xiaoyu Liu, Xiyao Wang, Danai Koutra, Wei Ai, Furong Huang
0
0
Large language models (LLMs) have significantly advanced various natural language processing tasks, but deploying them remains computationally expensive. Knowledge distillation (KD) is a promising solution, enabling the transfer of capabilities from larger teacher LLMs to more compact student models. Particularly, sequence-level KD, which distills rationale-based reasoning processes instead of merely final outcomes, shows great potential in enhancing students' reasoning capabilities. However, current methods struggle with sequence level KD under long-tailed data distributions, adversely affecting generalization on sparsely represented domains. We introduce the Multi-Stage Balanced Distillation (BalDistill) framework, which iteratively balances training data within a fixed computational budget. By dynamically selecting representative head domain examples and synthesizing tail domain examples, BalDistill achieves state-of-the-art performance across diverse long-tailed datasets, enhancing both the efficiency and efficacy of the distilled models.
6/21/2024
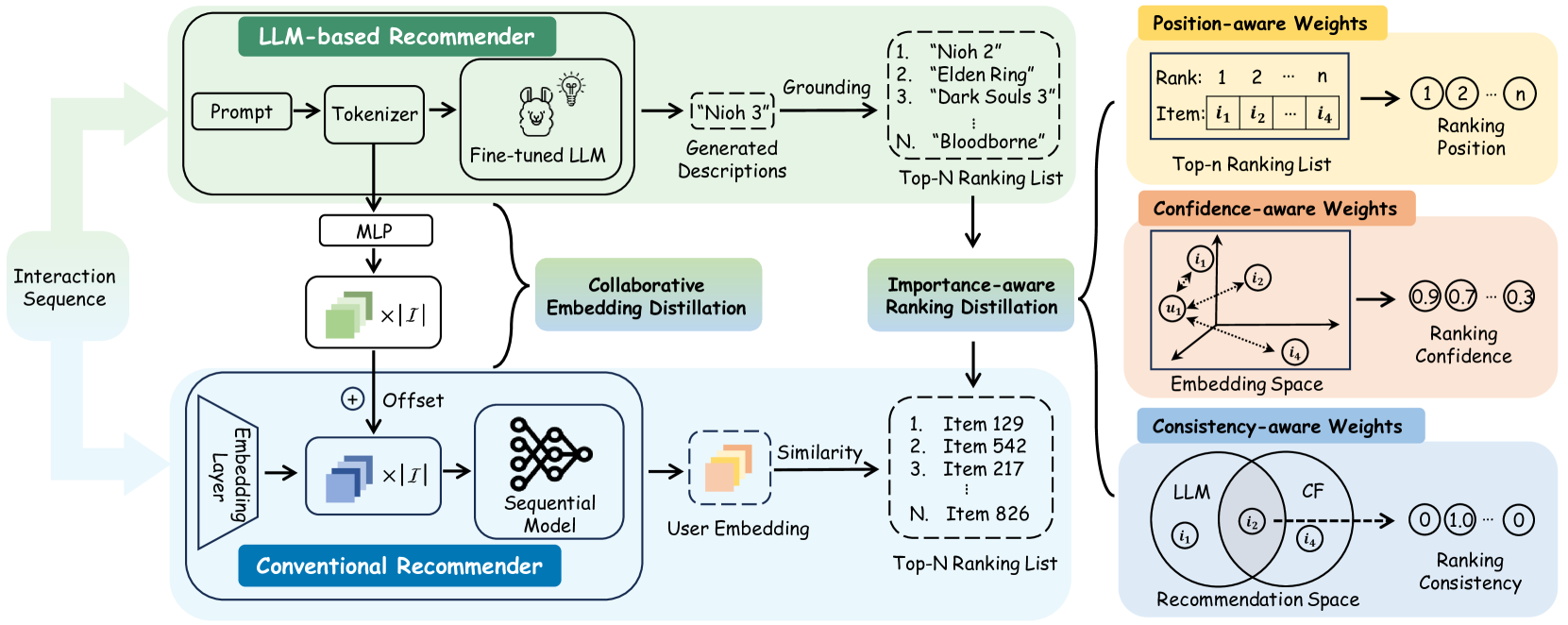
Distillation Matters: Empowering Sequential Recommenders to Match the Performance of Large Language Model
Yu Cui, Feng Liu, Pengbo Wang, Bohao Wang, Heng Tang, Yi Wan, Jun Wang, Jiawei Chen
0
0
Owing to their powerful semantic reasoning capabilities, Large Language Models (LLMs) have been effectively utilized as recommenders, achieving impressive performance. However, the high inference latency of LLMs significantly restricts their practical deployment. To address this issue, this work investigates knowledge distillation from cumbersome LLM-based recommendation models to lightweight conventional sequential models. It encounters three challenges: 1) the teacher's knowledge may not always be reliable; 2) the capacity gap between the teacher and student makes it difficult for the student to assimilate the teacher's knowledge; 3) divergence in semantic space poses a challenge to distill the knowledge from embeddings. To tackle these challenges, this work proposes a novel distillation strategy, DLLM2Rec, specifically tailored for knowledge distillation from LLM-based recommendation models to conventional sequential models. DLLM2Rec comprises: 1) Importance-aware ranking distillation, which filters reliable and student-friendly knowledge by weighting instances according to teacher confidence and student-teacher consistency; 2) Collaborative embedding distillation integrates knowledge from teacher embeddings with collaborative signals mined from the data. Extensive experiments demonstrate the effectiveness of the proposed DLLM2Rec, boosting three typical sequential models with an average improvement of 47.97%, even enabling them to surpass LLM-based recommenders in some cases.
5/6/2024

Knowledge Distillation of LLM for Automatic Scoring of Science Education Assessments
Ehsan Latif, Luyang Fang, Ping Ma, Xiaoming Zhai
0
0
This study proposes a method for knowledge distillation (KD) of fine-tuned Large Language Models (LLMs) into smaller, more efficient, and accurate neural networks. We specifically target the challenge of deploying these models on resource-constrained devices. Our methodology involves training the smaller student model (Neural Network) using the prediction probabilities (as soft labels) of the LLM, which serves as a teacher model. This is achieved through a specialized loss function tailored to learn from the LLM's output probabilities, ensuring that the student model closely mimics the teacher's performance. To validate the performance of the KD approach, we utilized a large dataset, 7T, containing 6,684 student-written responses to science questions and three mathematical reasoning datasets with student-written responses graded by human experts. We compared accuracy with state-of-the-art (SOTA) distilled models, TinyBERT, and artificial neural network (ANN) models. Results have shown that the KD approach has 3% and 2% higher scoring accuracy than ANN and TinyBERT, respectively, and comparable accuracy to the teacher model. Furthermore, the student model size is 0.03M, 4,000 times smaller in parameters and x10 faster in inferencing than the teacher model and TinyBERT, respectively. The significance of this research lies in its potential to make advanced AI technologies accessible in typical educational settings, particularly for automatic scoring.
6/13/2024
💬
Sentence-Level or Token-Level? A Comprehensive Study on Knowledge Distillation
Jingxuan Wei, Linzhuang Sun, Yichong Leng, Xu Tan, Bihui Yu, Ruifeng Guo
0
0
Knowledge distillation, transferring knowledge from a teacher model to a student model, has emerged as a powerful technique in neural machine translation for compressing models or simplifying training targets. Knowledge distillation encompasses two primary methods: sentence-level distillation and token-level distillation. In sentence-level distillation, the student model is trained to align with the output of the teacher model, which can alleviate the training difficulty and give student model a comprehensive understanding of global structure. Differently, token-level distillation requires the student model to learn the output distribution of the teacher model, facilitating a more fine-grained transfer of knowledge. Studies have revealed divergent performances between sentence-level and token-level distillation across different scenarios, leading to the confusion on the empirical selection of knowledge distillation methods. In this study, we argue that token-level distillation, with its more complex objective (i.e., distribution), is better suited for ``simple'' scenarios, while sentence-level distillation excels in ``complex'' scenarios. To substantiate our hypothesis, we systematically analyze the performance of distillation methods by varying the model size of student models, the complexity of text, and the difficulty of decoding procedure. While our experimental results validate our hypothesis, defining the complexity level of a given scenario remains a challenging task. So we further introduce a novel hybrid method that combines token-level and sentence-level distillation through a gating mechanism, aiming to leverage the advantages of both individual methods. Experiments demonstrate that the hybrid method surpasses the performance of token-level or sentence-level distillation methods and the previous works by a margin, demonstrating the effectiveness of the proposed hybrid method.
4/24/2024