Improving Antibody Humanness Prediction using Patent Data

0
Sign in to get full access
Overview
- This paper presents a method for improving antibody humanness prediction using patent data.
- Antibody humanness refers to the degree to which an antibody resembles human antibodies, which is important for reducing the risk of immune reactions when using antibodies as therapeutics.
- The researchers leverage patent data, which contains a wealth of information on antibody sequences and structures, to enhance the performance of machine learning models for predicting antibody humanness.
Plain English Explanation
Antibodies are proteins produced by the immune system that can recognize and bind to specific targets, such as viruses or bacteria. When developing antibody-based drugs, it's important to ensure that the antibodies closely resemble naturally-occurring human antibodies. This reduces the risk of the patient's immune system attacking the therapeutic antibody, which could cause harmful side effects.
The researchers in this paper found a way to improve the ability to predict how "human-like" an antibody is by using data from patent documents. Patent filings often contain detailed information about the structure and sequence of antibodies, which can provide valuable insights beyond what is typically found in scientific publications.
By incorporating this patent data into their machine learning models, the researchers were able to make more accurate predictions about how human-like a given antibody is. This could help drug developers select the most promising antibody candidates for further development, ultimately leading to safer and more effective antibody-based therapies.
Technical Explanation
The researchers developed a machine learning model to predict the humanness of antibody sequences, which is an important consideration when developing antibody-based therapeutics. To improve the performance of this model, they incorporated data from patent documents, which often contain detailed information about antibody structures and sequences that is not always available in scientific publications.
Specifically, the researchers trained their humanness prediction model using a combination of antibody sequences from scientific literature and patent data. They evaluated the model's performance on a held-out test set and found that the inclusion of patent data led to significant improvements in the model's ability to accurately predict antibody humanness.
The researchers also conducted analyses to understand the key factors contributing to the enhanced performance, such as the diversity of antibody sequences and the ability to capture structural information from the patent data. They found that the patent data helped the model better generalize to a wider range of antibody structures, leading to more robust humanness predictions.
Critical Analysis
The paper presents a compelling approach to leveraging patent data to improve antibody humanness prediction, which is an important task for developing safe and effective antibody-based therapeutics. The researchers demonstrate the value of this approach through rigorous experimentation and analysis.
One potential limitation of the study is the reliance on publicly available patent data, which may not capture the full breadth of antibody information held by pharmaceutical companies and other organizations. Accessing additional proprietary data sources could further strengthen the model's performance.
Additionally, the paper does not explore the potential biases or limitations inherent in the patent data itself, such as differences in the quality or completeness of the information across different patent filings. Investigating these factors could provide valuable insights for interpreting the model's predictions.
Overall, the research represents a valuable contribution to the field of antibody engineering and drug development, and the insights gained could inform the development of more robust and reliable humanness prediction models in the future.
Conclusion
This paper presents a novel approach to improving antibody humanness prediction by incorporating patent data into machine learning models. The researchers demonstrate that the inclusion of patent information, which often contains detailed antibody structural and sequence data, can significantly enhance the performance of humanness prediction models.
The ability to accurately predict the humanness of antibodies is crucial for developing safe and effective antibody-based therapeutics, as it helps ensure that the antibodies closely resemble naturally-occurring human antibodies and minimize the risk of immune reactions. By leveraging the wealth of information available in patent filings, this research represents an important step forward in the field of antibody engineering and drug development.
The insights gained from this study could inform the development of more robust and reliable humanness prediction models, ultimately leading to the creation of safer and more effective antibody-based therapies for a wide range of medical conditions.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Improving Antibody Humanness Prediction using Patent Data
Talip Ucar, Aubin Ramon, Dino Oglic, Rebecca Croasdale-Wood, Tom Diethe, Pietro Sormanni
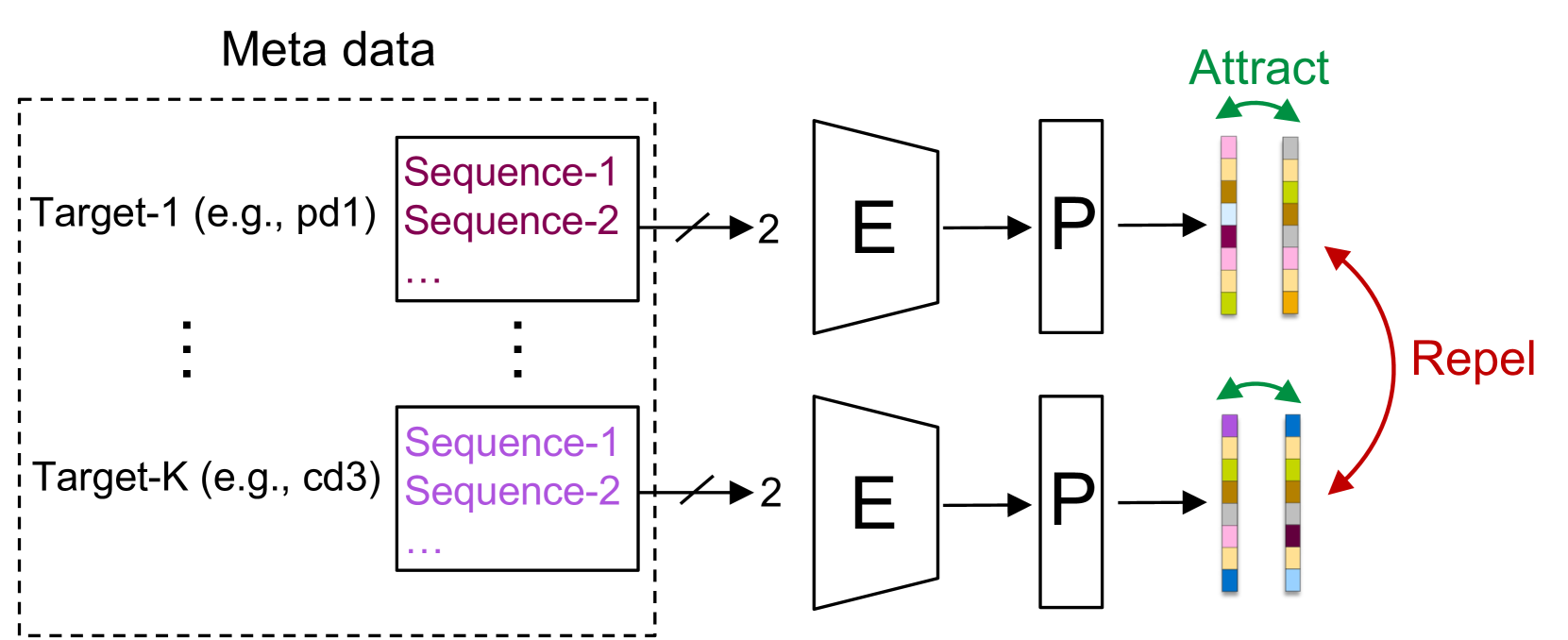
We investigate the potential of patent data for improving the antibody humanness prediction using a multi-stage, multi-loss training process. Humanness serves as a proxy for the immunogenic response to antibody therapeutics, one of the major causes of attrition in drug discovery and a challenging obstacle for their use in clinical settings. We pose the initial learning stage as a weakly-supervised contrastive-learning problem, where each antibody sequence is associated with possibly multiple identifiers of function and the objective is to learn an encoder that groups them according to their patented properties. We then freeze a part of the contrastive encoder and continue training it on the patent data using the cross-entropy loss to predict the humanness score of a given antibody sequence. We illustrate the utility of the patent data and our approach by performing inference on three different immunogenicity datasets, unseen during training. Our empirical results demonstrate that the learned model consistently outperforms the alternative baselines and establishes new state-of-the-art on five out of six inference tasks, irrespective of the used metric.
Read more6/11/2024

0
A SARS-CoV-2 Interaction Dataset and VHH Sequence Corpus for Antibody Language Models
Hirofumi Tsuruta, Hiroyuki Yamazaki, Ryota Maeda, Ryotaro Tamura, Akihiro Imura
Antibodies are crucial proteins produced by the immune system to eliminate harmful foreign substances and have become pivotal therapeutic agents for treating human diseases. To accelerate the discovery of antibody therapeutics, there is growing interest in constructing language models using antibody sequences. However, the applicability of pre-trained language models for antibody discovery has not been thoroughly evaluated due to the scarcity of labeled datasets. To overcome these limitations, we introduce AVIDa-SARS-CoV-2, a dataset featuring the antigen-variable domain of heavy chain of heavy chain antibody (VHH) interactions obtained from two alpacas immunized with severe acute respiratory syndrome coronavirus 2 (SARS-CoV-2) spike proteins. AVIDa-SARS-CoV-2 includes binary labels indicating the binding or non-binding of diverse VHH sequences to 12 SARS-CoV-2 mutants, such as the Delta and Omicron variants. Furthermore, we release VHHCorpus-2M, a pre-training dataset for antibody language models, containing over two million VHH sequences. We report benchmark results for predicting SARS-CoV-2-VHH binding using VHHBERT pre-trained on VHHCorpus-2M and existing general protein and antibody-specific pre-trained language models. These results confirm that AVIDa-SARS-CoV-2 provides valuable benchmarks for evaluating the representation capabilities of antibody language models for binding prediction, thereby facilitating the development of AI-driven antibody discovery. The datasets are available at https://datasets.cognanous.com.
Read more6/4/2024
0
Active learning for affinity prediction of antibodies
Alexandra Gessner, Sebastian W. Ober, Owen Vickery, Dino Ogli'c, Talip Uc{c}ar
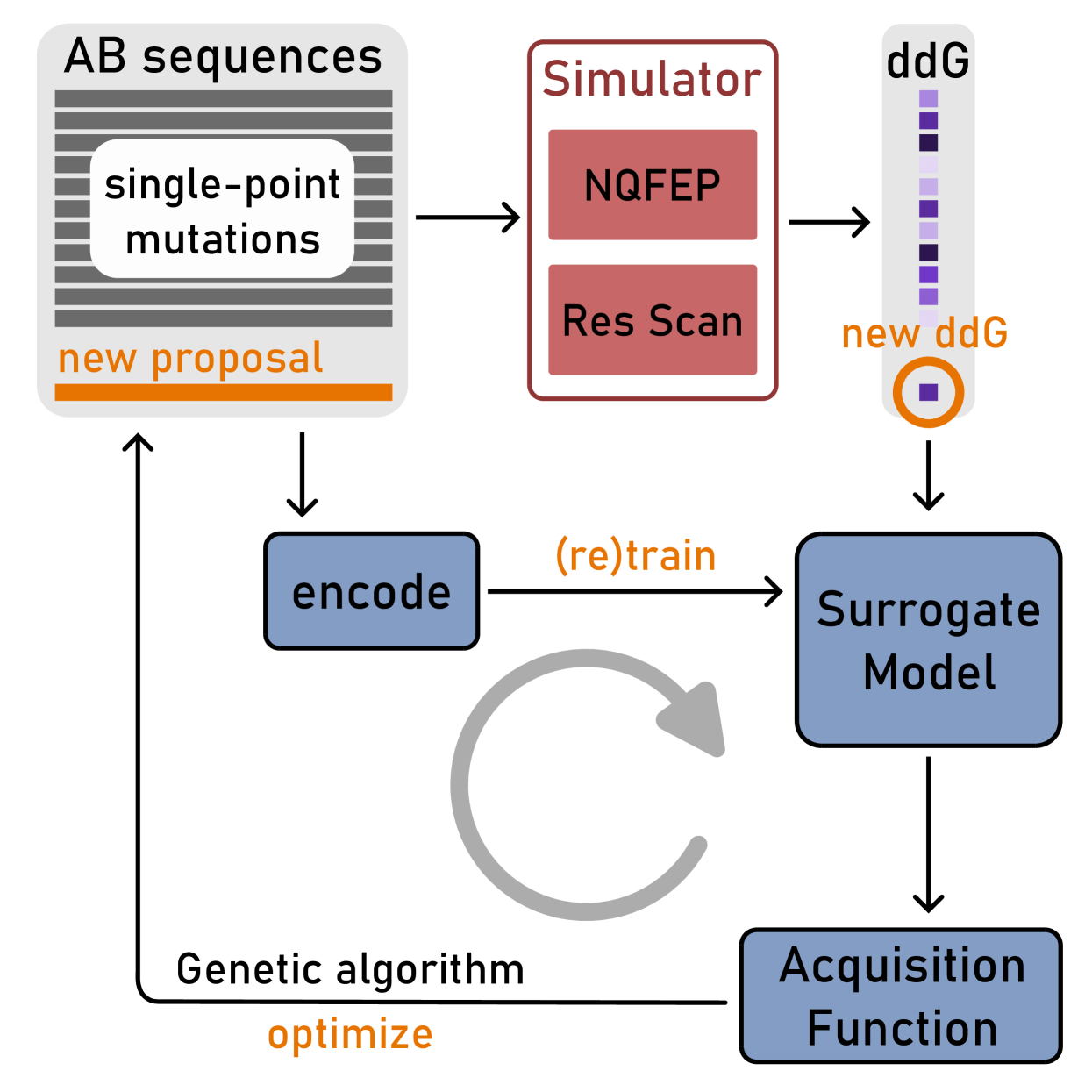
The primary objective of most lead optimization campaigns is to enhance the binding affinity of ligands. For large molecules such as antibodies, identifying mutations that enhance antibody affinity is particularly challenging due to the combinatorial explosion of potential mutations. When the structure of the antibody-antigen complex is available, relative binding free energy (RBFE) methods can offer valuable insights into how different mutations will impact the potency and selectivity of a drug candidate, thereby reducing the reliance on costly and time-consuming wet-lab experiments. However, accurately simulating the physics of large molecules is computationally intensive. We present an active learning framework that iteratively proposes promising sequences for simulators to evaluate, thereby accelerating the search for improved binders. We explore different modeling approaches to identify the most effective surrogate model for this task, and evaluate our framework both using pre-computed pools of data and in a realistic full-loop setting.
Read more6/12/2024

0
Antibody DomainBed: Out-of-Distribution Generalization in Therapeutic Protein Design
Natav{s}a Tagasovska, Ji Won Park, Matthieu Kirchmeyer, Nathan C. Frey, Andrew Martin Watkins, Aya Abdelsalam Ismail, Arian Rokkum Jamasb, Edith Lee, Tyler Bryson, Stephen Ra, Kyunghyun Cho
Machine learning (ML) has demonstrated significant promise in accelerating drug design. Active ML-guided optimization of therapeutic molecules typically relies on a surrogate model predicting the target property of interest. The model predictions are used to determine which designs to evaluate in the lab, and the model is updated on the new measurements to inform the next cycle of decisions. A key challenge is that the experimental feedback from each cycle inspires changes in the candidate proposal or experimental protocol for the next cycle, which lead to distribution shifts. To promote robustness to these shifts, we must account for them explicitly in the model training. We apply domain generalization (DG) methods to classify the stability of interactions between an antibody and antigen across five domains defined by design cycles. Our results suggest that foundational models and ensembling improve predictive performance on out-of-distribution domains. We publicly release our codebase extending the DG benchmark ``DomainBed,'' and the associated dataset of antibody sequences and structures emulating distribution shifts across design cycles.
Read more8/1/2024