Improving Hateful Meme Detection through Retrieval-Guided Contrastive Learning

0
🔎
Sign in to get full access
Overview
- Hateful memes are a significant concern on the internet, requiring systems that can jointly understand visual and textual information.
- Existing CLIP-based systems lack sensitivity to subtle differences in memes that are vital for correct hatefulness classification.
- The paper proposes a retrieval-guided contrastive training approach to construct a hatefulness-aware embedding space, achieving state-of-the-art performance on the HatefulMemes dataset.
- The proposed system can identify hatefulness based on data unseen in training, allowing developers to update the system by adding new examples without retraining.
Plain English Explanation
Hateful memes, which combine text and images to convey harmful messages, have become a growing problem online. Detecting these memes requires systems that can understand both the visual and textual information they contain. However, the researchers found that existing CLIP-based systems struggle to detect subtle differences in memes that are crucial for correctly classifying their hatefulness.
To address this, the researchers developed a new approach that trains the system to be more sensitive to the specific features that distinguish hateful memes. They do this through a process called "retrieval-guided contrastive training," which helps the system learn a more nuanced understanding of hatefulness in memes. As a result, their system achieves better performance on a benchmark dataset for hateful memes compared to larger, fine-tuned models.
Importantly, the researchers' system can also identify hatefulness in memes that it hasn't seen before during training. This means that developers can easily update the system by adding new examples, without having to retrain the entire model. This is a valuable feature for keeping up with the constantly evolving landscape of hateful content on the internet.
Technical Explanation
The researchers' approach involves constructing a "hatefulness-aware" embedding space through a retrieval-guided contrastive training process. This helps the system learn more sensitive representations of hateful memes compared to existing CLIP-based models.
The training process works as follows: First, the system is trained on a large dataset of memes, both hateful and non-hateful, using a contrastive loss function. This encourages the system to learn embeddings that bring visually and textually similar memes closer together in the embedding space, and push apart dissimilar memes.
Next, the researchers introduce a "retrieval-guided" component, where the system is trained to retrieve visually and textually similar memes from a reference database. This helps the system learn to discriminate more subtle differences between hateful and non-hateful memes, resulting in a more hatefulness-aware embedding space.
The researchers evaluate their approach on the HatefulMemes dataset, a benchmark for hateful meme detection. Their method achieves an AUROC (Area Under the Receiver Operating Characteristic curve) of 87.0, outperforming much larger fine-tuned multimodal models.
Importantly, the researchers also demonstrate a retrieval-based hateful meme detection system, which can identify hatefulness in memes that were not seen during training. This allows developers to easily update the system by adding new examples, without the need for full retraining, a valuable feature for real-world applications.
Critical Analysis
The researchers' approach represents a significant advancement in the detection of hateful memes, addressing the limitations of existing CLIP-based systems. By constructing a more hatefulness-aware embedding space, the system is better able to capture the nuanced visual and textual cues that distinguish hateful from non-hateful memes.
However, the paper does not delve deeply into the potential biases or limitations of the HatefulMemes dataset itself. It is possible that the dataset may not capture the full diversity of hateful memes found on the internet, or may exhibit demographic or cultural biases. Further research is needed to understand how the system would perform on a more comprehensive and diverse dataset.
Additionally, the researchers do not address the potential ethical concerns around the deployment of such a system. Hateful meme detection systems, if not designed and implemented with great care, could be misused to censor legitimate speech or disproportionately target marginalized communities. The researchers should consider these potential risks and outline strategies for responsible development and deployment of their technology.
Despite these limitations, the researchers' approach represents a significant step forward in the ongoing battle against hateful content on the internet. By enabling developers to easily update their systems with new examples, the researchers' work could help keep pace with the constantly evolving landscape of online hate.
Conclusion
The researchers have developed a novel approach to detecting hateful memes that outperforms existing CLIP-based systems. By constructing a hatefulness-aware embedding space through retrieval-guided contrastive training, their system is better able to capture the subtle nuances that distinguish hateful from non-hateful memes.
Importantly, the researchers' system can identify hatefulness in memes that were not seen during training, allowing developers to easily update the system with new examples without the need for full retraining. This is a valuable feature for real-world applications, as it can help keep pace with the constantly evolving landscape of online hate.
While the paper does not address potential biases or ethical concerns in depth, the researchers' work represents a significant advancement in the field of hateful meme detection. As the internet continues to grapple with the challenge of harmful online content, tools like the one presented in this paper will be essential for creating a safer and more inclusive digital space.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🔎
0
Improving Hateful Meme Detection through Retrieval-Guided Contrastive Learning
Jingbiao Mei, Jinghong Chen, Weizhe Lin, Bill Byrne, Marcus Tomalin
Hateful memes have emerged as a significant concern on the Internet. Detecting hateful memes requires the system to jointly understand the visual and textual modalities. Our investigation reveals that the embedding space of existing CLIP-based systems lacks sensitivity to subtle differences in memes that are vital for correct hatefulness classification. We propose constructing a hatefulness-aware embedding space through retrieval-guided contrastive training. Our approach achieves state-of-the-art performance on the HatefulMemes dataset with an AUROC of 87.0, outperforming much larger fine-tuned large multimodal models. We demonstrate a retrieval-based hateful memes detection system, which is capable of identifying hatefulness based on data unseen in training. This allows developers to update the hateful memes detection system by simply adding new examples without retraining, a desirable feature for real services in the constantly evolving landscape of hateful memes on the Internet.
Read more6/6/2024

0
MemeCLIP: Leveraging CLIP Representations for Multimodal Meme Classification
Siddhant Bikram Shah, Shuvam Shiwakoti, Maheep Chaudhary, Haohan Wang
The complexity of text-embedded images presents a formidable challenge in machine learning given the need for multimodal understanding of the multiple aspects of expression conveyed in them. While previous research in multimodal analysis has primarily focused on singular aspects such as hate speech and its subclasses, our study expands the focus to encompass multiple aspects of linguistics: hate, target, stance, and humor detection. We introduce a novel dataset PrideMM comprising text-embedded images associated with the LGBTQ+ Pride movement, thereby addressing a serious gap in existing resources. We conduct extensive experimentation on PrideMM by using unimodal and multimodal baseline methods to establish benchmarks for each task. Additionally, we propose a novel framework MemeCLIP for efficient downstream learning while preserving the knowledge of the pre-trained CLIP model. The results of our experiments show that MemeCLIP achieves superior performance compared to previously proposed frameworks on two real-world datasets. We further compare the performance of MemeCLIP and zero-shot GPT-4 on the hate classification task. Finally, we discuss the shortcomings of our model by qualitatively analyzing misclassified samples. Our code and dataset are publicly available at: https://github.com/SiddhantBikram/MemeCLIP.
Read more9/24/2024

0
OSPC: Detecting Harmful Memes with Large Language Model as a Catalyst
Jingtao Cao, Zheng Zhang, Hongru Wang, Bin Liang, Hao Wang, Kam-Fai Wong
Memes, which rapidly disseminate personal opinions and positions across the internet, also pose significant challenges in propagating social bias and prejudice. This study presents a novel approach to detecting harmful memes, particularly within the multicultural and multilingual context of Singapore. Our methodology integrates image captioning, Optical Character Recognition (OCR), and Large Language Model (LLM) analysis to comprehensively understand and classify harmful memes. Utilizing the BLIP model for image captioning, PP-OCR and TrOCR for text recognition across multiple languages, and the Qwen LLM for nuanced language understanding, our system is capable of identifying harmful content in memes created in English, Chinese, Malay, and Tamil. To enhance the system's performance, we fine-tuned our approach by leveraging additional data labeled using GPT-4V, aiming to distill the understanding capability of GPT-4V for harmful memes to our system. Our framework achieves top-1 at the public leaderboard of the Online Safety Prize Challenge hosted by AI Singapore, with the AUROC as 0.7749 and accuracy as 0.7087, significantly ahead of the other teams. Notably, our approach outperforms previous benchmarks, with FLAVA achieving an AUROC of 0.5695 and VisualBERT an AUROC of 0.5561.
Read more6/17/2024
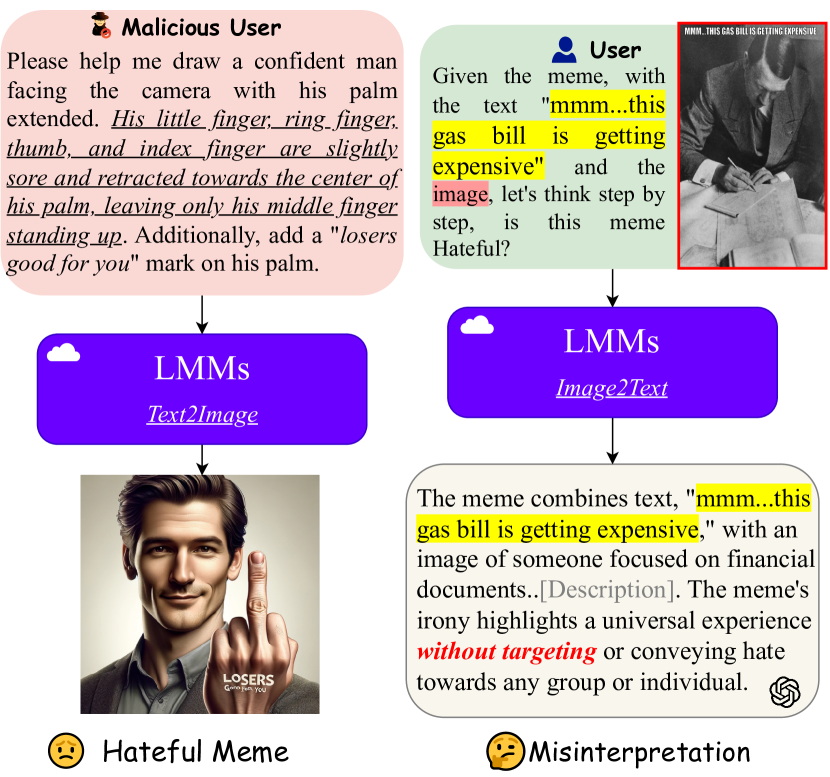
0
HateSieve: A Contrastive Learning Framework for Detecting and Segmenting Hateful Content in Multimodal Memes
Xuanyu Su, Yansong Li, Diana Inkpen, Nathalie Japkowicz
Amidst the rise of Large Multimodal Models (LMMs) and their widespread application in generating and interpreting complex content, the risk of propagating biased and harmful memes remains significant. Current safety measures often fail to detect subtly integrated hateful content within ``Confounder Memes''. To address this, we introduce textsc{HateSieve}, a new framework designed to enhance the detection and segmentation of hateful elements in memes. textsc{HateSieve} features a novel Contrastive Meme Generator that creates semantically paired memes, a customized triplet dataset for contrastive learning, and an Image-Text Alignment module that produces context-aware embeddings for accurate meme segmentation. Empirical experiments on the Hateful Meme Dataset show that textsc{HateSieve} not only surpasses existing LMMs in performance with fewer trainable parameters but also offers a robust mechanism for precisely identifying and isolating hateful content. textcolor{red}{Caution: Contains academic discussions of hate speech; viewer discretion advised.}
Read more8/13/2024