Improving Multi-Instance GPU Efficiency via Sub-Entry Sharing TLB Design

0
🔄
Sign in to get full access
Overview
- NVIDIA's Multi-Instance GPU (MIG) technology allows partitioning GPU computing power and memory into separate hardware instances, providing complete isolation.
- However, prior work has found that MIG does not extend to partitioning the last-level TLB (Translation Lookaside Buffer), which remains shared among all instances.
- NVIDIA GPUs have reorganized the TLB structure to improve address translation efficiency in MIG, but this has led to two main issues: performance degradation for co-running applications and underutilization of TLB sub-entries before eviction.
Plain English Explanation
NVIDIA's MIG technology enables dividing a single GPU into multiple, isolated instances that can be used independently. This is useful for running multiple applications on the same GPU without them interfering with each other. However, one component of the GPU, called the TLB, which helps with translating between virtual and physical memory addresses, is still shared among all the instances.
To address this, NVIDIA has changed the structure of the TLB on their GPUs. Now, each entry in the main TLB has 16 sub-entries, each corresponding to a different 64KB page of memory within a 1MB region. This should allow the TLB to be used more efficiently.
But the researchers found two problems with this approach: First, when multiple applications are running on the GPU at the same time, they can still interfere with each other's use of the shared TLB, leading to performance degradation. Second, the 16 sub-entries in each TLB entry are not being fully utilized before they are replaced, meaning the TLB is not being used as efficiently as it could be.
Technical Explanation
To enhance TLB reach, NVIDIA GPUs have reorganized the TLB structure with 16 sub-entries in each L3 TLB entry that have a one-to-one mapping to the address translations for 16 pages of size 64KB located within the same 1MB aligned range.
The researchers' comprehensive investigation of address translation efficiency in MIG identified two main issues caused by this L3 TLB sharing interference:
-
It results in performance degradation for co-running applications, as they compete for the shared TLB resources.
-
The TLB sub-entries are not fully utilized before eviction, meaning the TLB is not being used as efficiently as it could be.
Based on these observations, the researchers propose STAR, a technique to improve the utilization of TLB sub-entries. STAR dynamically adjusts whether TLB entries are shared or non-shared based on their sub-entry utilization, in order to optimize address translation storage and cater to current demand.
Critical Analysis
The researchers acknowledge that while their STAR technique improves overall performance by an average of 30.2% across various multi-tenant workloads, there may be further opportunities to enhance TLB utilization and address translation efficiency in the context of MIG.
One potential area for further research could be exploring alternative TLB structures or management policies that could provide more complete isolation between GPU instances, beyond just partitioning the main TLB entries. This could help mitigate the performance degradation issues identified when multiple applications compete for the shared TLB resources.
Additionally, the researchers' analysis is limited to the specific GPU architecture and TLB organization used by NVIDIA. It would be valuable to investigate how these findings and the proposed STAR technique might generalize to other GPU designs or even CPU architectures that also utilize TLBs for address translation.
Conclusion
In summary, this research highlights the challenges of efficiently managing address translation in GPU virtualization technologies like NVIDIA's MIG. The proposed STAR technique represents a step forward in improving TLB utilization and overall performance, but there remain opportunities to further enhance isolation and translation efficiency in these complex hardware systems. As GPU computing continues to grow in importance, addressing these fundamental architectural considerations will be crucial for enabling the next generation of high-performance, multi-tenant GPU workloads.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🔄
0
Improving Multi-Instance GPU Efficiency via Sub-Entry Sharing TLB Design
Bingyao Li, Yueqi Wang, Tianyu Wang, Lieven Eeckhout, Jun Yang, Aamer Jaleel, Xulong Tang
NVIDIA's Multi-Instance GPU (MIG) technology enables partitioning GPU computing power and memory into separate hardware instances, providing complete isolation including compute resources, caches, and memory. However, prior work identifies that MIG does not extend to partitioning the last-level TLB (i.e., L3 TLB), which remains shared among all instances. To enhance TLB reach, NVIDIA GPUs reorganized the TLB structure with 16 sub-entries in each L3 TLB entry that have a one-to-one mapping to the address translations for 16 pages of size 64KB located within the same 1MB aligned range. Our comprehensive investigation of address translation efficiency in MIG identifies two main issues caused by L3 TLB sharing interference: (i) it results in performance degradation for co-running applications, and (ii) TLB sub-entries are not fully utilized before eviction. Based on this observation, we propose STAR to improve the utilization of TLB sub-entries through dynamic sharing of TLB entries across multiple base addresses. STAR evaluates TLB entries based on their sub-entry utilization to optimize address translation storage, dynamically adjusting between a shared and non-shared status to cater to current demand. We show that STAR improves overall performance by an average of 30.2% across various multi-tenant workloads.
Read more4/30/2024
💬
0
Improving GPU Multi-Tenancy Through Dynamic Multi-Instance GPU Reconfiguration
Tianyu Wang, Sheng Li, Bingyao Li, Yue Dai, Ao Li, Geng Yuan, Yufei Ding, Youtao Zhang, Xulong Tang
Continuous learning (CL) has emerged as one of the most popular deep learning paradigms deployed in modern cloud GPUs. Specifically, CL has the capability to continuously update the model parameters (through model retraining) and use the updated model (if available) to serve overtime arriving inference requests. It is generally beneficial to co-locate the retraining and inference together to enable timely model updates and avoid model transfer overheads. This brings the need for GPU sharing among retraining and inferences. Meanwhile, multiple CL workloads can share the modern GPUs in the cloud, leading to multi-tenancy execution. In this paper, we observe that prior GPU-sharing techniques are not optimized for multi-tenancy CL workloads. Specifically, they do not coherently consider the accuracy of the retraining model and the inference service level objective (SLO) attainment. Moreover, they cannot accommodate the overtime dynamics (e.g., inference arrival intensity) in CL execution. In this paper, we propose MIGRator, a novel GPU reconfiguration runtime that dynamically performs GPU reconfiguration for multi-tenancy CL workloads. MIGRator is based on the recent NVIDIA multi-instance GPU (MIG) to mitigate resource contention and formulates the reconfiguration optimization into Integer Linear Programming (ILP) to dynamically identify, reconfigure, and allocate the GPU instances. MIGRator leverages the Goodput metric in the ILP objective function to consider both inference SLO attainment and model accuracy in the reconfiguration exploration. We evaluate MIGRator using representative multi-tenancy CL workloads. The results show our approach outperforms the state-of-the-art GPU sharing techniques (i.e., Ekya, Astraea, and PARIS) by 17%, 21%, and 20%, respectively.
Read more7/19/2024
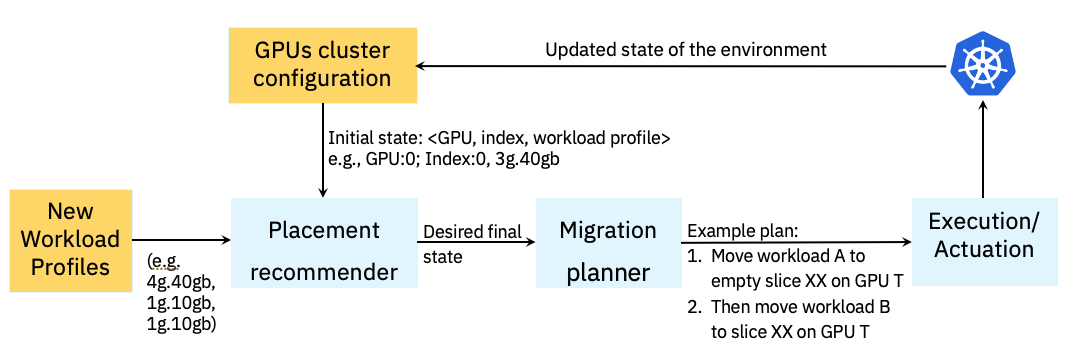
0
Optimal Workload Placement on Multi-Instance GPUs
Bekir Turkkan, Pavankumar Murali, Pavithra Harsha, Rohan Arora, Gerard Vanloo, Chandra Narayanaswami
There is an urgent and pressing need to optimize usage of Graphical Processing Units (GPUs), which have arguably become one of the most expensive and sought after IT resources. To help with this goal, several of the current generation of GPUs support a partitioning feature, called Multi-Instance GPU (MIG) to allow multiple workloads to share a GPU, albeit with some constraints. In this paper we investigate how to optimize the placement of Large Language Model (LLM)-based AI Inferencing workloads on GPUs. We first identify and present several use cases that are encountered in practice that require workloads to be efficiently placed or migrated to other GPUs to make room for incoming workloads. The overarching goal is to use as few GPUs as possible and to further minimize memory and compute wastage on GPUs that are utilized. We have developed two approaches to address this problem: an optimization method and a heuristic method. We benchmark these with two workload scheduling heuristics for multiple use cases. Our results show up to 2.85x improvement in the number of GPUs used and up to 70% reduction in GPU wastage over baseline heuristics. We plan to enable the SRE community to leverage our proposed method in production environments.
Read more9/11/2024
🤯
0
Missile: Fine-Grained, Hardware-Level GPU Resource Isolation for Multi-Tenant DNN Inference
Yongkang Zhang, Haoxuan Yu, Chenxia Han, Cheng Wang, Baotong Lu, Yang Li, Xiaowen Chu, Huaicheng Li
Colocating high-priority, latency-sensitive (LS) and low-priority, best-effort (BE) DNN inference services reduces the total cost of ownership (TCO) of GPU clusters. Limited by bottlenecks such as VRAM channel conflicts and PCIe bus contentions, existing GPU sharing solutions are unable to avoid resource conflicts among concurrently executing tasks, failing to achieve both low latency for LS tasks and high throughput for BE tasks. To bridge this gap, this paper presents Missile, a general GPU sharing solution for multi-tenant DNN inference on NVIDIA GPUs. Missile approximates fine-grained GPU hardware resource isolation between multiple LS and BE DNN tasks at software level. Through comprehensive reverse engineering, Missile first reveals a general VRAM channel hash mapping architecture of NVIDIA GPUs and eliminates VRAM channel conflicts using software-level cache coloring. It also isolates the PCIe bus and fairly allocates PCIe bandwidth using completely fair scheduler. We evaluate 12 mainstream DNNs with synthetic and real-world workloads on four GPUs. The results show that compared to the state-of-the-art GPU sharing solutions, Missile reduces tail latency for LS services by up to ~50%, achieves up to 6.1x BE job throughput, and allocates PCIe bus bandwidth to tenants on-demand for optimal performance.
Read more7/30/2024